












业务背景
今天给大家分享一下我们在公司里,面向多个业务团队设计的数据中心架构,他是如何一步一步的从多业务团队数据现状分析开始,然后逐步的演化设计出一个数据中心架构来的,希望能帮助大家对现在很流行的数据中心这个概念构建起来系统化的认知。
首先跟大家说一下在没有数据中心的时候,公司里的各个业务团队是什么样的一个状况,简单来说,就是不同的业务团队有有研发自己的业务系统,有自己独立的数据存储,平时就是自己的系统访问自己的数据就够了。
如下图 1 所示:
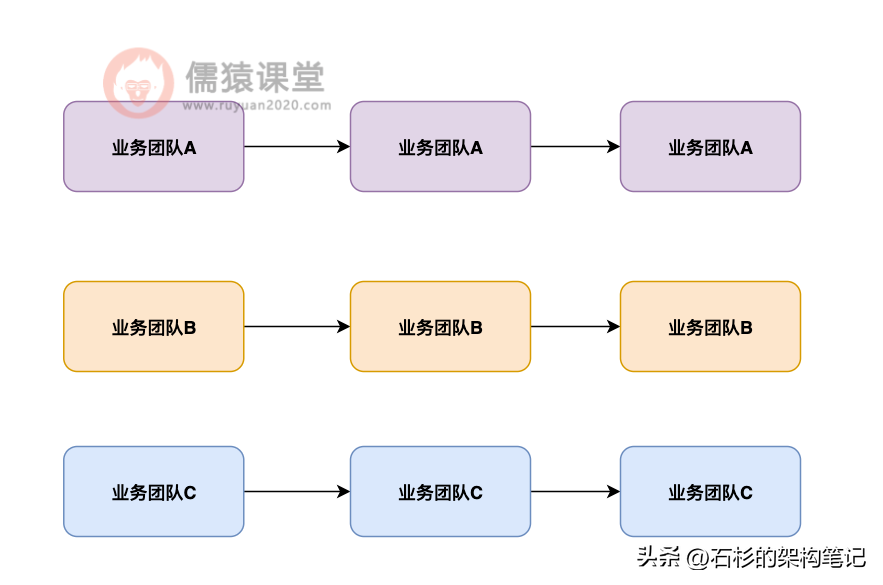
没引入多业务数据中心时的痛点
但是接着随着你的系统逐步演进,需求越来越多,越来越复杂,逐步的会出现每个系统都需要访问其他系统的数据的情况。
此时就会出现你每个系统必须开一些数据接口,让别的系统来调用你的接口访问你的数据,同时你自己也可能要访问别人的接口去获取别人的数据。
如下图 2 所示:
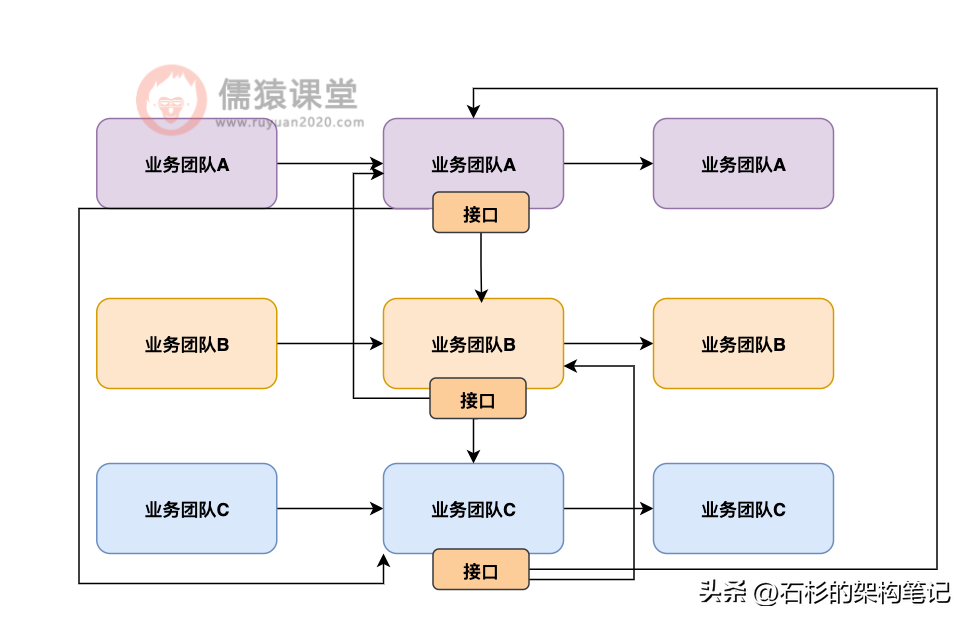
大家看到上图是什么感觉?是不是觉得很懵逼?因为实际上随着系统慢慢演化,可能会搞成系统 A 开的接口被系统 B 和 C 调用,系统 B 开的接口被系统 A 和 C 调用,系统 C 开的接口被系统 A 和 B 调用。
这个时候就会出现非常尴尬的场景,就是混乱,没错,我敢打赌,你盯着上面的图看 10s,应该还是很懵逼,没什么头绪。
没错,所以其实这就是最大的痛点,各个业务系统其实都是一个数据孤岛,也就是大家都只能访问到自己的数据,然后别人要访问你的数据,必须通过你的接口来访问,最后导致 n 个业务系统之间错综复杂的调用关系,进而导致系统不好维护,运维困难。
数据中心的架构设计思想
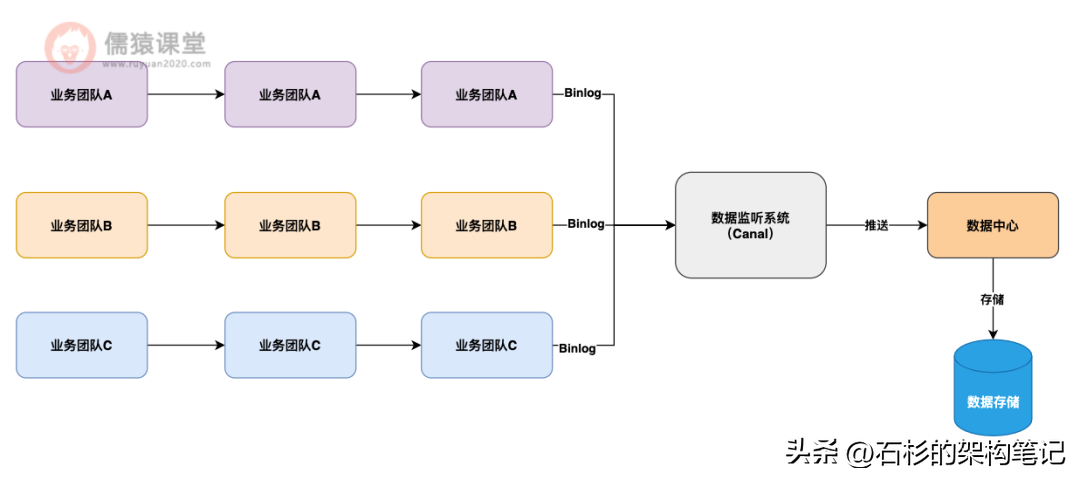
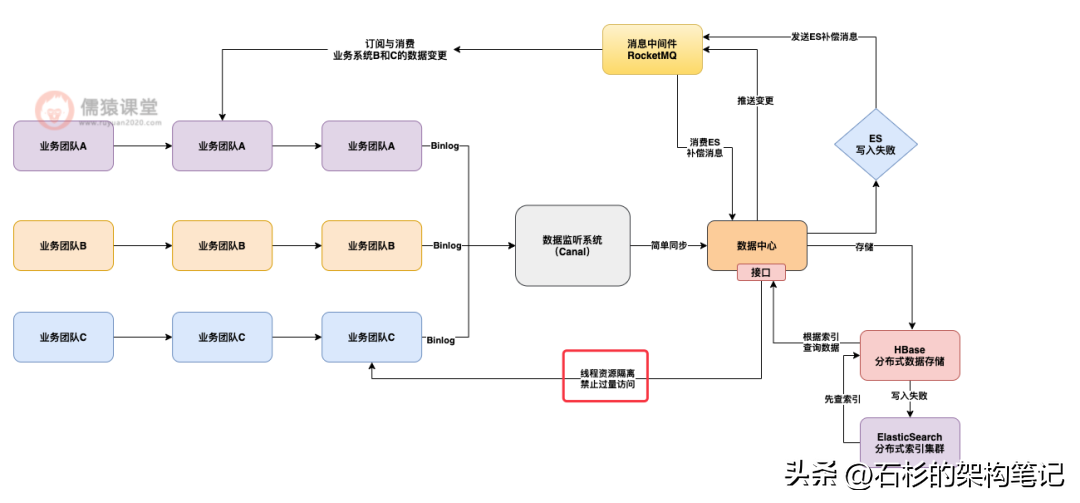
所以这个问题,我们设计了一个面向多业务团队的数据中心,这个数据中心的架构设计思想,就是通过各个业务系统的数据存储的变更监听。
比如针对 MySQL 数据库就可以部署 Canal 来监听他的数据变更,然后把各个业务系统的数据都拉取到数据中台里统一存储。
如下图 3 所示:
接着数据中心可以提供两种数据访问模式,一个是主动查询接口,一个是被动监听 MQ 通知。
也就是说,对于数据中心来说,你各个业务系统都可以调用数据中心的接口,直接获取你想要的其他业务系统的数据,同时数据中心也会把各个业务数据的变更通知发送到 MQ,你也可以订阅你感兴趣的业务数据变更通知。
如下图 4 所示:
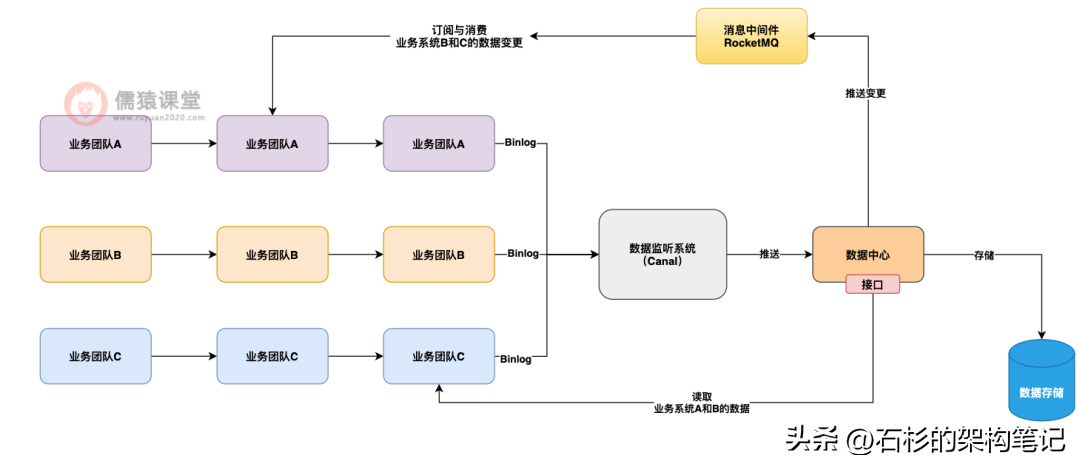
大家看到上面的架构设计图,是不是瞬间感觉世界一下子就清净了?
没错,其实在互联网公司里,对于多业务系统错综复杂的互相调用接口访问对方数据,往往会抽出一个统一的公共的数据中心来,让各个业务系统实现数据共享,这样就可以大幅度的提升我们系统整体架构的整洁性了。
数据中心的数据存储架构设计
那么再来给大家讲一下数据中心架构设计的另外一个关键点,就是他的数据存储架构设计。
大家可以想一下,虽然我们的各个业务系统的数据存储基本都是以 MySQL 为主的,但是我们的数据中心的存储架构其实跟业务系统的需求是不同的,因为业务系统一般都是需要利用 MySQL 的事务机制实现复杂的业务逻辑。
但是对于我们数据中心来说,本质仅仅是将数据同步过来,然后后续的重点是对外提供查询。
这是功能上定位的不同,另外一个不同就是数据量级的不同,因为我们的数据中心是存储所有业务系统的全量数据的,所以这就导致了可能各个业务系统的数据量级是百万级到亿级,而我们的数据中心他的数据量级可能是百亿级的,这是很大的一个特点。
如下图 5 所示:
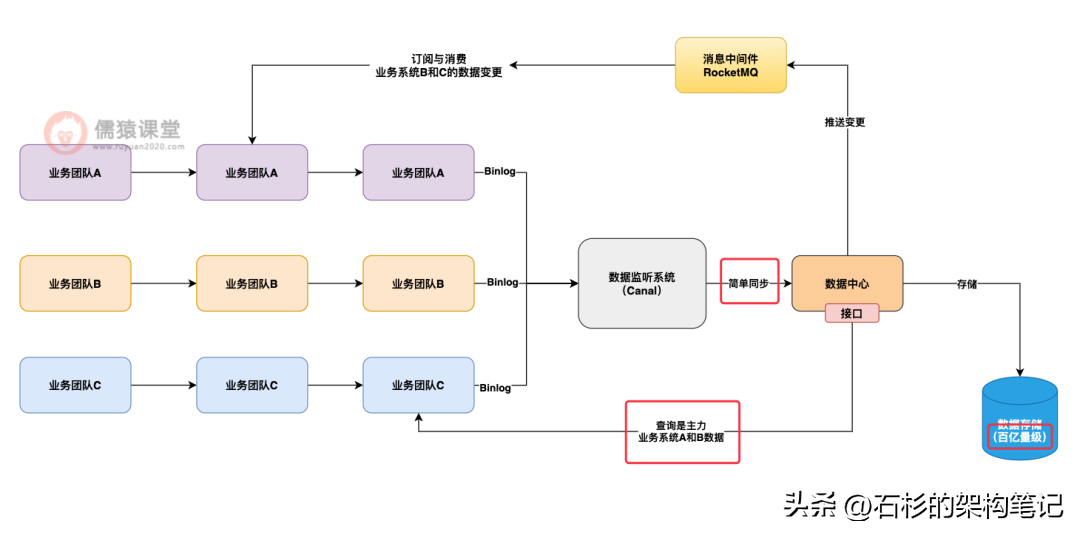
所以最终我们的数据中心存储架构采用的是 HBase+Elasticsearch 作为核心架构。
也就是说,基于 HBase 把数据以 kv 的格式分布式的存储在多台服务器上,写入的时候是 kv 格式,读取的时候也是 kv 格式,key 就是数据的主键 id,value 就是一行完整的数据。
同时会为各个查询接口的查询条件,把要查询的字段值写入 ES 里建立查询索引,让查询接口可以基于 ES 中的索引先搜索数据主键 id,然后根据数据主键 id 去 HBase 里查询完整的一行数据。
如下图 6 所示:
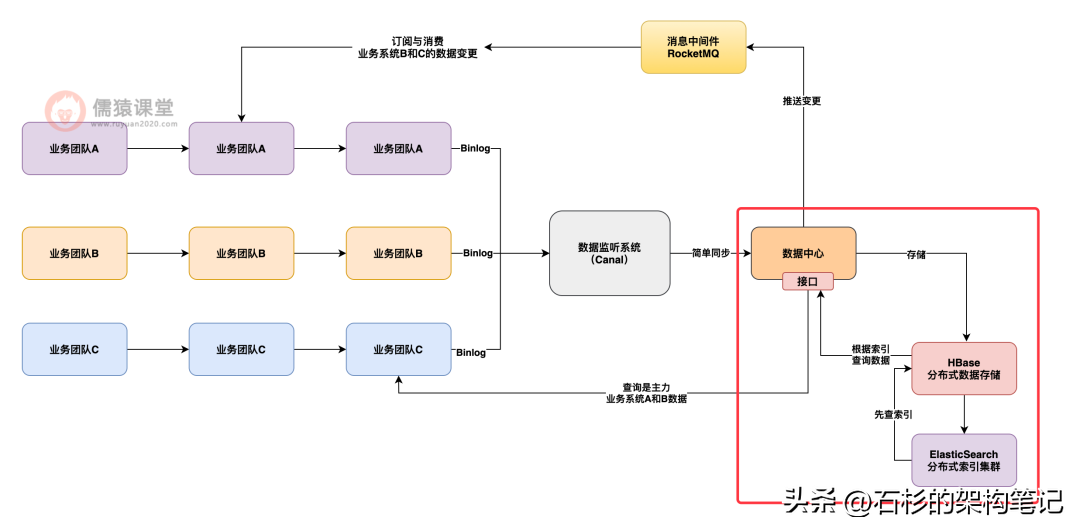
接下来给大家说一下这套架构下的一些技术难点和问题:
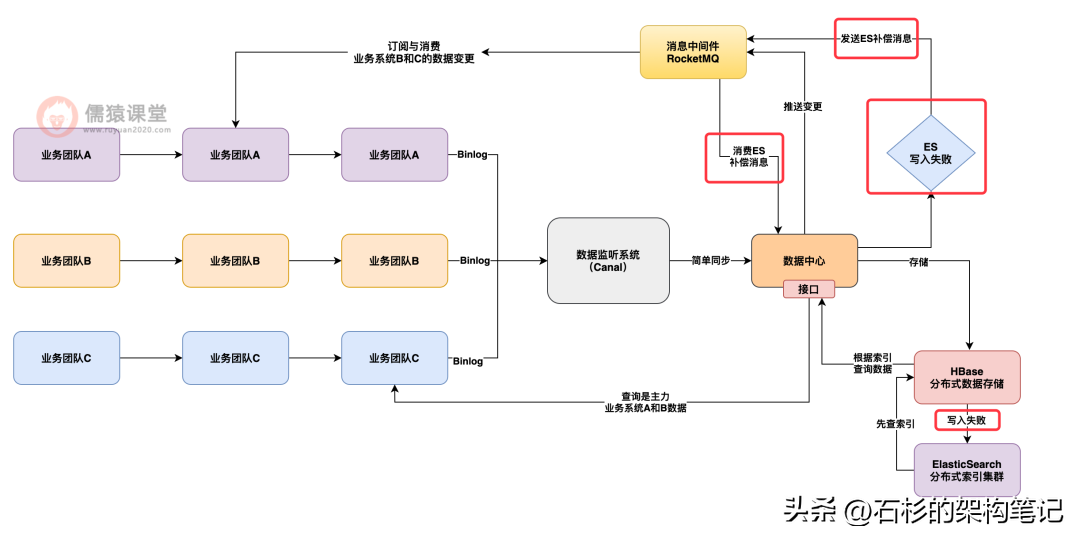
一个是 Hbase 和 ES 之间的一致性问题如何保证,也就是说,万一写入 Hbase 成功了,结果写入 ES 失败了,此时应该怎么办?
这个时候其实应该设计一个补偿机制,也就是说,写入 Hbase 成功,而写入 ES 失败的时候,需要发一个补偿消息到 MQ 里去,然后下次再重试做一个写入,实现最终一致性的效果。
如下图 7 所示:
另外一个比较关键的生产架构经验就是多业务资源隔离,也就是要限制每个业务方对数据中台接口的访问量。
否则可能会出现一个问题,就是某个业务方因为自身业务激增或者是业务 bug,导致读数据局中心的接口进行了瞬时高并发访问,一下子就把数据中心的请求处理线程都打满了,接着就没法处理别的业务系统的查询请求了。
如下图 8 所示:
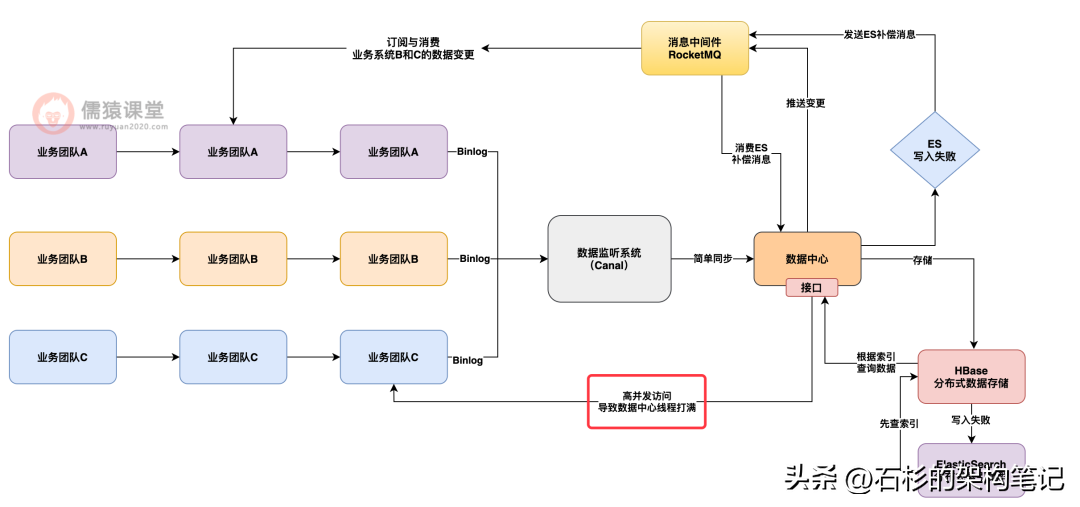
所以说往往在这种情况下,我们必须在数据中心里设计多业务资源隔离的机制,就是说让每个业务系统接入接口访问的时候,最多就是使用数据中心里一部分的线程资源,超过这个阈值,就会限流,不允许这个业务方过量访问。
如下图 9 所示:
数据中心的离线数据备份和恢复的机制
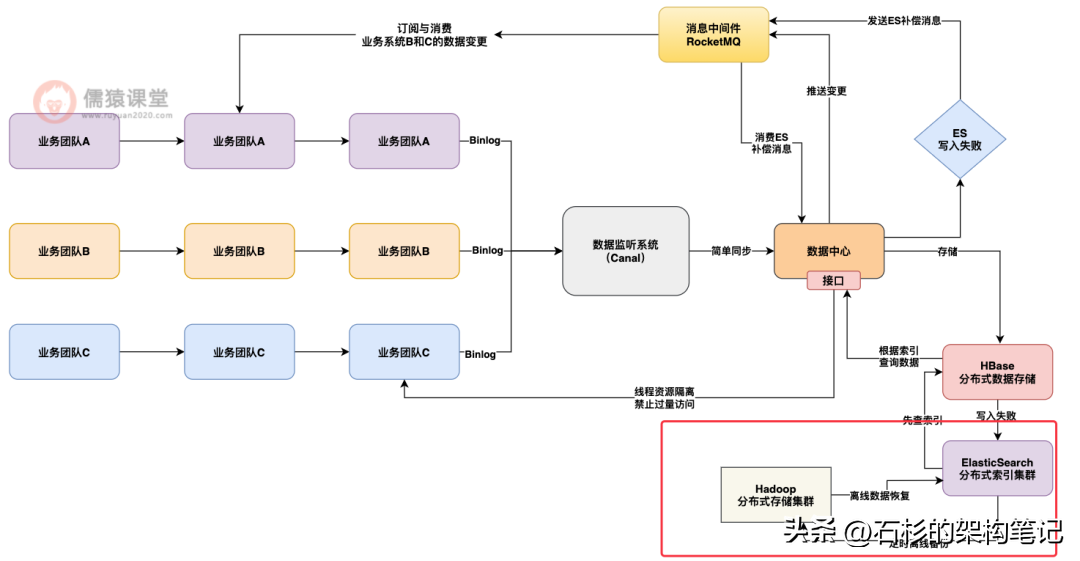
接着我们还有另外一个重要的架构方案设计,数据中心现在是极为重要的是数据存储,因为所有业务系统的数据都会在数据中心内部进行汇总存储,然后各个业务系统都会强依赖数据中心提供的所有数据。
所以如果数据中心要是出现数据存储故障甚至是数据丢失一类的问题,那就会导致很大的麻烦,因此我们设计了离线数据备份和恢复的机制。
也就是说,基于大数据技术将所有数据定时同步一份到 Hadoop 集群中去,如果要是出现了 Hbase 或者 ES 集群的崩溃或者数据丢失,此时可以基于 Hadoop 集群中的离线备份数据,把数据恢复到某个时间点,继续对外提供服务。
如下图 10 所示:
总结
好了,今天给大家分享的一个互联网公司的多业务系统数据中心架构设计就到这里了,希望大家看了我们的架构设计思路之后,未来在公司里遇到类似问题的时候,能够有一个整体的设计和解决思路。






















