基于编码器的自注意力Transformer非常擅长预测自然语言生成任务的下一个字符,因为它们可以注意到给定字符周围的标记/字符的重要性。为什么我们不能应用这个概念来预测任何用户喜欢的给定物品序列中的下一个项目呢?这种推荐问题可以归类为基于物品的协同过滤。
在基于物品的协同过滤中,我们试图找到给定的物品集和不同用户的偏好之间的关系或模式。让我们举个例子,假设我们有两个用户Alice和Bob,每次Alice来我们的网站买她每月的食品杂货,她买牛奶,面包,奶酪,意大利面和番茄酱。

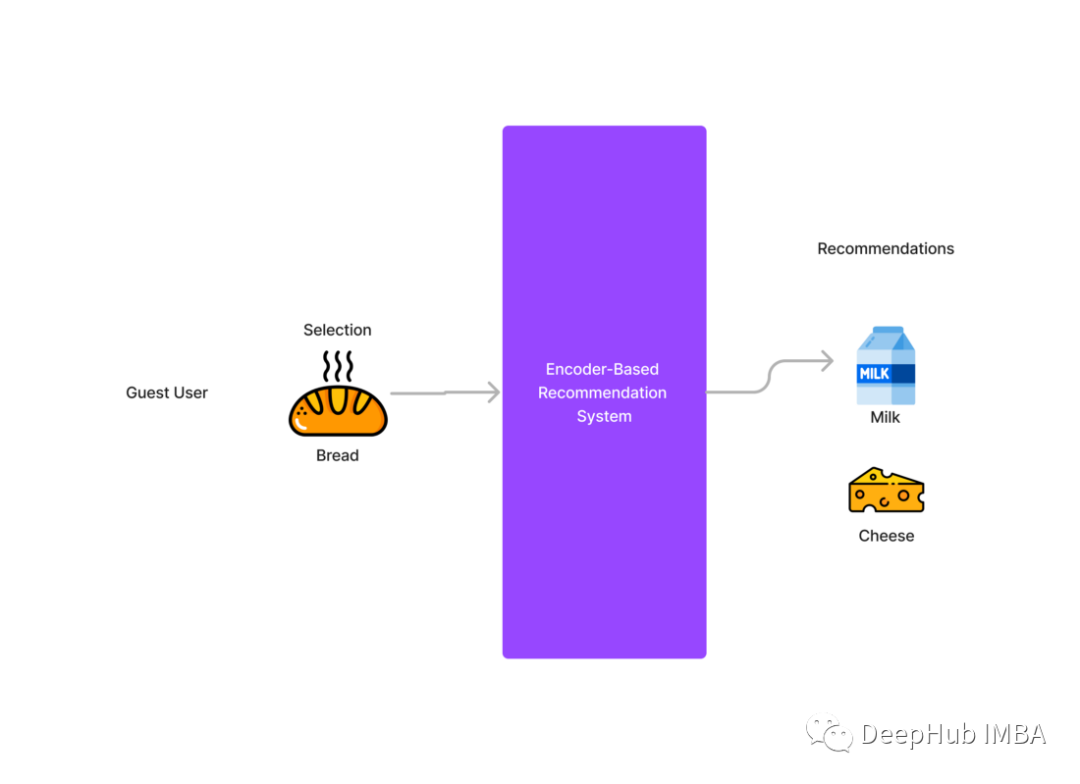
现在我们有一个完全未知的用户,假设叫他Guest来到并向他的购物车中添加面包,现在观察到Guest用户添加了面包,然后我们可以建议用户添加牛奶或奶酪,因为我们从其他用户的历史记录中知道。
我们并不关心用户的类型,比如他们的背景是什么,他们在哪里下单,或者他们的性别是什么。我们只关注每个用户购买或喜欢的物品集。
我们将通过预测给定的物品序列的下一个物品来重新表述推荐问题。这个问题将变得更加类似或完全类似于下一个字符预测或语言建模。我们还可以通过随机屏蔽给定序列中的任何项,并训练基于编码器的Transformer模型来预测被屏蔽的项,从而增加更多的变化。该模型可以从左右两个方向预测物品。
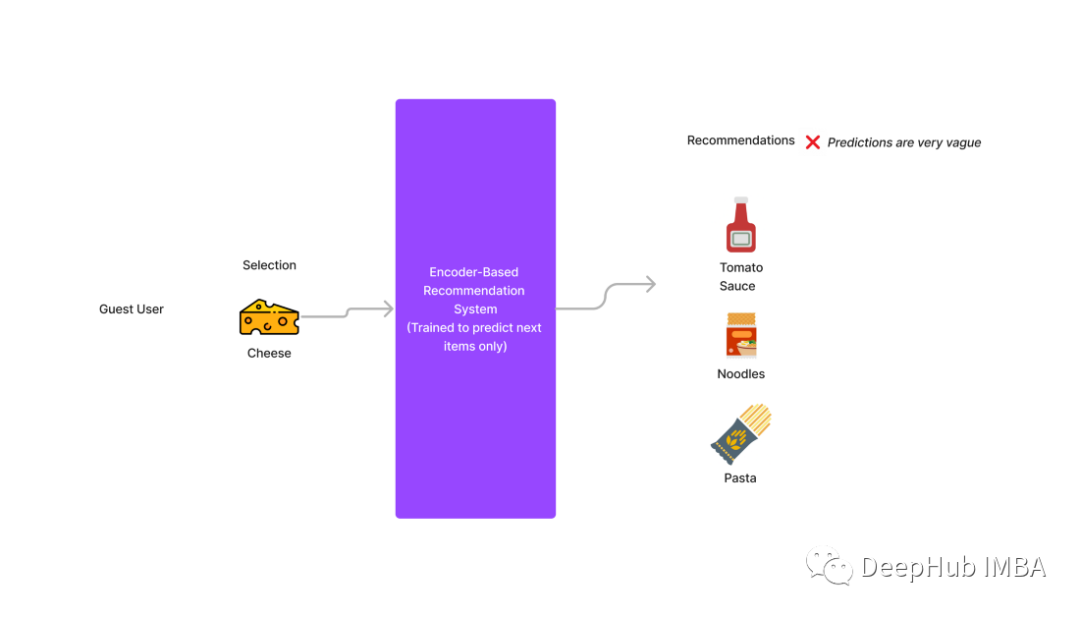
为什么我们要在两个方向上预测?让我们以上面讨论的问题为例。
假设Guest用户直接将奶酪添加到他们的购物车中,那么如果我们只从一个方向进行预测,我们可以向用户推荐番茄酱或面条,但对于这个用户来说,购买这些东西是没有意义的。
但是如果我们的模型以一个给定的顺序预测被遮蔽的物品,我们就可以预测两边,对于Guest用户我们可以建议他添加牛奶、面包或鸡蛋。
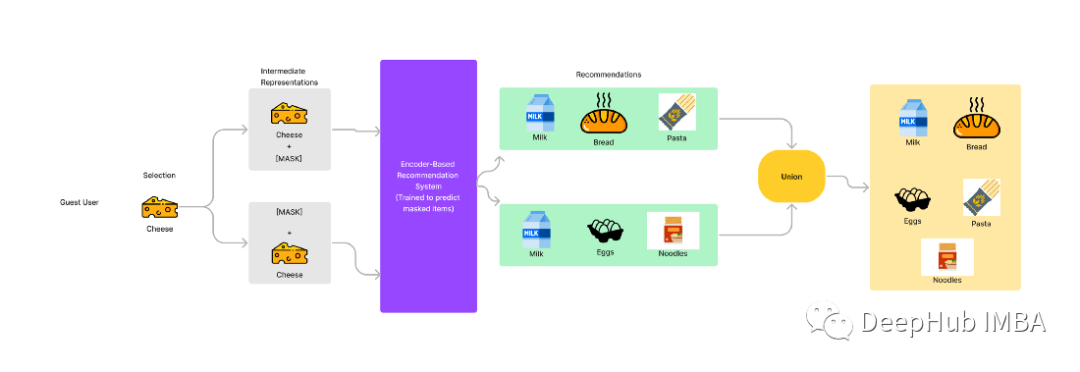
让我们尝试使用这个概念来构建和训练一个我们的模型,预测给定序列中的被屏蔽项。我们将通过下面的一些抽象来讨论代码。这里使用的是MovieLens-25m数据集。
数据预处理
与我们的例子中字符的标识id类似,我们将把每个惟一的电影转换为一个id,从2到电影数量开始。我们将使用id 0作为[PAD], id 1作为[MASK]。
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import sys
sys.path.append("../")
from constants import *
movies_df = pd.read_csv("../data/ml-25m/ml-25m/movies.csv")
ratings_df = pd.read_csv("../data/ml-25m/ml-25m/ratings.csv")
ratings_df.sort_values(by=["timestamp"], inplace=True)
grouped_ratings = ratings_df.groupby(by="userId").agg(list)
movieIdMapping = {k:i+2 for i, k in enumerate(sorted(list(ratings_df.movieId.unique())))}
ratings_df["movieId_mapped"] = ratings_df.movieId.map(movieIdMapping)
movies_df["movieId_mapped"] = movies_df.movieId.map(movieIdMapping)
模型
import os
from requests import head
import torch as T
import torch.nn as nn
import torch.nn.functional as F
from modules import Encoder, Decoder
class RecommendationTransformer(nn.Module):
"""Sequential recommendation model architecture
"""
def __init__(self,
vocab_size,
heads=4,
layers=6,
emb_dim=256,
pad_id=0,
num_pos=128):
super().__init__()
"""Recommendation model initializer
Args:
vocab_size (int): Number of unique tokens/items
heads (int, optional): Number of heads in the Multi-Head Self Attention Transformers (). Defaults to 4.
layers (int, optional): Number of Layers. Defaults to 6.
emb_dim (int, optional): Embedding Dimension. Defaults to 256.
pad_id (int, optional): Token used to pad tensors. Defaults to 0.
num_pos (int, optional): Positional Embedding, fixed sequence. Defaults to 128
"""
self.emb_dim = emb_dim
self.pad_id = pad_id
self.num_pos = num_pos
self.vocab_size = vocab_size
self.encoder = Encoder(source_vocab_size=vocab_size,
emb_dim=emb_dim,
layers=layers,
heads=heads,
dim_model=emb_dim,
dim_inner=4 * emb_dim,
dim_value=emb_dim,
dim_key=emb_dim,
pad_id=self.pad_id,
num_pos=num_pos)
self.rec = nn.Linear(emb_dim, vocab_size)
def forward(self, source, source_mask):
enc_op = self.encoder(source, source_mask)
op = self.rec(enc_op)
return op.permute(0, 2, 1)
训练的流程
import os
import re
import pandas as pd
from tqdm import trange, tnrange
import torch as T
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from bert4rec_dataset import Bert4RecDataset
from bert4rec_model import RecommendationModel, RecommendationTransformer
from rich.table import Column, Table
from rich import box
from rich.console import Console
from torch import cuda
from train_validate import train_step, validate_step
from sklearn.model_selection import train_test_split
from AttentionTransformer.ScheduledOptimizer import ScheduledOptimizer
from IPython.display import clear_output
from AttentionTransformer.utilities import count_model_parameters
import random
import numpy as np
device = T.device('cuda') if cuda.is_available() else T.device('cpu')
def trainer(data_params,
model_params,
loggers,
optimizer_params=None,
warmup_steps=False,
output_dir="./models/",
modify_last_fc=False,
validation=5):
# console instance
console = loggers.get("CONSOLE")
# tables
train_logger = loggers.get("TRAIN_LOGGER")
valid_logger = loggers.get("VALID_LOGGER")
# check if output_dir/model_files available; if not create
if not os.path.exists(output_dir):
console.log(f"OUTPUT DIRECTORY DOES NOT EXIST. CREATING...")
os.mkdir(output_dir)
os.mkdir(os.path.join(output_dir, "model_files"))
os.mkdir(os.path.join(output_dir, "model_files_initial"))
else:
console.log(f"OUTPUT DIRECTORY EXISTS. CHECKING CHILD DIRECTORY...")
if not os.path.exists(os.path.join(output_dir, "model_files")):
os.mkdir(os.path.join(output_dir, "model_files"))
os.mkdir(os.path.join(output_dir, "model_files_initial"))
# seed
console.log("SEED WITH: ", model_params.get("SEED"))
T.manual_seed(model_params["SEED"])
T.cuda.manual_seed(model_params["SEED"])
np.random.seed(model_params.get("SEED"))
random.seed(model_params.get("SEED"))
T.backends.cudnn.deterministic = True
# intialize model
console.log("MODEL PARAMS: ", model_params)
console.log("INITIALIZING MODEL: ", model_params)
model = RecommendationTransformer(
vocab_size=model_params.get("VOCAB_SIZE"),
heads=model_params.get("heads", 4),
layers=model_params.get("layers", 6),
emb_dim=model_params.get("emb_dim", 512),
pad_id=model_params.get("pad_id", 0),
num_pos=model_params.get("history", 120))
# model.encoder.sou
if model_params.get("trained"):
# load the already trained model
console.log("TRAINED MODEL AVAILABLE. LOADING...")
model.load_state_dict(
T.load(model_params.get("trained"))["state_dict"])
console.log("MODEL LOADED")
console.log(f'MOVING MODEL TO DEVICE: {device}')
if modify_last_fc:
new_word_embedding = nn.Embedding(model_params.get("NEW_VOCAB_SIZE"),
model_params.get("emb_dim"), 0)
new_word_embedding.weight.requires_grad = False
console.log(
f"REQUIRES GRAD for `NEW WORD EMBEDDING` set to {new_word_embedding.weight.requires_grad}"
)
new_word_embedding.weight[:model.encoder.word_embedding.weight.size(
0)] = model.encoder.word_embedding.weight.clone().detach()
model.encoder.word_embedding = new_word_embedding
# model.encoder.word_embedding.weight.retain_grad()
console.log(
f"WORD EMBEDDING MODIFIED TO `{model.encoder.word_embedding}`")
model.encoder.word_embedding.weight.requires_grad = True
new_lin_layer = nn.Linear(model_params.get("emb_dim"),
model_params.get("NEW_VOCAB_SIZE"))
new_lin_layer.weight.requires_grad = False
new_lin_layer.weight[:model.lin_op.weight.
size(0)] = model.lin_op.weight.clone().detach()
model.lin_op = new_lin_layer
# model.lin_op.weight.retain_grad()
model.lin_op.weight.requires_grad = True
console.log("MODEL LIN OP: ", model.lin_op.out_features)
model = model.to(device)
console.log(
f"TOTAL NUMBER OF MODEL PARAMETERS: {round(count_model_parameters(model)/1e6, 2)} Million"
)
optim_name = optimizer_params.get("OPTIM_NAME")
if optim_name == "SGD":
optimizer = T.optim.SGD(params=model.parameters(),
**optimizer_params.get("PARAMS"))
elif optim_name == "ADAM":
optimizer = T.optim.Adam(params=model.parameters(),
**optimizer_params.get("PARAMS"))
else:
optimizer = T.optim.SGD(params=model.parameters(),
lr=model_params.get("LEARNING_RATE"),
momentum=0.8,
nesterov=True)
if warmup_steps:
optimizer = ScheduledOptimizer(optimizer, 1e-6,
model_params.get("emb_dim"))
console.log("OPTIMIZER AND MODEL DONE")
console.log("CONFIGURING DATASET AND DATALOADER")
console.log("DATA PARAMETERS: ", data_params)
data = pd.read_csv(data_params.get("path"))
train_data, valid_data = train_test_split(
data, test_size=0.25, random_state=model_params.get("SEED"))
console.log("LEN OF TRAIN DATASET: ", len(train_data))
console.log("LEN OF VALID DATASET: ", len(valid_data))
train_dataset = Bert4RecDataset(train_data,
data_params.get("group_by_col"),
data_params.get("data_col"),
data_params.get("train_history", 120),
data_params.get("valid_history", 5),
data_params.get("padding_mode",
"right"), "train",
data_params.get("threshold_column"),
data_params.get("threshold"),
data_params.get("timestamp_col"))
train_dl = DataLoader(train_dataset,
**data_params.get("LOADERS").get("TRAIN"))
console.save_text(os.path.join(output_dir,
"logs_model_initialization.txt"),
clear=True)
losses = []
for epoch in tnrange(1, model_params.get("EPOCHS") + 1):
if epoch % 3 == 0:
clear_output(wait=True)
train_loss, train_acc = train_step(model, device, train_dl,
optimizer, warmup_steps,
data_params.get("MASK"),
model_params.get("CLIP"),
data_params.get("chunkify"))
train_logger.add_row(str(epoch), str(train_loss), str(train_acc))
console.log(train_logger)
if epoch == 1:
console.log(f"Saving Initial Model")
T.save(
model,
os.path.join(output_dir, "model_files_initial",
model_params.get("SAVE_NAME")))
T.save(
dict(state_dict=model.state_dict(),
epoch=epoch,
train_loss=train_loss,
train_acc=train_acc,
optimizer_dict=optimizer._optimizer.state_dict()
if warmup_steps else optimizer.state_dict()),
os.path.join(output_dir, "model_files_initial",
model_params.get("SAVE_STATE_DICT_NAME")))
if epoch > 1 and min(losses) > train_loss:
console.log("SAVING BEST MODEL AT EPOCH -> ", epoch)
console.log("LOSS OF BEST MODEL: ", train_loss)
console.log("ACCURACY OF BEST MODEL: ", train_acc)
T.save(
model,
os.path.join(output_dir, "model_files",
model_params.get("SAVE_NAME")))
T.save(
dict(state_dict=model.state_dict(),
epoch=epoch,
train_acc=train_acc,
train_loss=train_loss,
optimizer_dict=optimizer._optimizer.state_dict()
if warmup_steps else optimizer.state_dict()),
os.path.join(output_dir, "model_files",
model_params.get("SAVE_STATE_DICT_NAME")))
losses.append(train_loss)
if validation and epoch > 1 and epoch % validation == 0:
valid_dataset = Bert4RecDataset(
valid_data, data_params.get("group_by_col"),
data_params.get("data_col"),
data_params.get("train_history", 120),
data_params.get("valid_history", 5),
data_params.get("padding_mode", "right"), "valid")
valid_dl = DataLoader(valid_dataset,
**data_params.get("LOADERS").get("VALID"))
valid_loss, valid_acc = validate_step(model, valid_dl, device,
data_params.get("MASK"))
valid_logger.add_row(str(epoch), str(valid_loss), str(valid_acc))
console.log(valid_logger)
del valid_dataset, valid_dl
console.log("VALIDATION DONE AT EPOCH ", epoch)
console.save_text(os.path.join(output_dir, "logs_training.txt"),
clear=True)
console.save_text(os.path.join(output_dir, "logs_training.txt"),
clear=True)
训练
# NEW_VOCAB_SIZE=59049
from train_pipeline import trainer
from constants import TRAIN_CONSTANTS
from rich.table import Column, Table
from rich import box
from rich.console import Console
console = Console(record=True)
training_logger = Table(
Column("Epoch", justify="center"),
Column("Loss", justify="center"),
Column("Accuracy", justify="center"),
title="Training Status",
pad_edge=False,
box=box.ASCII,
)
valid_loggger = Table(
Column("Epoch", justify="center"),
Column("Loss", justify="center"),
Column("Accuracy", justify="center"),
title="Validation Status",
pad_edge=False,
box=box.ASCII,
)
loggers = dict(CONSOLE=console,
TRAIN_LOGGER=training_logger,
VALID_LOGGER=valid_loggger)
model_params = dict(
SEED=3007,
VOCAB_SIZE=59049,
heads=4,
layers=6,
emb_dim=256,
pad_id=TRAIN_CONSTANTS.PAD,
history=TRAIN_CONSTANTS.HISTORY,
#trained=
#"/content/drive/MyDrive/bert4rec/models/rec-transformer-model-9/model_files/bert4rec-state-dict.pth",
trained=None,
LEARNING_RATE=0.1,
EPOCHS=5000,
SAVE_NAME="bert4rec.pt",
SAVE_STATE_DICT_NAME="bert4rec-state-dict.pth",
CLIP=2
# NEW_VOCAB_SIZE=59049
)
data_params = dict(
# path="/content/bert4rec/data/ratings_mapped.csv",
# path="drive/MyDrive/bert4rec/data/ml-25m/ratings_mapped.csv",
path="/content/drive/MyDrive/bert4rec/data/ml-25m/ratings_mapped.csv",
group_by_col="userId",
data_col="movieId_mapped",
train_history=TRAIN_CONSTANTS.HISTORY,
valid_history=5,
padding_mode="right",
MASK=TRAIN_CONSTANTS.MASK,
chunkify=False,
threshold_column="rating",
threshold=3.5,
timestamp_col="timestamp",
LOADERS=dict(TRAIN=dict(batch_size=512, shuffle=True, num_workers=0),
VALID=dict(batch_size=32, shuffle=False, num_workers=0)))
optimizer_params = {
"OPTIM_NAME": "SGD",
"PARAMS": {
"lr": 0.142,
"momentum": 0.85,
}
}
output_dir = "/content/drive/MyDrive/bert4rec/models/rec-transformer-model-10/"
trainer(data_params=data_params,
model_params=model_params,
loggers=loggers,
warmup_steps=False,
output_dir=output_dir,
modify_last_fc=False,
validation=False,
optimizer_params=optimizer_params)
预测
import torch as T
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
import os
import re
from bert4rec_model import RecommendationTransformer
from constants import TRAIN_CONSTANTS
from typing import List, Dict, Tuple
import random
T.manual_seed(3007)
T.cuda.manual_seed(3007)
class Recommender:
"""Recommender Object
"""
def __init__(self, model_path: str):
"""Recommender object to predict sequential recommendation
Args:
model_path (str): Path to the model
"""
self.model = RecommendationTransformer(
vocab_size=TRAIN_CONSTANTS.VOCAB_SIZE,
heads=TRAIN_CONSTANTS.HEADS,
layers=TRAIN_CONSTANTS.LAYERS,
emb_dim=TRAIN_CONSTANTS.EMB_DIM,
pad_id=TRAIN_CONSTANTS.PAD,
num_pos=TRAIN_CONSTANTS.HISTORY)
state_dict = T.load(model_path, map_location="cpu")
self.model.load_state_dict(state_dict["state_dict"])
self.model.eval()
self.max_length = 25
def predict(self, inp_tnsr: T.LongTensor, mode="post"):
"""Predict and return next or prev item in the sequence based on the mode
Args:
inp_tnsr (T.LongTensor): Input Tensor of items in the sequence
mode (str, optional): Predict the start or end item based on the mode. Defaults to "post".
Returns:
int: Item ID
"""
with T.no_grad():
op = self.model(inp_tnsr.unsqueeze(0), None)
_, pred = op.max(1)
if mode == "post":
pred = pred.flatten().tolist()[-1]
elif mode == "pre":
pred = pred.flatten().tolist()[0]
else:
pred = pred.flatten().tolist()[-1]
return pred
def recommendPre(self, sequence: List[int], num_recs: int = 5):
"""Predict item at start
Args:
sequence (List[int]): Input list of items
num_recs (int, optional): Total number of items to predict. Defaults to 5.
Returns:
Tuple: Returns the sequence and history if more predictions than max length
"""
history = []
predict_hist = 0
while predict_hist < num_recs:
if len(sequence) > TRAIN_CONSTANTS.HISTORY - 1:
history.extend(sequence)
sequence = sequence[:TRAIN_CONSTANTS.HISTORY - 1]
inp_seq = T.LongTensor(sequence)
inp_tnsr = T.ones((inp_seq.size(0) + 1), dtype=T.long)
inp_tnsr[1:] = inp_seq
pred = self.predict(inp_tnsr, mode="pre")
sequence = [pred] + sequence
predict_hist += 1
return sequence, history
def recommendPost(self, sequence: List[int], num_recs: int = 5):
"""Predict item at end
Args:
sequence (List[int]): Input list of items
num_recs (int, optional): Total number of item to predict. Defaults to 5.
Returns:
Tuple: Returns the sequence and history if more predictions than max length
"""
history = []
predict_hist = 0
while predict_hist < num_recs:
if len(sequence) > TRAIN_CONSTANTS.HISTORY - 1:
history.extend(sequence)
sequence = sequence[::-1][:TRAIN_CONSTANTS.HISTORY - 1][::-1]
inp_seq = T.LongTensor(sequence)
inp_tnsr = T.ones((inp_seq.size(0) + 1), dtype=T.long)
inp_tnsr[:inp_seq.size(0)] = inp_seq
pred = self.predict(inp_tnsr)
sequence.append(pred)
predict_hist += 1
return sequence, history
def recommendSequential(self, sequence: List[int], num_recs: int = 5):
"""Predicts both start and end items randomly
Args:
sequence (List[int]): Input list of items
num_recs (int, optional): Total number of items to predict. Defaults to 5.
Returns:
Tuple: Returns the sequence and history (empty always)
"""
assert num_recs < (
self.max_length / 2
) - 1, f"Can only recommend: {num_recs < (self.max_length / 2) - 1} with sequential recommendation"
history = []
predict_hist = 0
while predict_hist < num_recs:
if bool(random.choice([0, 1])):
# print(f"RECOMMEND POST")
sequence, hist = self.recommendPost(sequence, 1)
# print(f"SEQUENCE: {sequence}")
if len(hist) > 0:
history.extend(hist)
else:
# print(f"RECOMMEND PRE")
sequence, hist = self.recommendPre(sequence, 1)
# print(f"SEQUENCE: {sequence}")
if len(hist) > 0:
history.extend(hist)
predict_hist += 1
return sequence, []
def cleanHistory(self, history: List[int]):
"""History might have multiple repetitions, we clean the history
and maintain the sequence
Args:
history (List[int]): Predicted item ids
Returns:
List[int]: Returns cleaned item id
"""
history = history[::-1]
history = [
h for ix, h in enumerate(history) if h not in history[ix + 1:]
]
return history[::-1]
def recommend(self,
sequence: List[int],
num_recs: int = 5,
mode: str = "post"):
"""Recommend Items
Args:
sequence (List[int]): Input list of items
num_recs (int, optional): Total number of items to predict. Defaults to 5.
mode (str, optional): Predict start or end items or creates a random sequence around the input sequence. Defaults to "post".
Returns:
List[int]: Recommended items
"""
if mode == "post":
seq, hist = self.recommendPost(sequence, num_recs)
elif mode == "pre":
seq, hist = self.recommendPre(sequence, num_recs)
else:
seq, hist = self.recommendSequential(sequence, num_recs)
hist = self.cleanHistory(hist)
if len(hist) > 0 and len(hist) > len(seq):
return hist
return seq
with __name__ == "__main__":
rec_obj = Recommender(TRAIN_CONSTANTS.MODEL_PATH)
rec = rec_obj.recommend(sequence=[2, 3],
num_recs=10)
结果
上面代码我们看到了如何使用Transformer模型(NLP领域的流行模型)来构建基于物品的协同过滤模型。并且通过代码从头开始训练。