
探究Presto SQL引擎 系列:第1篇《探究Presto SQL引擎(1)-巧用Antlr》介绍了Antlr的基本用法以及如何使用Antlr4实现解析SQL查询CSV数据,在第2篇《探究Presto SQL引擎(2)-浅析Join》结合了Join的原理,以及Join的原理,在Presto中的思路。
本文是系列第3篇,介绍基于 Antlr 实现where条件的解析原理,并对比了直接解析与代码生成实现两种实现思路的性能,经实验基于代码生成的实现相比直接解析有 3 倍的性能提升。
一、背景问题
业务开发过程中,使用SQL进行数据筛选(where关键词)和关联(join关键词)是编写SQL语句实现业务需求最常见、最基础的能力。
在海量数据和响应时间双重压力下,看似简单的数据筛选和关联在实现过程中面临非常多技术细节问题,在研究解决这些问题过程中也诞生了非常有趣的数据结构和优化思想。比如B树、LSM树、列式存储、动态代码生成等。
对于Presto SQL引擎,布尔表达式的判断是实现where和join处理逻辑中非常基础的能力。
本文旨在探究 where 关键词的实现思路,探究where语句内部实现的基本思路以及性能优化的基本思想。以where语句为例:where筛选支持and 、or 和 not 三种基础逻辑,在三种基础逻辑的基础上,支持基于括号自定义优先级、表达式内部支持字段、函数调用。看似简单,实则别有洞天。值得深入挖掘学习。
二、使用 Antlr 实现 where 条件过滤
对于Presto查询引擎,其整体架构如下:
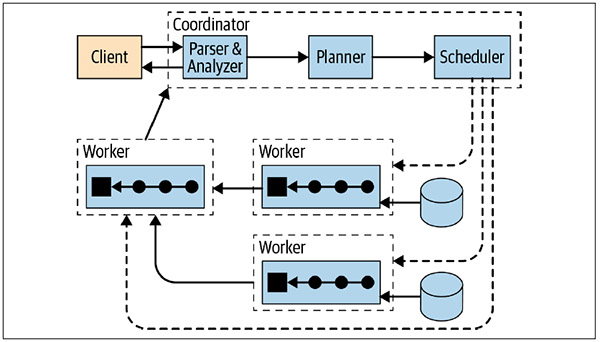
其中,Parser&Analyzer就是Antlr的用武之地。任何的SQL语句,必须经过Parser&Analyzer这一步,所谓一夫当关万夫莫开。关于Antlr的背景及基础操作等内容,在《探究Antlr在Presto 引擎的应用》一文已有描述,不再赘述。
本文依然采用驱动Antlr的三板斧来实现SQL语句对where条件的支持。
对于where条件,首先拆解where条件最简单的结构:
- and 和or作为组合条件筛选的基本结构。
- 6大比较运算符(大于,小于,等于,不等于,大于或等于,小于或等于)作为基本表达式。
接下来就是使用 Antlr 的标准流程。
2.1 定义语法规则
使用antlr定义语法规则如下 (该规则基于presto SQL语法裁剪,完整定义可参考presto SelectBase.g4文件):
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
(WHERE where=booleanExpression)?
;
...
booleanExpression
: valueExpression predicate[$valueExpression.ctx]? #predicated
| NOT booleanExpression #logicalNot
| left=booleanExpression operator=AND right=booleanExpression #logicalBinary
| left=booleanExpression operator=OR right=booleanExpression #logicalBinary
;
predicate[ParserRuleContext value]
: comparisonOperator right=valueExpression #comparison
;
即where条件后面附带一个booleanExpression表达式规则,booleanExpression表达式规则支持基础的valueExpression预测、and和or以及not条件组合。本文的目的是探索核心思路,而非实现一个完成的SQL筛选能力,所以只处理and和or条件即可,以实现删繁就简,聚焦核心问题的目的。
2.2 生成语法解析代码
参照 Antlr 的官方文档,使用预处理好的 Antlr命令处理g4文件,生成代码即可。
antlr4 -package org.example.antlr -no-listener -visitor .\SqlBase.g4
2.3 开发业务代码处理 AST
2.3.1 定义语法树节点
在了解了表达式构成后,先定义两个基础的SQL语法树节点,类图如下:
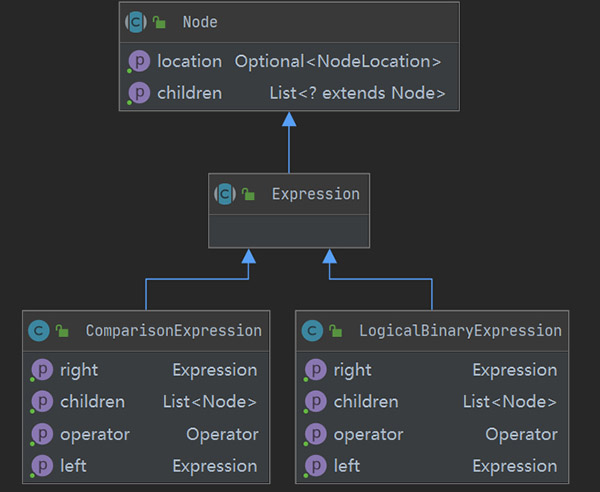
这两个类从结构上是同构的:左右各一个分支表达式,中间一个运算符。
2.3.2 构建语法树
在AstBuilder实现中,新增对logicalBinary, comparison相关语法的解析实现。这些工作都是依样画葫芦,没有什么难度。
@Override
public Node visitComparison(Select1Parser.ComparisonContext context)
{
return new ComparisonExpression(
getLocation(context.comparisonOperator()),
getComparisonOperator(((TerminalNode) context.comparisonOperator().getChild(0)).getSymbol()),
(Expression) visit(context.value),
(Expression) visit(context.right));
}
@Override
public Node visitLogicalBinary(Select1Parser.LogicalBinaryContext context)
{
return new LogicalBinaryExpression(
getLocation(context.operator),
getLogicalBinaryOperator(context.operator),
(Expression) visit(context.left),
(Expression) visit(context.right));
}
通过上面的两步,一个SQL表达式就能转化成一个SQL语法树了。
2.3.3 遍历语法树
有了SQL语法树后,问题就自然而然浮现出来了:
- a) 这个SQL语法树结构有什么用?
- b) 这个SQL语法树结构该怎么用?
其实对于SQL语法树的应用场景,排除SQL引擎内部的逻辑,在我们日常开发中也是很常见的。比如:SQL语句的格式化,SQL的拼写检查。
对于SQL语法树该怎么用的问题,可以通过一个简单的例子来说说明:SQL语句格式化。
在《探究Antlr在Presto 引擎的应用》一文中,为了简化问题采取了直接拆解antlr生成的AST获取SQL语句中的表名称和字段名称,处理方式非常简单粗暴。实际上presto中有一种更为优雅的处理思路:AstVisitor。也就是设计模式中的访问者模式。
访问者模式定义如下:
- 封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新的操作。
这个定义落实到SQL语法树结构实现要点如下:即SQL语法树节点定义一个accept方法作为节点操作的入口(参考Node.accept()方法)。定义个AstVisitor类用于规范访问节点树的操作,具体的实现类继承AstVisitor即可。基础结构定义好过后,后面就是万变不离其宗了。
两个类核心框架代码如下:
public abstract class Node{
{
/**
* Accessible for {@link AstVisitor}, use {@link AstVisitor#process(Node, Object)} instead.
*/
protected <R, C> R accept(AstVisitor<R, C> visitor, C context)
{
return visitor.visitNode(this, context);
}
}
public abstract class AstVisitor<R, C>
{
protected R visitStatement(Statement node, C context)
{
return visitNode(node, context);
}
protected R visitQuery(Query node, C context)
{
return visitStatement(node, context);
}
....
}例如最常见的select * from table where 这类SQL语法,在SelectBase.g4文件中定义查询的核心结构如下:
querySpecification
: SELECT setQuantifier? selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
(WHERE where=booleanExpression)?
(GROUP BY groupBy)?
(HAVING having=booleanExpression)?
;
以格式化SQL语句为例,Presto实现了SqlFormatter和ExpressionFormatter两个实现类。格式化这个语句的代码如下:
@Override
protected Void visitQuerySpecification(QuerySpecification node, Integer indent)
{
process(node.getSelect(), indent);
if (node.getFrom().isPresent()) {
append(indent, "FROM");
builder.append('\n');
append(indent, " ");
process(node.getFrom().get(), indent);
}
builder.append('\n');
if (node.getWhere().isPresent()) {
append(indent, "WHERE " + formatExpression(node.getWhere().get(), parameters))
.append('\n');
}
if (node.getGroupBy().isPresent()) {
append(indent, "GROUP BY " + (node.getGroupBy().get().isDistinct() ? " DISTINCT " : "") + formatGroupBy(node.getGroupBy().get().getGroupingElements())).append('\n');
}
if (node.getHaving().isPresent()) {
append(indent, "HAVING " + formatExpression(node.getHaving().get(), parameters))
.append('\n');
}
if (node.getOrderBy().isPresent()) {
process(node.getOrderBy().get(), indent);
}
if (node.getLimit().isPresent()) {
append(indent, "LIMIT " + node.getLimit().get())
.append('\n');
}
return null;
}
代码实现逻辑清晰明了,可读性极强。
同理, 实现where条件解析的核心在于比较条件表达式的处理(visitComparisonExpression)和逻辑条件表达式的处理(visitLogicalBinaryExpression)。同样出于聚焦核心流程的考虑,我们只实现类似于a > 0 or b < 10 这种整型字段的过滤。
对于and和or结构,由于是树形结构,所以会用到递归,即优先处理叶子节点再以层层向上汇总。处理处理逻辑如下代码所示:
/**
• 处理比较表达式
• @param node
• @param context
• @return
*/
@Override
protected Void visitComparisonExpression(ComparisonExpression node, Map<String,Long> context) {
Expression left = node.getLeft();
Expression right = node.getRight();
String leftKey = ((Identifier) left).getValue();
Long rightKey = ((LongLiteral) right).getValue();
Long leftVal = context.get(leftKey);
if(leftVal == null){
stack.push(false);
}
ComparisonExpression.Operator op = node.getOperator();
switch (op){
case EQUAL:
stack.push(leftVal.equals(rightKey));break;
case LESS_THAN:
stack.push( leftVal < rightKey);;break;
case NOT_EQUAL:
stack.push( !leftVal.equals(rightKey));break;
case GREATER_THAN:
stack.push( leftVal>rightKey);break;
case LESS_THAN_OR_EQUAL:
stack.push( leftVal<=rightKey);break;
case GREATER_THAN_OR_EQUAL:
stack.push( leftVal>=rightKey);break;
case IS_DISTINCT_FROM:
default:
throw new UnsupportedOperationException("not supported");
}
return null;
}
这里的实现非常简单,基于栈存储叶子节点(ComparisonExpression )计算的结果,递归回溯非叶子节点(LogicalBinaryExpression )时从栈中取出栈顶的值,进行and和or的运算。说明一下:其实递归的实现方式是可以不使用栈,直接返回值即可。这里基于栈实现是为了跟下文代码生成的逻辑从结构上保持一致,方便对比性能。
2.4 验证表达式执行
为了验证上述方案执行结果,定义一个简单的过滤规则,生成随机数验证能否实现对表达式逻辑的判断。
// antlr处理表达式语句,生成Expression对象
SqlParser sqlParser = new SqlParser();
Expression expression = sqlParser.createExpression("a>1 and b<2");
// 基于AstVisitor实现
WhereExpFilter rowFilter = new WhereExpFilter(expression);
Random r = new Random();
for(int i=0;i<10;i++){
Map<String,Long> row = new HashMap<>();
row.put("a", (long) r.nextInt(10));
row.put("b", (long) r.nextInt(10));
System.out.println("exp: a>1 and b<2, param:"+row+", ret:"+rowFilter.filter(row));
}
// ====== 执行结果如下
/**
exp: a>1 and b<2, param:{a=9, b=8}, ret:false
exp: a>1 and b<2, param:{a=7, b=3}, ret:false
exp: a>1 and b<2, param:{a=0, b=7}, ret:false
exp: a>1 and b<2, param:{a=6, b=0}, ret:true
exp: a>1 and b<2, param:{a=2, b=0}, ret:true
exp: a>1 and b<2, param:{a=9, b=0}, ret:true
exp: a>1 and b<2, param:{a=3, b=6}, ret:false
exp: a>1 and b<2, param:{a=8, b=7}, ret:false
exp: a>1 and b<2, param:{a=6, b=1}, ret:true
exp: a>1 and b<2, param:{a=4, b=6}, ret:false
*/
通过上述的处理流程以及执行结果的验证,可以确定基于Antlr可以非常简单实现where条件的过滤,这跟antlr实现四则运算能力有异曲同工之妙。但是通过对Presto源码及相关文档阅读,却发现实际上对于条件过滤及JOIN的实现是另辟蹊径。这是为什么呢?
三、基于 AstVisitor 直接解析 SQL 条件问题
在解答Presto的实现思路之前,需要先铺垫两个基础的知识。一个是CPU的流水线和分支预测,另一个是JVM的方法内联优化。
3.1 CPU流水线和分支预测
计算机组成原理中关于CPU指令的执行,如下图所示:

即在早期CPU执行指令采用串行的方式,为了提升CPU的吞吐量,在RISC的架构中通过流水线的方式实现了多条指令重叠进行操作的一种准并行处理实现技术。通过上面的图示,可以看出:增加一条流水后,单位时间执行的指令数量就翻倍,即性能提升了1倍。
当然这是理想的情况,现实中会遇到两类问题:
- 1)下一条指令的执行依赖上一条指令执行的结果。
- 2)遇到分支必须等条件计算完成才知道分支是否执行。
对于问题1,通过乱序执行的方法能够将性能提升20%~30%。对于问题2,则是通过分支预测的方法来应对。
关于利用分支预测原理提升性能,有两个有意思的案例。
案例1:
stackoverflow上有个著名的问题:why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array。即对于有序数组和无序数组的遍历,执行时间差不多有2~3倍的差距。
在笔者的计算机上,运行案例结果符合描述。需要注意的是用system.nanotime()来衡量,system.currenttimemillis()精度不够。
案例2:
Dubbo源码ChannelEventRunnable中通过将switch代码优化成if获得了近似2倍的效率提升。
简单总结一下,代码中的分支逻辑会影响性能,通过一些优化处理(比如数据排序/热点代码前置)能够提升分支预测的成功率,从而提升程序执行的效率。
3.2 JVM 方法内联优化
JVM是基于栈的指令执行策略。一个函数调用除了执行自身逻辑的开销外,还有函数执行上下文信息维护的额外开销,例如:栈帧的生成、参数字段入栈、栈帧的弹出、指令执行地址的跳转。JVM内联优化对于性能的影响非常大。
这里有一个小实验,对于同一段代码正常执行和禁用内联优化(-XX:CompileCommand=dontinline,
test/TestInline.addOp), 其性能差距差不多有6倍。
代码样例及数据如下:
public class TestInline {
public int addOp(int a,int b){
return a+b;
}
@Benchmark
public int testAdd(){
int sum=0;
for(int i=0;i<100000;i++){
sum=addOp(sum,i);
}
return sum;
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.warmupIterations(2).measurementIterations(2)
.forks(1).build();
new Runner(options).run();
}
}
// 执行结果如下:
/**
Benchmark Mode Cnt Score Error Units
TestInline.testAdd thrpt 2 18588.318 ops/s(正常执行)
TestInline.testAdd thrpt 2 3131.466 ops/s(禁用内联)
**/对于Java语言,方法内联优化也是有成本的。所以,通常热点代码/方法体较小的代码/用private、static、final修饰的代码才可能内联。过大的方法体和面向对象的继承和多态都会影响方法的内联,从而影响性能。
对于SQL 执行引擎中最常见的where和join语句来说,由于执行过程中需要判断数据类型、操作符类型,几乎每行数据的处理都是在影响CPU的分支预测,而且每个数据类型,每种操作符都都需要封装独立的处理逻辑。如果采用直接解析SQL语句的方式,势必对分支预测和方法内联影响极大。为了提升性能,降低分支预测失败和方法调用的开销,动态代码生成的方案就横空出世了。
四、基于动态代码生成实现 where 条件过滤
在介绍使用动态代码生成实现where条件过滤前,有必要对字节码生成技术的产生背景,Java语言特有的优势以及相关的基本操作进行介绍。
4.1 字节码生成的方法
Java虚拟机规范有两个关键点:平台无关性和语言无关性。
平台无关性实现了一次编写,到处运行的目标,。即不受限于操作系统是Windows还是Linux。
语言无关性使得JVM上面运行的语言不限于Java, 像Groovy, Scala,JRuby 都成为了JVM生态的一部分。而能够实现平台无关性和语言无关性的的基础就是基于栈执行指令的虚拟机和字节码存储技术。

对于任意一门编程语言:程序分析、程序生成、程序转换技术在开发中应用广泛,通常应用在如下的场景中:
程序分析:基于语法和语义分析,识别潜在的bug和无用代码,或者进行逆向工程,研究软件内部原理(比如软件破解或开发爬虫)
程序生成:比如传统的编译器、用于分布式系统的stub或skeleton编译器或者JIT编译器等。
程序转换: 优化或者混淆代码、插入调试代码、性能监控等。
对于Java编程语言,由于有Java源码-字节码-机器码三个层级,所以程序分析、程序生成、程序转换的技术落地可以有两个切入点:Java源码或者编译后的Class。选择编译后的Class字节码有如下的优势:
无需源码。这对于闭源的商业软件也能非常方便实现跨平台的性能监控等需求。
运行时分析、生成、转换。只要在class字节码被加载到虚拟机之前处理完就可以了,这样整个处理流程就对用户透明了。
程序生成技术在Java中通常有另一个名字:字节码生成技术。这也表明了Java语言选择的切入点是编译后的Class字节码。
字节码生成技术在Java技术栈中应用也非常广泛,比如:Spring项目的AOP,各种ORM框架,Tomcat的热部署等场景。Java有许多字节码操作框架,典型的有asm和javassist、bytebuddy、jnif等。
通常出于性能的考量asm用得更为广泛。直接使用asm需要理解JVM的指令,对用户来说学习门槛比较高。Facebook基于asm进行了一层封装,就是airlift.bytecode工具了。基于该工具提供的动态代码生成也是presto性能保障的一大利器。用户使用airlift.bytecode可以避免直接写JVM指令。但是该框架文档较少,通常操作只能从其TestCase和presto的源码中学习,本小节简单总结使用airlift.bytecode生成代码的基本用法。
通常,我们理解了变量、数组、控制逻辑、循环逻辑、调用外部方法这几个点,就可以操作一门编程语言了。至于核心库,其作用是辅助我们更高效地开发。对于使用airlift.bytecode框架,理解定义类、定义方法(分支、循环和方法调用)、方法执行这些常用操作就能够满足大部分业务需求:
Case 1: 定义类
private static final AtomicLong CLASS_ID = new AtomicLong();
private static final DateTimeFormatter TIMESTAMP_FORMAT = DateTimeFormatter.ofPattern("YYYYMMdd_HHmmss");
private String clazzName;
private ClassDefinition classDefinition;
public ByteCodeGenDemo(String clazzName){
this.clazzName=clazzName;
}
public static ParameterizedType makeClassName(String baseName, Optional suffix)
{
String className = baseName
+ "" + suffix.orElseGet(() -> Instant.now().atZone(UTC).format(TIMESTAMP_FORMAT))
+ "" + CLASS_ID.incrementAndGet();
return typeFromJavaClassName("org.shgy.demo.$gen." + toJavaIdentifierString(className));
}
public void buildClass(){
ClassDefinition classDefinition = new ClassDefinition(
a(PUBLIC, FINAL),
makeClassName(clazzName,Optional.empty()),
type(Object.class));
this.classDefinition=classDefinition;
}
通过上面的代码,就定义了一个public final修饰的类,而且确保程序运行汇总类名不会重复。
Case 2: 定义方法--IF控制逻辑
/**
• 生成if分支代码
• if(a<0){
System.out.println(a +" a<0");
• }else{
System.out.println(a +" a>=0");
• }
• @param methodName
*/
public void buildMethod1(String methodName){
Parameter argA = arg("a", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
ImmutableList.of(argA));
BytecodeExpression out = getStatic(System.class, "out");
IfStatement ifStatement = new IfStatement();
ifStatement.condition(lessThan(argA,constantInt(0)))
.ifTrue(new BytecodeBlock()
.append(out.invoke("print", void.class, argA))
.append(out.invoke("println", void.class, constantString(" a<0")))
)
.ifFalse(new BytecodeBlock()
.append(out.invoke("print", void.class, argA))
.append(out.invoke("println", void.class, constantString(" a>=0")))
);
method.getBody().append(ifStatement).ret();
}
Case 3: 定义方法–Switch控制逻辑
/**
• 生成switch分支代码
switch (a){
case 1:
System.out.println("a=1");
break;
case 2:
System.out.println("a=2");
break;
default:
System.out.println("a=others");
}
• @param methodName
*/
public void buildMethod2(String methodName){
Parameter argA = arg("a", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
ImmutableList.of(argA));
SwitchStatement.SwitchBuilder switchBuilder = new SwitchStatement.SwitchBuilder().expression(argA);
switchBuilder.addCase(1, BytecodeExpressions.print(BytecodeExpressions.constantString("a=1")));
switchBuilder.addCase(2,BytecodeExpressions.print(BytecodeExpressions.constantString("a=2")));
switchBuilder.defaultCase(invokeStatic(ByteCodeGenDemo.class,"defaultCase", void.class));
method.getBody().append(switchBuilder.build()).ret();
}
public static void defaultCase(){
System.out.println("a=others");
}
Case 4: 定义方法-ForLoop逻辑
/**
* 生成循环逻辑代码
* int sum=0;
* for(int i=s;i<=e;i++){
* sum+=i;
* System.out.println("i="+i+",sum="+sum);
* }
* @param methodName
*/
public void buildMethodLoop(String methodName){
Parameter argS = arg("s", int.class);
Parameter argE = arg("e", int.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(int.class),
ImmutableList.of(argS, argE));
Scope scope = method.getScope();
Variable i = scope.declareVariable(int.class,"i");
Variable sum = scope.declareVariable(int.class,"sum");
BytecodeExpression out = getStatic(System.class, "out");
ForLoop loop = new ForLoop()
.initialize(i.set(argS))
.condition(lessThanOrEqual(i, argE))
.update(incrementVariable(i,(byte)1))
.body(new BytecodeBlock()
.append(sum.set(add(sum,i)))
.append(out.invoke("print", void.class, constantString("i=")))
.append(out.invoke("print", void.class, i))
.append(out.invoke("print", void.class, constantString(",sum=")))
.append(out.invoke("println", void.class,sum))
);
method.getBody().initializeVariable(i).putVariable(sum,0).append(loop).append(sum).retInt();
}
Case 5: 生成类并执行方法
public void executeLoop(String methodName) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// invoke
Class<?> clazz = classGenerator(new DynamicClassLoader(this.getClass().getClassLoader())).defineClass(this.classDefinition,Object.class);
Method loopMethod = clazz.getMethod(methodName, int.class,int.class);
loopMethod.invoke(null,1,10);
}Case 6: 操作数据结构-从Map数据结构取值
public void buildMapGetter(String methodName){
Parameter argRow = arg("row", Map.class);
MethodDefinition method = classDefinition.declareMethod(
a(PUBLIC, STATIC),
methodName,
type(void.class),
of(argRow));
BytecodeExpression out = getStatic(System.class, "out");
Scope scope = method.getScope();
Variable a = scope.declareVariable(int.class,"a");
// 从map中获取key=aa对应的值
method.getBody().append(out.invoke("print", void.class, argRow.invoke("get",Object.class,constantString("aa").cast(Object.class)))).ret();
}
// 代码执行
public void executeMapOp(String methodName) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
// invoke
Class<?> clazz = classGenerator(new DynamicClassLoader(this.getClass().getClassLoader())).defineClass(this.classDefinition,Object.class);
Method loopMethod = clazz.getMethod(methodName, Map.class);
Map<String,Integer> map = Maps.newHashMap();
map.put("aa",111);
loopMethod.invoke(null,map);
}通过上述的几个Case, 我们了解了airlift.bytecode框架的基本用法。如果想更深入研究,需要参考阅读ASM相关的资料,毕竟airlift.bytecode是基于ASM构建的。但是在本文的研究中,到这里就够用了。
4.2 基于动态代码生成实现 where 条件过滤
在熟悉动态代码生成框架的基本使用方法后,我们就可以使用该工具实现具体的业务逻辑了。同样地,我们基于AstVisitor实现生成where条件过滤的字节码。
整体代码框架跟前面的实现保持一致,需要解决问题的关键点在于字节码生成的逻辑。对于where条件的查询语句,本质上是一个二叉树。对于二叉树的遍历,用递归是最简单的方法。递归从某种程度上,跟栈的操作是一致的。
对于实现where条件过滤代码生成,实现逻辑描述如下:
输入:antlr生成的expression表达式
输出:airlift.bytecode生成的class
s1:定义清晰生成类的基础配置:类名、修饰符等信息
s2:定义一个栈用于存储比较运算(ComparisonExpression)计算结果
s3:使用递归方式遍历expression
s4:对于叶子节点(ComparisonExpression),代码生成逻辑如下:从方法定义的参数中取出对应的值,根据比较符号生成计算代码,并将计算结果push到stack
s5:对于非叶子节点
(LogicalBinaryExpression), 代码生成逻辑如下:取出栈顶的两个值,进行and或or操作运算,将计算结果push到stack
s6:当递归回退到根节点时,取出栈顶的值作为计算的最终结果
s7:基于类和方法的定义生成Class
实现字节码生成代码如下:
/**
• 生成比较条件语句
**/
@Override
protected Void visitComparisonExpression(ComparisonExpression node, MethodDefinition context) {
ComparisonExpression.Operator op = node.getOperator();
Expression left = node.getLeft();
Expression right = node.getRight();
if(left instanceof Identifier && right instanceof LongLiteral){
String leftKey = ((Identifier) left).getValue();
Long rightKey = ((LongLiteral) right).getValue();
Parameter argRow = context.getParameters().get(0);
Variable stack = context.getScope().getVariable("stack");
BytecodeBlock body = context.getBody();
BytecodeExpression leftVal = argRow.invoke("get", Object.class,constantString(leftKey).cast(Object.class)).cast(long.class);
BytecodeExpression cResult;
switch (op){
case EQUAL:
cResult = equal(leftVal,constantLong(rightKey));
break;
case LESS_THAN:
cResult = lessThan(leftVal,constantLong(rightKey));
break;
case GREATER_THAN:
cResult =greaterThan(leftVal,constantLong(rightKey));
break;
case NOT_EQUAL:
cResult = notEqual(leftVal,constantLong(rightKey));
break;
case LESS_THAN_OR_EQUAL:
cResult = lessThanOrEqual(leftVal,constantLong(rightKey));
break;
case GREATER_THAN_OR_EQUAL:
cResult = greaterThanOrEqual(leftVal,constantLong(rightKey));
break;
default:
throw new UnsupportedOperationException("not implemented");
}
body.append(stack.invoke("push",Object.class, cResult.cast(Object.class)));
return null;
}else{
throw new UnsupportedOperationException("not implemented");
}
}
生成具体的and 和or操作:
/**
* 生成比较and or语句
**/
@Override
protected Void visitLogicalBinaryExpression(LogicalBinaryExpression node, MethodDefinition context)
{
Expression left = node.getLeft();
Expression right = node.getRight();
// 处理左子树
if(left instanceof ComparisonExpression){
visitComparisonExpression((ComparisonExpression)left,context);
}else if(left instanceof LogicalBinaryExpression){
visitLogicalBinaryExpression((LogicalBinaryExpression) left,context);
}else{
throw new UnsupportedOperationException("not implemented");
}
// 处理右子树
if(right instanceof ComparisonExpression){
visitComparisonExpression((ComparisonExpression)right,context);
}else if(right instanceof LogicalBinaryExpression){
visitLogicalBinaryExpression((LogicalBinaryExpression) right,context);
}else{
throw new UnsupportedOperationException("not implemented");
}
// 根据运算符生成字节码
LogicalBinaryExpression.Operator op = node.getOperator();
Variable stack = context.getScope().getVariable("stack");
BytecodeExpression result;
switch (op){
case AND:
result = stack.invoke("push",Object.class,
and(
stack.invoke("pop",Object.class).cast(boolean.class),
stack.invoke("pop",Object.class).cast(boolean.class)
).cast(Object.class));
break;
case OR:
result = stack.invoke("push",Object.class,
or(
stack.invoke("pop",Object.class).cast(boolean.class),
stack.invoke("pop",Object.class).cast(boolean.class)
).cast(Object.class));
break;
default:
throw new UnsupportedOperationException("not implemented");
}
context.getBody().append(result);
return null;
}
代码实现完成后,为了验证处理逻辑是否正常,可以用两种实现的方式运行同一个测试用例,确保同样的where表达式在同样的参数下执行结果一致。
为了验证两种实现方式执行的性能,这里引入JMH框架,基于JMH框架生成性能验证代码:
@BenchmarkMode(Mode.Throughput)
@Fork(1)
@State(value = Scope.Benchmark)
public class RowFilterBenchmark {
private RowFilter filter1;
private RowFilter filter2;
private List<Map<String,Long>> dataSet = Lists.newArrayListWithCapacity(100000);
@Setup
public void init(){
// antlr处理表达式语句,生成Expression对象
SqlParser sqlParser = new SqlParser();
Expression expression = sqlParser.createExpression("a>5 and b<5");
// 基于AstVisitor实现
this.filter1 = new WhereExpFilter(expression);
// 基于AstVisitor实现
ExpressionCodeCompiler compiler = new ExpressionCodeCompiler();
Class clazz = compiler.compile(expression);
try {
this.filter2 = (RowFilter) clazz.newInstance();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
Random r = new Random();
for(int i=0;i<100000;i++){
Map<String,Long> row = new HashMap<>();
row.put("a", (long) r.nextInt(10));
row.put("b", (long) r.nextInt(10));
dataSet.add(row);
}
}
@Benchmark
public int testAstDirect() {
int cnt =0;
for(Map<String,Long> row:dataSet){
boolean ret = filter1.filter(row);
if(ret){
cnt++;
}
}
return cnt;
}
@Benchmark
public int testAstCompile() {
int cnt =0;
for(Map<String,Long> row:dataSet){
boolean ret = filter2.filter(row);
if(ret){
cnt++;
}
}
return cnt;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(RowFilterBenchmark.class.getSimpleName())
.build();
new Runner(opt).run();
}
}
使用10万量级的数据集,性能验证的结果如下:
Benchmark Mode Cnt Score Error Units
RowFilterBenchmark.testAstCompile thrpt 5 211.298 ± 30.832 ops/s
RowFilterBenchmark.testAstDirect thrpt 5 62.254 ± 8.269 ops/s
通过上述的验证数据,可以得出初步的结论,对于简单的比较表达式,基于代码生成的方式相比直接遍历的方式大约有3倍左右的性能提升。对比直接基于AstVisitor实现where条件过滤,代码生成无需对表达式中的操作符进行判断,直接基于表达式动态生成代码,裁剪了许多判断的分支。
五、总结
本文探索了SQL引擎中where表达式的实现思路,基于antlr实现了两种方式::
其一是直接遍历表达式生成的Expression;
其二是基于表达式生成的Expression通过airlift.bytecode动态生成字节码。
本文初步分析了Presto中应用代码生成实现相关业务逻辑的出发点及背景问题。并使用JMH进行了性能测试,测试结果表明对于同样的实现思路,基于代码生成方式相比直接实现约有3倍的性能提升。
实际上Presto中使用代码生成的方式相比本文描述要复杂得多,跟文本实现的方式并不一样。基于本文的探索更多在于探索研究基本的思路,而非再造一个Presto。
尽管使用动态代码生成对于性能的提升效果明显,但是在业务实践中,需要权衡使用代码生成的ROI,毕竟使用代码生成实现的逻辑,代码可读性和可维护性相比直接编码要复杂很多,开发复杂度也复杂很多。就像C语言嵌入汇编一样,代码生成技术在业务开发中使用同样需要慎重考虑,使用得当能取得事半功倍的效果,使用不当或滥用则会为项目埋下不可预知的定时炸弹。



































