













译者 | 李睿
审校 | 孙淑娟
InfluxData公司资深软件工程师Nga Tran曾在一篇文章中描述了分片数据库系统来扩展查询和摄取工作负载的吞吐量和性能。而本文将介绍另一种常用技术,也就是分区,它为分片数据库在性能和管理方面提供了更多优势,还将描述如何有效地处理查询和摄取工作负载的分区,以及如何管理读取要求完全不同的热分区和冷分区。
分片 vs. 分区
分片是一种在分布式数据库系统中拆分数据的方法。每个分片中的数据不必共享CPU或内存等资源,并且可以并行读取或写入。
图1是一个分片数据库的示例。例如美国50个州的销售数据被分成4个分片,每个分片包含12个或13个州的数据。通过为每个分片分配一个查询节点,读取所有50个州的作业可以在并行运行的这四个节点之间拆分,并且与通过一个节点读取所有50个州的设置相比,其执行速度将快四倍。
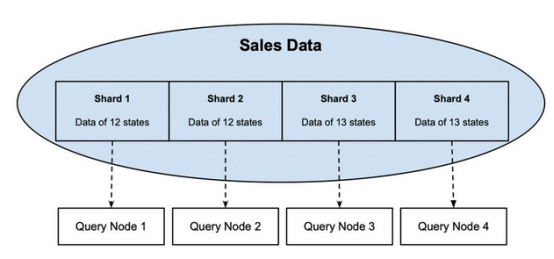
图1销售数据分为四个分片,每个分片分配给一个查询节点
分区是一种将每个分片中的数据拆分为非重叠分区以进行进一步并行处理的方法。这减少了不必要数据的读取,并允许有效地实施数据保留策略。
在图2中,每个分片的数据按销售日进行分区。如果需要创建一个特定日期(例如2022年5月1日)的销售报告,查询节点只需要读取其对应分区2022.05.01的数据。
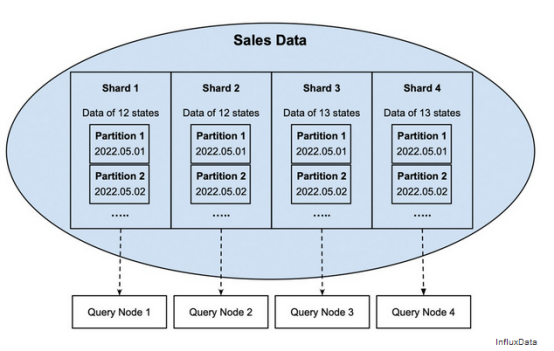
图2每个分片的销售数据进一步拆分为非重叠的日期分区
本文的其余部分将关注分区的影响,并将看到如何有效地管理对热数据和冷数据的查询和摄取工作负载的分区。
分区效果
数据分区的三个最常见的好处是数据剪枝、节点内并行性和快速数据删除。
数据剪枝
数据库系统可能包含几年的数据,但大多数查询只需要读取最近的数据(例如“最近三天有多少订单?”)。将数据分区到不重叠的分区中,如图2所示,可以轻松跳过整个越界分区,并只读取和处理相关的非常小的数据集以快速返回结果。
节点内并行性
多线程处理和流数据在数据库系统中对于充分利用可用CPU和内存并获得最佳性能至关重要。而将数据划分为小分区可以更轻松地实现每个分区执行一个线程的多线程引擎。对于每个分区,可以产生更多线程来处理该分区内的数据。了解分区统计信息(例如大小和行数)将有助于为特定分区分配最佳CPU和内存量。
快速数据删除
许多企业只保留最近的数据(例如最近三个月的数据),并希望尽快删除旧数据。通过在不重叠的时间窗口上对数据进行分区,删除旧分区变得像删除文件一样简单,无需重新组织数据和中断其他查询或摄取活动。如果必须保留所有数据,本文后面的部分将介绍如何以不同方式管理新旧数据,以确保数据库系统在所有情况下都能提供出色的性能。
存储和管理分区
针对查询工作负载进行优化
一个分区已经包含一部分数据,因此不希望将一个分区存储在许多较小的文件中(或者在内存数据库的情况下为块)。一个分区应该只包含一个或几个文件。
最小化分区中的文件数量有两个重要的好处。它既减少了读取数据以执行查询的I/O操作,又改进了数据编码/压缩。改进编码反过来会降低存储成本,更重要的是,通过读取更少的数据来提高查询执行速度。
针对摄取工作负载进行优化
Naive摄取。为了将一个分区的数据保存在一个文件中以利于上述读取优化,每次摄取一组数据时,都必须将其解析并拆分为正确的分区,然后合并到其对应分区的现有文件中,如图3所示。
由于I/O以及混合和编码分区数据的成本高昂,将新数据与现有数据合并的过程通常需要时间。这将导致向客户端返回数据已成功摄取的响应以及对新摄取的数据的查询的长时间延迟,因为它不会立即在存储中可用。
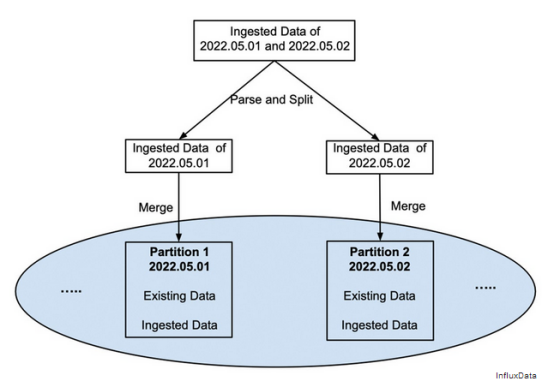
图3新数据与现有数据立即合并到同一个文件中的原始摄取
低延迟摄取。为了保持每次摄取的低延迟,可以将过程分为两个步骤:摄取和压缩。
摄取
在摄取步骤中,摄取的数据被拆分并写入自己的文件,如图4所示。它不会与分区的现有数据合并。一旦摄取的数据成功持久化,摄取客户端将收到成功信号,并且新摄取的文件将可用于查询。
如果摄取率很高,许多小文件将累积在分区中,如图5所示。在这个阶段,需要从分区中获取数据的查询必须读取该分区的所有文件。当然,这对查询性能来说并不理想。如下所述的压缩步骤将文件的这种积累保持在最低限度。
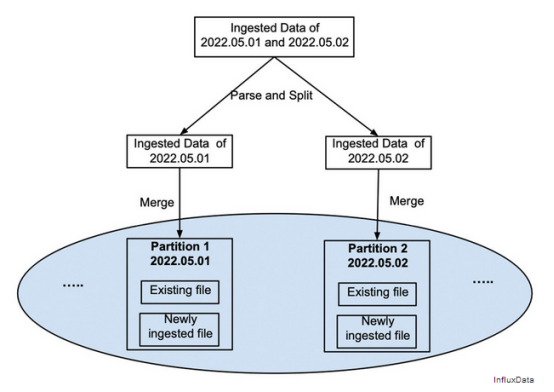
图4将新摄取的数据写入新文件
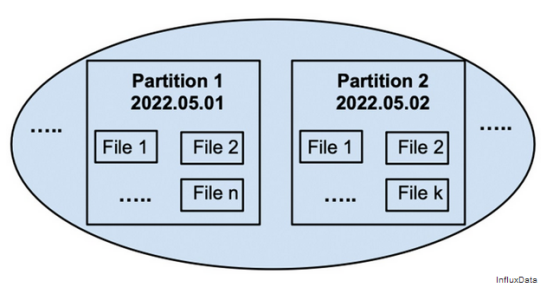
图5 在高摄取数据工作负载下,一个分区将累积许多文件
压缩
压缩是将一个分区的文件合并成一个或几个文件的过程,以获得更好的查询性能和压缩。例如,图6显示了将分区2022.05.01中的所有文件合并为一个文件,并将分区2022.05.02中的所有文件合并为两个文件,每个文件小于100MB。
对于不同的系统,关于压缩频率和压缩文件的大小的决定会有所不同,但共同的目标是通过减少I/O(即文件数量)并使文件足够大以有效压缩来保持高查询性能。
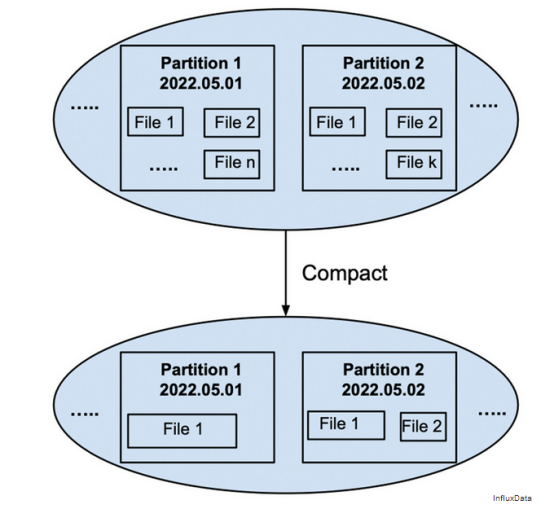
图6 将一个分区的多个文件压缩成一个或几个文件
热分区 vs. 冷分区
经常查询的分区称为热分区,而很少读取的分区称为冷分区。在数据库中,热分区通常是包含最近数据的分区,例如最近的销售日期。冷分区通常包含较旧的数据,这些数据不太可能被读取。
此外,当数据变旧时,通常会以较大的块进行查询,例如按月甚至按年进行查询。以下是一些将数据从热到冷明确分类的示例:
- 热:本周的数据。
- 不太热:前几周但是当月的数据。
- 冷:来自前几个月但是本年度的数据。
- 更冷:去年及以前的数据。
为了减少冷热数据之间的歧义,需要找到两个问题的答案。首先,需要量化热、不太热、冷、更冷,甚至可能越来越冷的数据。其次,需要考虑在读取冷数据的情况下,如何实现更少的I/O。每个文件代表一天的数据分区,人们不想只是为了获得去年的销售收入而去读取365个文件。
分层分区
图7所示的分层分区为上述两个问题提供了答案。本周每一天的数据都存储在其自己的分区中。本月前几周的数据按周划分。本年度前几个月的数据按月份划分。更早的数据按年份划分。
通过定义活动分区来代替当前的日期分区,可以放宽该模型。在活动分区之后到达的所有数据将按日期进行分区,而在活动分区之前的数据将按周、月和年进行分区。这允许系统根据需要保留尽可能多的最近使用的小分区。尽管本文中的所有示例都按时间分区数据,但只要可以为分区及其层次结构定义表达式,非时间分区的工作方式也将类似。
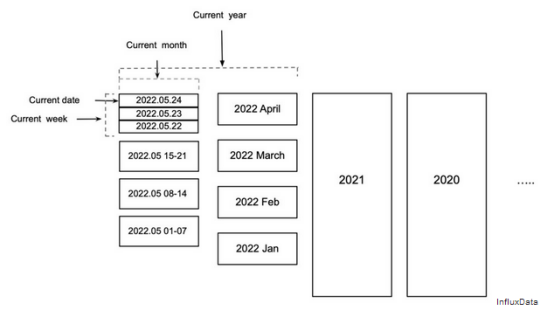
图7分层分区
分层分区减少了系统中的分区数量,使其更易于管理,并减少了在查询较大和较旧的块时需要读取的分区数量。
分层分区的查询过程与非分层分区的查询过程相同,因为它将应用相同的数据剪枝策略来仅读取相关分区。摄取和压缩过程会稍微复杂一些,因为在其定义的层次结构中组织分区会更加困难。
聚合分区
许多企业并不想保留旧数据,而是希望保留聚合数据,例如每个月的订单数量和每种产品的总销售额。这可以通过聚合数据并按月分区提供支持。但是,由于聚合分区存储聚合数据,因此它们的架构将与非聚合分区不同,这将导致摄取和查询的额外工作。有不同的方法来管理这些冷数据和聚合数据,但它们是适合未来的大主题。
文章标题:Partitioning for performance in a sharding database system,作者:Nga Tran
















