MySQL 系统变量 wait_timeout,默认值是 28800 秒(8 小时),用于控制客户端多长时间没有给 MySQL 发送请求,MySQL 就自动断开连接。

多年前开发过一个异步发送订单短信、邮件通知的守护程序,每次程序启动时会创建数据库连接,后续读写数据库操作就一直复用这个连接。
某一天,用户反馈下单后收不到通知了,我们登录服务器看到程序还在运行。
经过排查确认,发生问题的这天,距离上一次有用户下单超过了 8 小时,MySQL 服务端已经自动断开连接了。
解决这个问题的办法比较简单,程序只要定期给 MySQL 发送请求,表示自己还活着,MySQL 就不会触发断开连接的操作了,这就是数据库连接保活的应用场景。
今天我们来聊聊数据库连接保活的原理和方式。
本文内容基于 MySQL 8.0.29 源码。
正文
1、概述
MySQL 系统变量 wait_timeout,默认值是 28800 秒(8 小时),用于控制客户端多长时间没有给 MySQL 发送请求,MySQL 就自动断开连接。
如果我们的业务系统不那么闲,能隔三差五的给 MySQL 发送一些请求,数据库连接会一直处于活跃状态,也就不需要专门保活了。
有一些业务系统,低峰期可能很长时间都不会有读写请求,一旦间隔时间超过 wait_timeout,数据库连接就断开了,连接保活自然不可避免。
接下来我们聊聊 2 种连接保活方式,以及它们之间有什么不一样,在这之前,我们先来看看 wait_timeout 是怎么控制超时逻辑的。
2、 wait_timeout 超时逻辑
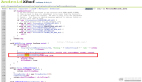
客户端和 MySQL 建立连接之后,MySQL 每次开始等待客户端发送数据之前,都会根据系统变量 wait_timeout 的值设置最长等待时间:
bool do_command(THD *thd){
……
net = thd->get_protocol_classic()->get_net();
my_net_set_read_timeout(net, thd->variables.net_wait_timeout);
……
}上面代码中的 net_wait_timeout 就是系统变量 wait_timeout 的化身。
设置最长等待时间之后,接下来就是安静的等待了,执行等待操作的方法是 vio_io_wait():
int vio_socket_io_wait(Vio *vio, enum enum_vio_io_event event){
int timeout, ret;
……
timeout = vio->read_timeout;
……
switch (vio_io_wait(vio, event, timeout)) {
……
case 0:
/* The wait timed out. */
ret = -1;
break;
……
}
return ret;
}如果达到了最长等待时间,客户端一直没有发送数据,vio_io_wait() 会返 0 表示超时。
然后,程序会沿着调用栈一路返回到 net_read_raw_loop() 方法中,设置返回给客户端的错误码 ER_CLIENT_INTERACTION_TIMEOUT(4031),对应的错误信息为:
The client was disconnected by the server because of inactivity.
See wait_timeout and interactive_timeout for configuring this behavior.
准备好返回给客户端的错误码和错误信息之后,就会进行一系列断开连接相关的操作,最后把错误码和错误信息发送给客户端。
如果我们用的是 MySQL 自带的交互式客户端 mysql,发生超时之后,等下次再执行 SQL 语句时,就会看到这样的错误了:
mysql> SET wait_timeout = 10;
10 秒之后......
mysql> SELECT * FROM t1 LIMIT 1;
ERROR 4031 (HY000): The client was disconnected by the server because of inactivity. See wait_timeout and interactive_timeout for configuring this behavior.
No connection. Trying to reconnect...
对 MySQL 服务端主动断开连接过程大概介绍之后,接下来看看 2 种连接保活方式。
3、ping
站在客户端的视角看,使用 ping 命令是为了判断 MySQL 服务端是否还活着。
换一个角度,在 MySQL 服务端看来,一个客户端给它发送了 ping 命令,说明这个客户端连接还活着,它就不会把这个客户端的连接关闭。
所以,ping 命令不但可以用于数据库连接探活,还可以用于保活。
MySQL 没有提供 ping 语句,如果想测试发送 ping 命令,可以使用 mysqladmin:
# 发送 ping 命令
mysqladmin -h127.0.0.1 -P 3307 -uroot ping
# 收到的结果(表示 MySQL 服务端还活着)
mysqld is alive
在数据库连接池或者业务系统中,通过程序提供的 API 也能很方便地发送 ping 命令给 MySQL 服务端。
在业务低峰期,客户端定时给 MySQL 服务端发送 ping 命令,就能给连接保活了。
4、select
另一种连接保活方式是执行 SQL 语句,一般都是 select 语句,可以有各种花样:
SELECT 1;
SELECT version();
SELECT @@version;
……
执行 select 语句保活,和正常执行业务 SQL 没什么区别,这里不展开了。
5、两种保活方式对比
既然 ping 和 select 都能实现数据库连接保活,那它们之间有什么不一样?
在MySQL 源码的实现中,体现了 2 点区别:
区别 1:ping 是命令,我们只能通过 MySQL 提供的 API,或 mysqladmin 这样的工具发送 ping 命令给 MySQL 服务端。
select 是 SQL 语句,通过 MySQL API 或 mysql 交互式客户端都能执行 select 语句。
区别 2:ping 的执行流程比 select 更短,效率更高,通过对比两者的调用栈,我们能更直观的看到这一点。
两种方式都会响应客户端请求,后面给出的调用栈中,把这部分省略了。
ping 命令的主要调用栈如下:
| > pfs_spawn_thread(void*)
| | > handle_connection(void*)
| | | > do_command(THD*)
| | | | > dispatch_command(THD*, COM_DATA const*, enum_server_command)
ping 命令的调用栈很简单,连词法解析、语法解析过程都不需要,进入 dispatch_command() 方法之后,判断是 ping 命令,就直接给客户端返回 OK 状态,整个流程就结束了:
bool dispatch_command(THD *thd, const COM_DATA *com_data,
enum enum_server_command command){
......
switch (command) {
......
case COM_PING:
thd->status_var.com_other++;
my_ok(thd); // Tell client we are alive
break;
......
}
......
}
接下来是 select 的调用栈,以最简单的 SELECT 1 为例,主要调用栈如下:
SELECT 1 的调用栈比较长,把主要调用栈都列出来是为了大家对 SELECT 1 的执行过程有更直观的了解。
| > pfs_spawn_thread(void*)
| | > handle_connection(void*)
| | | > do_command(THD*)
| | | | > dispatch_command(THD*, COM_DATA const*, enum_server_command)
| | | | | > dispatch_sql_command(THD*, Parser_state*)
| | | | | | > parse_sql(THD*, Parser_state*, Object_creation_ctx*)
| | | | | | > mysql_execute_command(THD*, bool)
| | | | | | | > Sql_cmd_dml::execute(THD*)
| | | | | | | | > Sql_cmd_dml::prepare(THD*)
| | | | | | | | | > open_tables_for_query(THD*, TABLE_LIST*, unsigned int)
| | | | | | | | | | > open_tables(...)
| | | | | | | | | | | > lock_table_names(...)
| | | | | | | | | | > open_secondary_engine_tables(THD*, unsigned int)
| | | | | | | | | > Sql_cmd_select::prepare_inner(THD*)
| | | | | | | | | | > Query_block::prepare(THD*, mem_root_deque<Item* > *)
| | | | | | | | | | | > Query_block::setup_tables(THD*, TABLE_LIST*, bool)
| | | | | | | | | | | > setup_fields(...)
| | | | | | | | | | | > Query_block::setup_conds(THD*)
| | | | | | | | | | | > Query_block::resolve_limits(THD*)
| | | | | | | | | | | > Query_block::apply_local_transforms(THD*, bool)
| | | | | | | | | | | | > Query_block::simplify_joins(...)
| | | | | | | | > lock_tables(THD*, TABLE_LIST*, unsigned int, unsigned int)
| | | | | | | | > Sql_cmd_dml::execute_inner(THD*)
| | | | | | | | | > Query_expression::optimize(THD*, TABLE*, bool, bool)
| | | | | | | | | | > Query_block::optimize(THD*, bool)
| | | | | | | | | | | > JOIN::optimize(bool)
| | | | | | | | | | | | > JOIN::make_tmp_tables_info()
| | | | | | | | | | | | > count_field_types(...)
| | | | | | | | | | | | > JOIN::create_access_paths()
| | | | | | | | | | | | | > JOIN::create_root_access_path_for_join()
| | | | | | | | | | | | | > JOIN::attach_access_paths_for_having_and_limit(AccessPath*)
| | | | | | | | | | | | | > JOIN::attach_access_path_for_delete(AccessPath*)
| | | | | | | | | > optimize_secondary_engine(THD*)
| | | | | | | | | > Query_expression::execute(THD*)
| | | | | | | | | | > Query_expression::ExecuteIteratorQuery(THD*)
| | | | | | | | | | | > Query_result_send::send_result_set_metadata(...)
| | | | | | | | | | > Query_expression::ExecuteIteratorQuery(THD*)
| | | | | | | | | | | > FakeSingleRowIterator::Read()
| | | | | | | | | | | > Query_result_send::send_eof(THD*)
| | | | | | | > trans_commit_stmt(THD*, bool)
| | | | | | | | > MYSQL_BIN_LOG::commit(THD*, bool)
| | | | | | | | | > ha_commit_low(THD*, bool, bool)
| | | | | > log_slow_statement(THD*, System_status_var*)
从上面的调用栈可以看到,SELECT 1 虽然不需要从表里查询数据,但是词法解析、语法解析、查询准备、查询优化、查询执行、事务提交、记录慢 SQL 等等这些流程一个都没落下,虽然很多方法进去之后,并不需要执行复杂的操作,但是各种 if ... else 判断是少不了要执行的。
SELECT 1 是 select 语句最简单的形式了,如果用其它 select 语句保活,调用栈只会更长。
通过上面 ping 命令 和 SELECT 1 的调用栈对比,相信大家对这两种保活方式的执行效率已经有了直观的了解。
6. 总结
本文写作的初衷就是为了对比 ping 和 select 两种数据库连接保活方式的执行效率。
经过前面的介绍,我们就可以得出结论了:
ping 命令的执行效率比 select 语句高,对于追求极致性能的应用来说,使用 ping 命令给数据库连接保活是更好的方式。
本文转载自微信公众号「一树一溪」,可以通过以下二维码关注。转载本文请联系一树一溪公众号。