
一、背景
自2014年大数据首次写入政府工作报告,大数据已经发展7年。大数据的类型也从交易数据延伸到交互数据与传感数据。数据规模也到达了PB级别。
大数据的规模大到对数据的获取、存储、管理、分析超出了传统数据库软件工具能力范围。在这个背景下,各种大数据相关工具相继出现,用于应对各种业务场景需求。从Hadoop生态的Hive, Spark, Presto, Kylin, Druid到非Hadoop生态的ClickHouse, Elasticsearch,不一而足...
这些大数据处理工具特性不同,应用场景不同,但是对外提供的接口或者说操作语言都是相似的,即各个组件都是支持SQL语言。只是基于不同的应用场景和特性,实现了各自的SQL方言。这就要求相关开源项目自行实现SQL解析。在这个背景下,诞生于1989年的语法解析器生成器ANTLR迎来了黄金时代。
二、简介
ANTLR是开源的语法解析器生成器,距今已有30多年的历史。是一个经历了时间考验的开源项目。一个程序从源代码到机器可执行,基本需要3个阶段:编写、编译、执行。
在编译阶段,需要进行词法和语法的分析。ANTLR聚焦的问题就是把源码进行词法和句法分析,产生一个树状的分析器。ANTLR几乎支持对所有主流编程语言的解析。从antlr/grammars-v4可以看到,ANTLR支持Java,C, Python, SQL等数十种编程语言。通常我们没有扩展编程语言的需求,所以大部分情况下这些语言编译支持更多是供学习研究使用,或者用在各种开发工具(NetBeans、Intellij)中用于校验语法正确性、和格式化代码。
对于SQL语言,ANTLR的应用广度和深度会更大,这是由于Hive, Presto, SparkSQL等由于需要对SQL的执行进行定制化开发,比如实现分布式查询引擎、实现各种大数据场景下独有的特性等。
三、基于ANTLR4实现四则运算
当前我们主要使用的是ANTLR4。在《The Definitive ANTLR4 Reference》一书中,介绍了基于ANTLR4的各种有趣的应用场景。比如:实现一个支持四则运算的计算器;实现JSON等格式化文本的解析和提取;
将JSON转换成XML;从Java源码中提取接口等。本节以实现四则运算计算器为例,介绍Antlr4的简单应用,为后面实现基于ANTLR4解析SQL铺平道路。实际上,支持数字运算也是各个编程语言必须具备的基本能力。
3.1 自行编码实现
在没有ANTLR4时,我们想实现四则运算该怎么处理呢?有一种思路是基于栈实现。例如,在不考虑异常处理的情况下,自行实现简单的四则运算代码如下:
package org.example.calc;
import java.util.*;
public class CalcByHand {
// 定义操作符并区分优先级,*/ 优先级较高
public static Set<String> opSet1 = new HashSet<>();
public static Set<String> opSet2 = new HashSet<>();
static{
opSet1.add("+");
opSet1.add("-");
opSet2.add("*");
opSet2.add("/");
}
public static void main(String[] args) {
String exp="1+3*4";
//将表达式拆分成token
String[] tokens = exp.split("((?<=[\\+|\\-|\\*|\\/])|(?=[\\+|\\-|\\*|\\/]))");
Stack<String> opStack = new Stack<>();
Stack<String> numStack = new Stack<>();
int proi=1;
// 基于类型放到不同的栈中
for(String token: tokens){
token = token.trim();
if(opSet1.contains(token)){
opStack.push(token);
proi=1;
}else if(opSet2.contains(token)){
proi=2;
opStack.push(token);
}else{
numStack.push(token);
// 如果操作数前面的运算符是高优先级运算符,计算后结果入栈
if(proi==2){
calcExp(opStack,numStack);
}
}
}
while (!opStack.isEmpty()){
calcExp(opStack,numStack);
}
String finalVal = numStack.pop();
System.out.println(finalVal);
}
private static void calcExp(Stack<String> opStack, Stack<String> numStack) {
double right=Double.valueOf(numStack.pop());
double left = Double.valueOf(numStack.pop());
String op = opStack.pop();
String val;
switch (op){
case "+":
val =String.valueOf(left+right);
break;
case "-":
val =String.valueOf(left-right);
break;
case "*":
val =String.valueOf(left*right);
break;
case "/":
val =String.valueOf(left/right);
break;
default:
throw new UnsupportedOperationException("unsupported");
}
numStack.push(val);
}
}
代码量不大,用到了数据结构-栈的特性,需要自行控制运算符优先级,特性上没有支持括号表达式,也没有支持表达式赋值。接下来看看使用ANTLR4实现。
3.2 基于ANTLR4实现
使用ANTLR4编程的基本流程是固定的,通常分为如下三步:
- 基于需求按照ANTLR4的规则编写自定义语法的语义规则, 保存成以g4为后缀的文件。
- 使用ANTLR4工具处理g4文件,生成词法分析器、句法分析器代码、词典文件。
- 编写代码继承Visitor类或实现Listener接口,开发自己的业务逻辑代码。
基于上面的流程,我们借助现有案例剖析一下细节。
第一步:基于ANTLR4的规则定义语法文件,文件名以g4为后缀。例如实现计算器的语法规则文件命名为LabeledExpr.g4。其内容如下:
grammar LabeledExpr; // rename to distinguish from Expr.g4
prog: stat+ ;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace
(注:此文件案例来源于《The Definitive ANTLR4 Reference》)
简单解读一下LabeledExpr.g4文件。ANTLR4规则是基于正则表达式定义定义。规则的理解是自顶向下的,每个分号结束的语句表示一个规则 。例如第一行:grammar LabeledExpr; 表示我们的语法名称是LabeledExpr, 这个名字需要跟文件名需要保持一致。Java编码也有相似的规则:类名跟类文件一致。
- 规则prog 表示prog是一个或多个stat。
- 规则stat 适配三种子规则:空行、表达式expr、赋值表达式 ID’=’expr。
- 表达式expr适配五种子规则:乘除法、加减法、整型、ID、括号表达式。很显然,这是一个递归的定义。
最后定义的是组成复合规则的基础元素,比如:
- 规则ID: [a-zA-Z]+表示ID限于大小写英文字符串;
- INT: [0-9]+; 表示INT这个规则是0-9之间的一个或多个数字,当然这个定义其实并不严格。再严格一点,应该限制其长度。
在理解正则表达式的基础上,ANTLR4的g4语法规则还是比较好理解的。
定义ANTLR4规则需要注意一种情况,即可能出现一个字符串同时支持多种规则,如以下的两个规则:
- ID: [a-zA-Z]+;
- FROM: ‘from’;
很明显,字符串” from”同时满足上述两个规则,ANTLR4处理的方式是按照定义的顺序决定。这里ID定义在FROM前面,所以字符串from会优先匹配到ID这个规则上。
其实在定义好与法规中,编写完成g4文件后,ANTLR4已经为我们完成了50%的工作:帮我们实现了整个架构及接口了,剩下的开发工作就是基于接口或抽象类进行具体的实现。实现上有两种方式来处理生成的语法树,其一Visitor模式,另一种方式是Listener(监听器模式)。
3.2.1 使用Visitor模式
第二步:使用ANTLR4工具解析g4文件,生成代码。即ANTLR工具解析g4文件,为我们自动生成基础代码。流程图示如下:
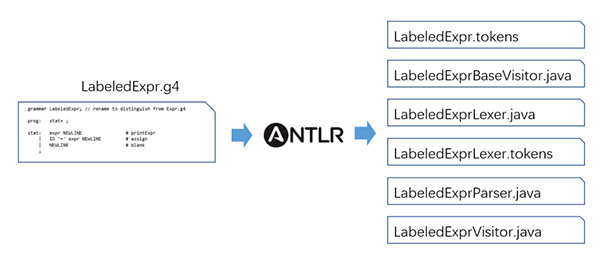
命令行如下:
antlr4 -package org.example.calc -no-listener -visitor .\LabeledExpr.g4
命令执行完成后,生成的文件如下:
$ tree .
├── LabeledExpr.g4
├── LabeledExpr.tokens
├── LabeledExprBaseVisitor.java
├── LabeledExprLexer.java
├── LabeledExprLexer.tokens
├── LabeledExprParser.java
└── LabeledExprVisitor.java
首先开发入口类Calc.java。Calc类是整个程序的入口,调用ANTLR4的lexer和parser类核心代码如下:
ANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
接下来定义类继承LabeledExprBaseVisitor类,覆写的方法如下:
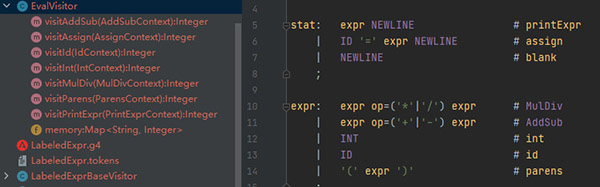
从图中可以看出,生成的代码和规则定义是对应起来的。例如visitAddSub对应AddSub规则,visitId对应id规则。以此类推…实现加减法的代码如下:
/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(LabeledExprParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpression
int right = visit(ctx.expr(1)); // get value of right subexpression
if ( ctx.op.getType() == LabeledExprParser.ADD ) return left + right;
return left - right; // must be SUB
}相当直观。代码编写完成后,就是运行Calc。运行Calc的main函数,在交互命令行输入相应的运算表达式,换行Ctrl+D即可看到运算结果。例如1+3*4=13。
3.2.2 使用Listener模式
类似的,我们也可以使用Listener模式实现四则运算。命令行如下:
antlr4 -package org.example.calc -listener .\LabeledExpr.g4
该命令的执行同样会为我们生产框架代码。在框架代码的基础上,我们开发入口类和接口实现类即可。首先开发入口类Calc.java。Calc类是整个程序的入口,调用ANTLR4的lexer和parser类代码如下:
ANTLRInputStream input = new ANTLRInputStream(is);
LabeledExprLexer lexer = new LabeledExprLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
LabeledExprParser parser = new LabeledExprParser(tokens);
ParseTree tree = parser.prog(); // parse
ParseTreeWalker walker = new ParseTreeWalker();
walker.walk(new EvalListener(), tree);
可以看出生成ParseTree的调用逻辑一模一样。实现Listener的代码略微复杂一些,也需要用到栈这种数据结构,但是只需要一个操作数栈就可以了,也无需自行控制优先级。以AddSub为例:
@Override
public void exitAddSub(LabeledExprParser.AddSubContext ctx) {
Double left = numStack.pop();
Double right= numStack.pop();
Double result;
if (ctx.op.getType() == LabeledExprParser.ADD) {
result = left + right;
} else {
result = left - right;
}
numStack.push(result);
}
直接从栈中取出操作数,进行运算即可。
3.2.3 小结
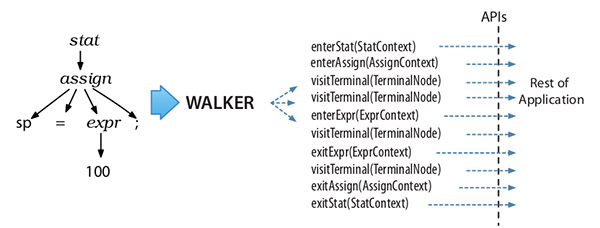
关于Listener模式和Visitor模式的区别,《The Definitive ANTLR 4 Reference》一书中有清晰的解释:
Listener模式:
Visitor模式
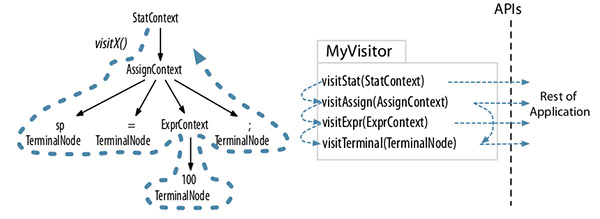
- Listener模式通过walker对象自行遍历,不用考虑其语法树上下级关系。Vistor需要自行控制访问的子节点,如果遗漏了某个子节点,那么整个子节点都访问不到了。
- Listener模式的方法没有返回值,Vistor模式可以设定任意返回值。
- Listener模式的访问栈清晰明确,Vistor模式是方法调用栈,如果实现出错有可能导致StackOverFlow。
通过这个简单的例子,我们驱动Antlr4实现了一个简单的计算器。学习了ANTLR4的应用流程。了解了g4语法文件的定义方式、Visitor模式和Listener模式。通过ANTLR4,我们生成了ParseTree,并基于Visitor模式和Listener模式访问了这个ParseTree,实现了四则运算。
综合上述的例子可以发现,如果没有ANTLR4,我们自行编写算法也能实现同样的功能。但是使用ANTLR不用关心表达式串的解析流程,只关注具体的业务实现即可,非常省心和省事。
更重要的是,ANTLR4相比自行实现提供了更具想象空间的抽象逻辑,上升到了方法论的高度,因为它已经不局限于解决某个问题,而是解决一类问题。可以说ANTLR相比于自行硬编码解决问题的思路有如数学领域普通的面积公式和微积分的差距。
四、参考Presto源码开发SQL解析器
前面介绍了使用ANTLR4实现四则运算,其目的在于理解ANTLR4的应用方式。接下来图穷匕首见,展示出我们的真正目的:研究ANTLR4在Presto中如何实现SQL语句的解析。
支持完整的SQL语法是一个庞大的工程。在presto中有完整的SqlBase.g4文件,定义了presto支持的所有SQL语法,涵盖了DDL语法和DML语法。该文件体系较为庞大,并不适合学习探究某个具体的细节点。
为了探究SQL解析的过程,理解SQL执行背后的逻辑,在简单地阅读相关资料文档的基础上,我选择自己动手编码实验。为此,定义一个小目标:实现一个SQL解析器。用该解析器实现select field from table语法,从本地的csv数据源中查询指定的字段。
4.1 裁剪SelectBase.g4文件
基于同实现四则运算器同样的流程,首先定义SelectBase.g4文件。由于有了Presto源码作为参照系,我们的SelectBase.g4并不需要自己开发,只需要基于Presto的g4文件裁剪即可。裁剪后的内容如下:
grammar SqlBase;
tokens {
DELIMITER
}
singleStatement
: statement EOF
;
statement
: query #statementDefault
;
query
: queryNoWith
;
queryNoWith:
queryTerm
;
queryTerm
: queryPrimary #queryTermDefault
;
queryPrimary
: querySpecification #queryPrimaryDefault
;
querySpecification
: SELECT selectItem (',' selectItem)*
(FROM relation (',' relation)*)?
;
selectItem
: expression #selectSingle
;
relation
: sampledRelation #relationDefault
;
expression
: booleanExpression
;
booleanExpression
: valueExpression #predicated
;
valueExpression
: primaryExpression #valueExpressionDefault
;
primaryExpression
: identifier #columnReference
;
sampledRelation
: aliasedRelation
;
aliasedRelation
: relationPrimary
;
relationPrimary
: qualifiedName #tableName
;
qualifiedName
: identifier ('.' identifier)*
;
identifier
: IDENTIFIER #unquotedIdentifier
;
SELECT: 'SELECT';
FROM: 'FROM';
fragment DIGIT
: [0-9]
;
fragment LETTER
: [A-Z]
;
IDENTIFIER
: (LETTER | '_') (LETTER | DIGIT | '_' | '@' | ':')*
;
WS
: [ \r\n\t]+ -> channel(HIDDEN)
;
// Catch-all for anything we can't recognize.
// We use this to be able to ignore and recover all the text
// when splitting statements with DelimiterLexer
UNRECOGNIZED
: .
;
相比presto源码中700多行的规则,我们裁剪到了其1/10的大小。该文件的核心规则为: SELECT selectItem (',' selectItem)* (FROM relation (',' relation)*)?
通过理解g4文件,也可以更清楚地理解我们查询语句的构成。例如通常我们最常见的查询数据源是数据表。但是在SQL语法中,我们查询数据表被抽象成了relation。
这个relation有可能来自于具体的数据表,或者是子查询,或者是JOIN,或者是数据的抽样,或者是表达式的unnest。在大数据领域,这样的扩展会极大方便数据的处理。
例如,使用unnest语法解析复杂类型的数据,SQL如下:

尽管SQL较为复杂,但是通过理解g4文件,也能清晰理解其结构划分。回到SelectBase.g4文件,同样我们使用Antlr4命令处理g4文件,生成代码:
antlr4 -package org.example.antlr -no-listener -visitor .\SqlBase.g4
这样就生成了基础的框架代码。接下来就是自行处理业务逻辑的工作了。
4.2 遍历语法树封装SQL结构信息
接下来基于SQL语法定义语法树的节点类型,如下图所示。
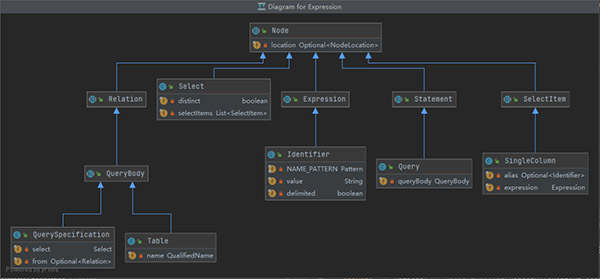
通过这个类图,可以清晰明了看清楚SQL语法中的各个基本元素。
然后基于visitor模式实现自己的解析类AstBuilder (这里为了简化问题,依然从presto源码中进行裁剪)。以处理querySpecification规则代码为例:
@Override
public Node visitQuerySpecification(SqlBaseParser.QuerySpecificationContext context)
{
Optional<Relation> from = Optional.empty();
List<SelectItem> selectItems = visit(context.selectItem(), SelectItem.class);
List<Relation> relations = visit(context.relation(), Relation.class);
if (!relations.isEmpty()) {
// synthesize implicit join nodes
Iterator<Relation> iterator = relations.iterator();
Relation relation = iterator.next();
from = Optional.of(relation);
}
return new QuerySpecification(
getLocation(context),
new Select(getLocation(context.SELECT()), false, selectItems),
from);
}
通过代码,我们已经解析出了查询的数据源和具体的字段,封装到了QuerySpecification对象中。
4.3 应用Statement对象实现数据查询
通过前面实现四则运算器的例子,我们知道ANTLR把用户输入的语句解析成ParseTree。业务开发人员自行实现相关接口解析ParseTree。Presto通过对输入sql语句的解析,生成ParseTree, 对ParseTree进行遍历,最终生成了Statement对象。核心代码如下:
SqlParser sqlParser = new SqlParser();
Statement statement = sqlParser.createStatement(sql);
有了Statement对象我们如何使用呢?结合前面的类图,我们可以发现:
- Query类型的Statement有QueryBody属性。
- QuerySpecification类型的QueryBody有select属性和from属性。
通过这个结构,我们可以清晰地获取到实现select查询的必备元素:
- 从from属性中获取待查询的目标表Table。这里约定表名和csv文件名一致。
- 从select属性中获取待查询的目标字段SelectItem。这里约定csv首行为title行。
整个业务流程就清晰了,在解析sql语句生成statement对象后,按如下的步骤:
s1: 获取查询的数据表以及字段。
s2: 通过数据表名称定为到数据文件,并读取数据文件数据。
s3: 格式化输出字段名称到命令行。
s4: 格式化输出字段内容到命令行。
为了简化逻辑,代码只处理主线,不做异常处理。
/**
* 获取待查询的表名和字段名称
*/
QuerySpecification specification = (QuerySpecification) query.getQueryBody();
Table table= (Table) specification.getFrom().get();
List<SelectItem> selectItems = specification.getSelect().getSelectItems();
List<String> fieldNames = Lists.newArrayList();
for(SelectItem item:selectItems){
SingleColumn column = (SingleColumn) item;
fieldNames.add(((Identifier)column.getExpression()).getValue());
}
/**
* 基于表名确定查询的数据源文件
*/
String fileLoc = String.format("./data/%s.csv",table.getName());
/**
* 从csv文件中读取指定的字段
*/
Reader in = new FileReader(fileLoc);
Iterable<CSVRecord> records = CSVFormat.RFC4180.withFirstRecordAsHeader().parse(in);
List<Row> rowList = Lists.newArrayList();
for(CSVRecord record:records){
Row row = new Row();
for(String field:fieldNames){
row.addColumn(record.get(field));
}
rowList.add(row);
}
/**
* 格式化输出到控制台
*/
int width=30;
String format = fieldNames.stream().map(s-> "%-"+width+"s").collect(Collectors.joining("|"));
System.out.println( "|"+String.format(format, fieldNames.toArray())+"|");
int flagCnt = width*fieldNames.size()+fieldNames.size();
String rowDelimiter = String.join("", Collections.nCopies(flagCnt, "-"));
System.out.println(rowDelimiter);
for(Row row:rowList){
System.out.println( "|"+String.format(format, row.getColumnList().toArray())+"|");
}
代码仅供演示功能,暂不考虑异常逻辑,比如查询字段不存在、csv文件定义字段名称不符合要求等问题。
4.4 实现效果展示
在我们项目data目录,存储如下的csv文件:

cities.csv文件样例数据如下:
"LatD","LatM","LatS","NS","LonD","LonM","LonS","EW","City","State"
41, 5, 59, "N", 80, 39, 0, "W", "Youngstown", OH
42, 52, 48, "N", 97, 23, 23, "W", "Yankton", SD
46, 35, 59, "N", 120, 30, 36, "W", "Yakima", WA
42, 16, 12, "N", 71, 48, 0, "W", "Worcester", MA
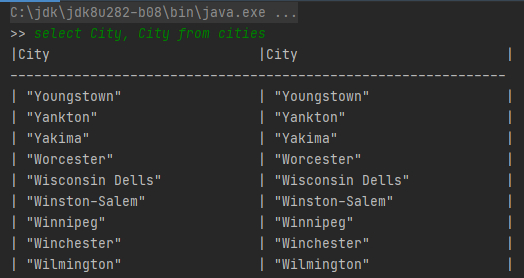
运行代码查询数据。使用SQL语句指定字段从csv文件中查询。最终实现类似SQL查询的效果如下:
SQL样例1:select City, City from cities
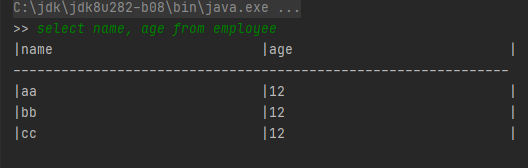
SQL样例2:select name, age from employee
本节讲述了如何基于Presto源码,裁剪g4规则文件,然后基于Antlr4实现用sql语句从csv文件查询数据。依托于对Presto源码的裁剪进行编码实验,对于研究SQL引擎实现,理解Presto源码能起到一定的作用。
五、总结
本文基于四则运算器和使用SQL查询csv数据两个案例阐述了ANTLR4在项目开发中的应用思路和过程,相关的代码可以在github上看到。理解ANTLR4的用法能够帮助理解SQL的定义规则及执行过程,辅助业务开发中编写出高效的SQL语句。同时对于理解编译原理,定义自己的DSL,抽象业务逻辑也大有裨益。纸上得来终觉浅,绝知此事要躬行。通过本文描述的方式研究源码实现,也不失为一种乐趣。






























