大家好,今天给大家介绍一个非常热门的技术,同时也是面试的时候面试官特别喜欢问的一个话题,那就是 SpringCloudAlibaba 的底层原理。
现在大家都知道,SpringCloudAlibaba 风靡 Java 开发行业,各个公司都在用这套技术,所以咱们 Java 工程师出去面试,面试官对 SpringCloudAlibaba 都搞成了面试必问选项了,但凡面试,总会有面试官问问:“兄弟,SpringCloudAlibaba 玩儿过吗?能聊聊 SpringCloudAlibaba 的底层原理吗?”
这个时候你要是一脸懵圈的说:“兄弟,我们玩儿的是 SpringCloud 啊,你后面加个 Alibaba 干什么?这东西什么时候跟阿里扯上钩了?”要是面试时你这么回答,那么恭喜你,基本上面试官应该会借口肚子疼要上厕所,然后 30 分钟就结束这场面试了。
所以说,咱们这篇文章,就是希望各位兄弟别出现上面那种 30 分钟就被迫结束面试的窘迫问题。
今天我们先一步一步的来让大家理解一下 SpringCloudAlibaba 里面都包含哪些技术组件,在系统里都是用来干什么的,然后再给大家分析一下这些技术底层的原理。
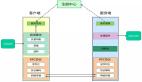
首先,假设你们公司有两个系统,咱们就假设是系统 A 和系统 B 吧,这俩系统现在的需求就是要让系统 A 可以发送一个请求给系统 B 来实现系统间的接口调用。
咱们看下面这个图:

现在有一个最大的问题,系统 A 是部署在一台服务器上的,系统 B 又是部署在另外一台服务器上的,那系统 A 怎么可能莫名其妙的就知道系统B部署在哪台机器上呢?
这就好比说,您在大马路上走着走着,看到一个美女,回家了特别想微信联系她一下,结果您都不知道她的微信号,没加过好友,凭空也没法跟美女搭讪啊!
那跟美女搭讪的正确姿势应该是什么呢?这得有一个前提,就是您有一个中间的朋友,他认识那美女有人家的微信号,这个时候你可以找那中间的朋友要到人家微信号,再根据微信号加人家美女好友,接着就可以实现无缝情感沟通啦!
开个玩笑,上面仅仅是枯燥技术文章中的一个插曲,其实对于您的系统 A 来说,这时就必须引入一个 SpringCloudAlibaba 的关键技术组件,叫做 Nacos。
大家请擦亮眼睛,这个 Nacos 是一个关键名词,一定要记住了,他的学术定位叫做“服务注册中心”。
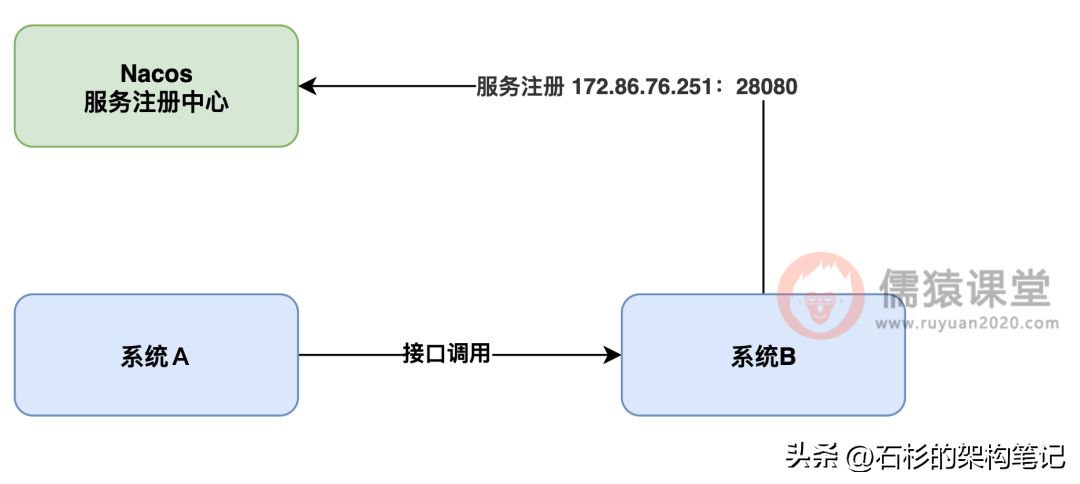
这个 Nacos 就类似上面说的那个有美女微信号的第三方朋友,他是知道你的系统B部署在哪台机器上的,因为系统 B 在启动的时候会主动向 Nacos 服务注册中心进行服务注册,告诉 Nacos 说自己部署在哪台机器上,自己的机器 ip 地址是 172.86.76.251,自己的端口号是 20880。
大家看下图:
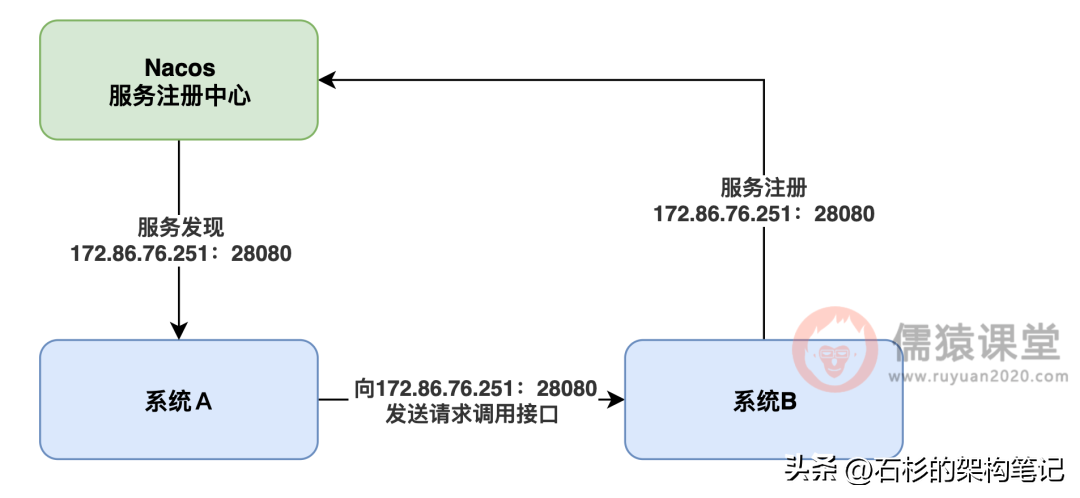
这个时候,系统 A 如果想要调用系统B的接口,就可以发送请求给 Nacos 服务注册中心说,兄弟,能告诉我系统 B 部署在哪台机器上吗?我想调用一下他的接口,这个动作有专业术语,叫做“服务发现”。
然后呢,Nacos 服务注册中心绝对会很大方的把系统 B 的微信号,奥不对,是系统 B 的机器 ip 和端口号都告诉你的。
这时系统 A 知道了系统 B 的 ip 地址和端口号,就可以发送请求过去调用系统 B 的接口了,大家请看下图:
我们再来看下一个问题,假设系统 B 是个大美女,然后还有多个孪生姐妹花,也就是说系统 B 部署在了多台服务器上,我们管这种情况叫做系统 B 有多个服务实例部署在了多台服务器上,然后这个时候系统 A 想要调用系统 B,应该怎么办呢?
我们看下图:
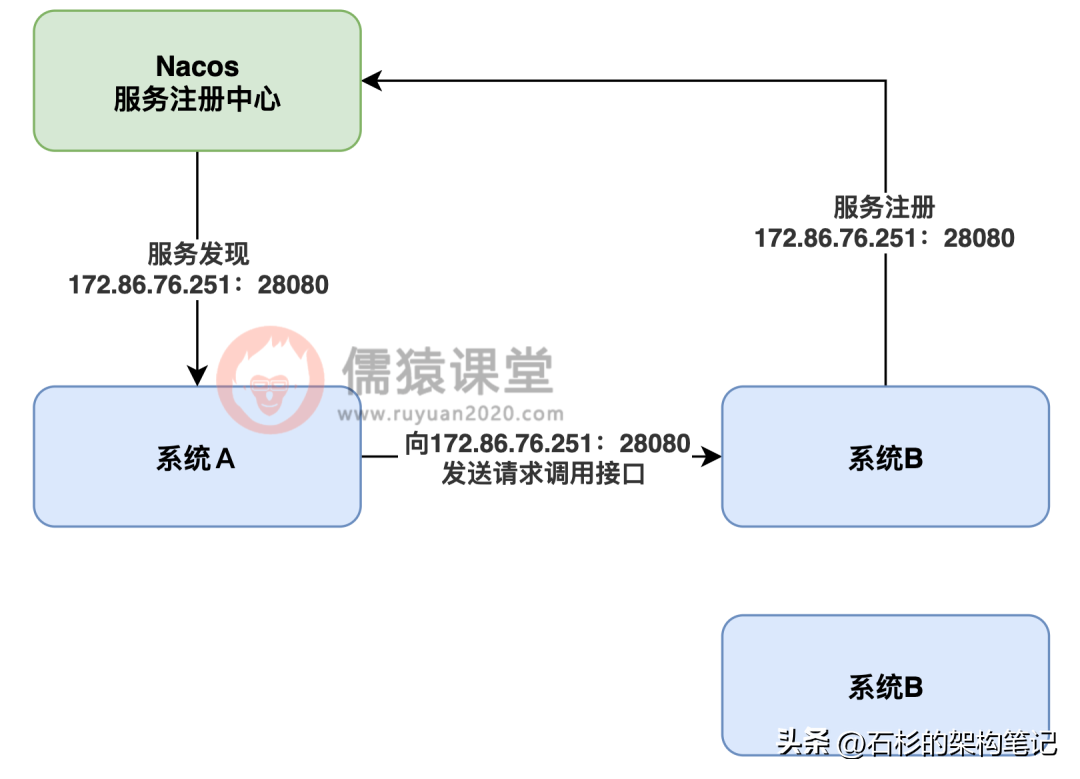
其实也很简单,系统 B 的每个服务实例部署了一台机器后,他们都得对 Nacos 服务注册中心发起服务注册的请求,所以 Nacos 是知道系统 B 部署的每台机器的 ip 地址和端口号的,看下图。
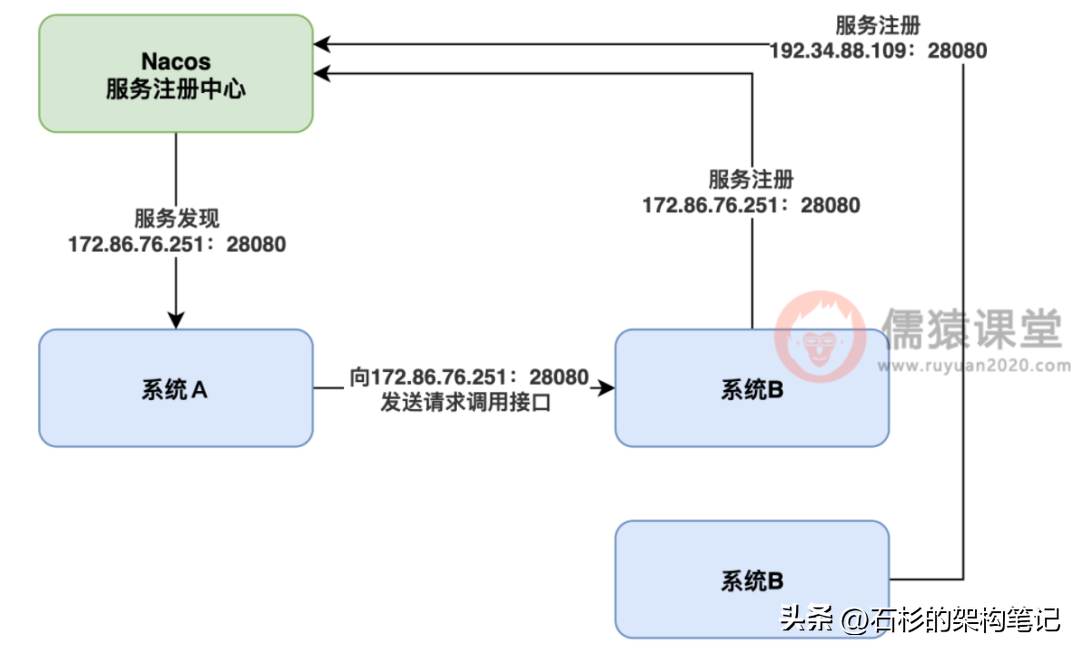
然后这个系统 A 找 Nacos 进行服务发现的时候,一下子就会发现系统 B 部署在了两台机器上,也就是说两台机器的 ip 地址和端口号他都会发现。这个时候问题就来了,系统 A 很犹豫啊,到底调用系统 B 的哪个机器呢?
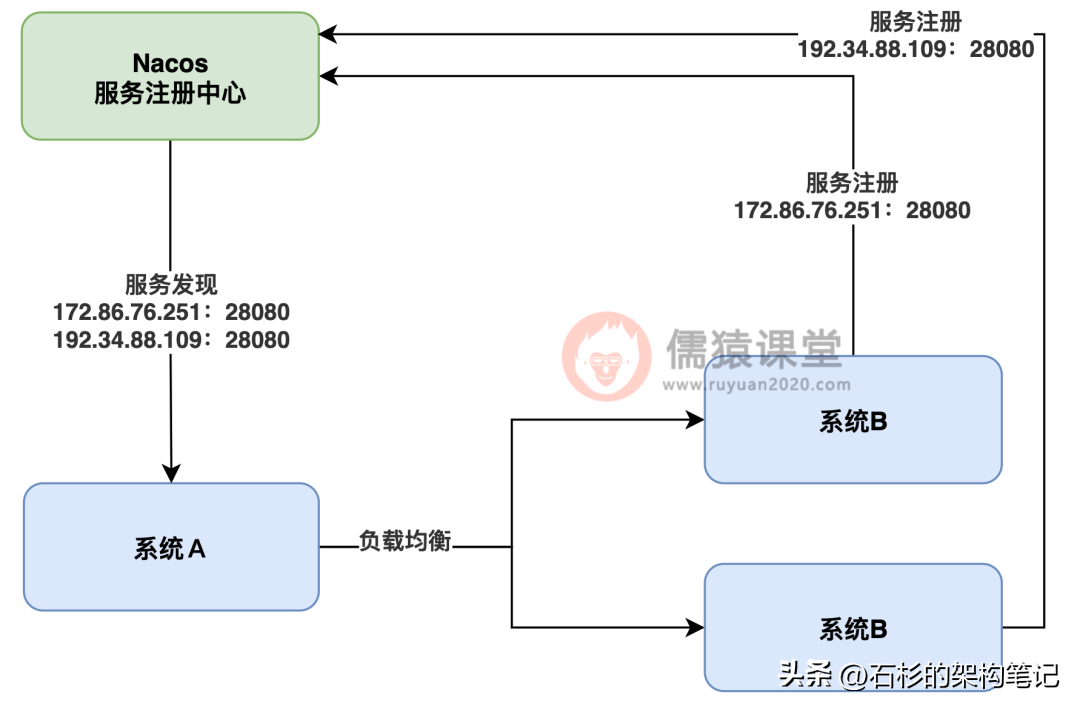
很简单,他可以第一次调用机器 1,第二次调用机器 2,第三次调用机器 1,第四次机器 2,以此类推,循环往复,这个过程叫做负载均衡,系统 A 可以通过负载均衡把自己的所有请求均匀的分发给系统 B 的每台机器,看下图。
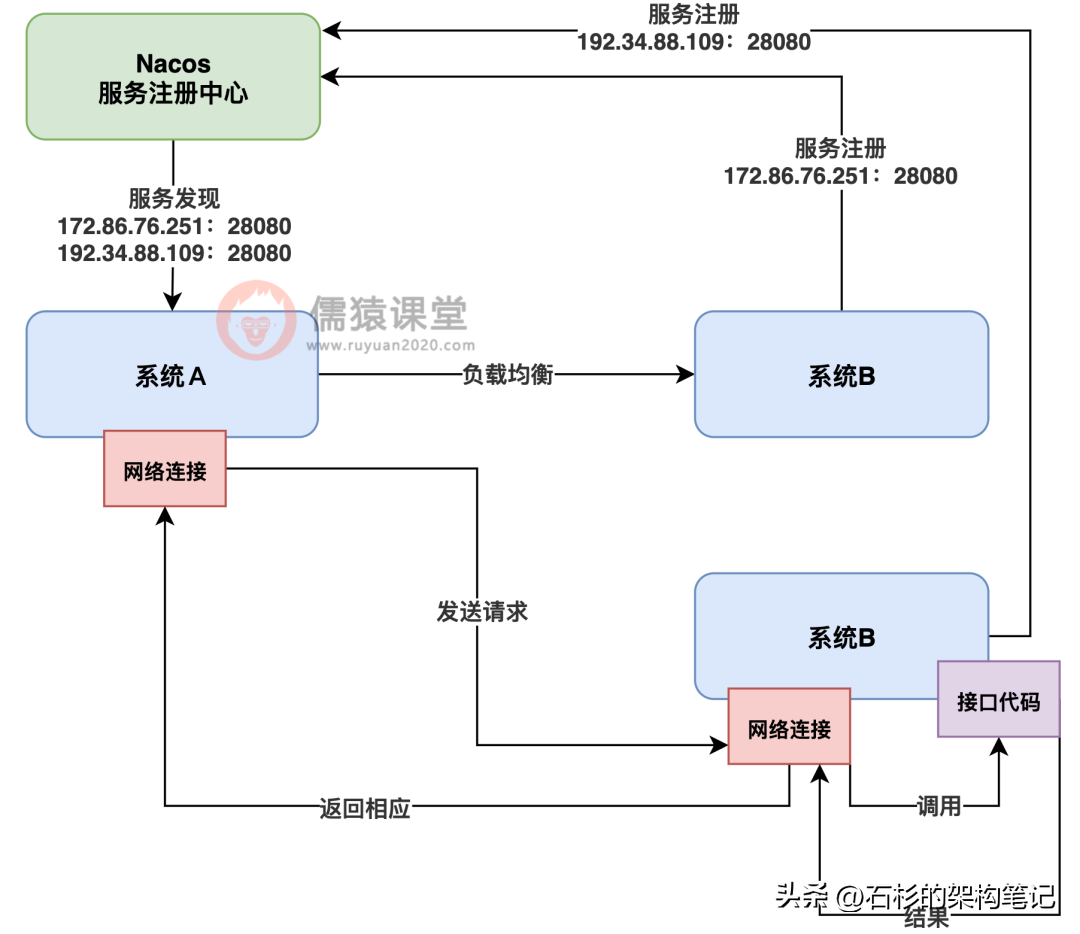
那么下一个问题又来了,系统 A 如果要想办法去调用系统B的某个接口的话,就必须要跟系统 B 建立一个网络连接,然后通过这个网络连接发送请求过去给系统 B。
接着系统 B 收到了请求,以后就会调用自己本地的某个接口的代码,然后再把响应结果通过网络连接返回给系统 A,这个过程就叫做 RPC 远程调用,看下图。
其实这个 RPC 调用的过程,说白了就类似于跟人聊微信的过程,微信聊天你总得先加个好友,完了再发个消息过去,接着人家再给你回一个消息吧?
没错,咱们这 RPC 调用也是同理,你两台机器总得先建立个网络连接,然后系统 A 发个请求过去,系统 B 本地代码执行一下,再返回个响应给你。
那现在问题来了,这个系统 A 那里要对系统 B 部署的多台机器实现负载均衡,然后建立网络连接,接着发起 RPC 调用,就是系统 A 发个请求过去,系统 B 执行一下代码返回个响应,就这套看起来很复杂的流程是谁负责搞定的呢?
简单,就是 SpringCloudAlibaba 里的另外一个关键组件,Dubbo。
这个 Dubbo 就是一个 RPC 的框架,他就是专门负责帮你做负载均衡、网络连接、RPC 调用这些事情的的,这是 SpringCloudAlibaba 组件体系中的第二个关键组件。
大家看下图:
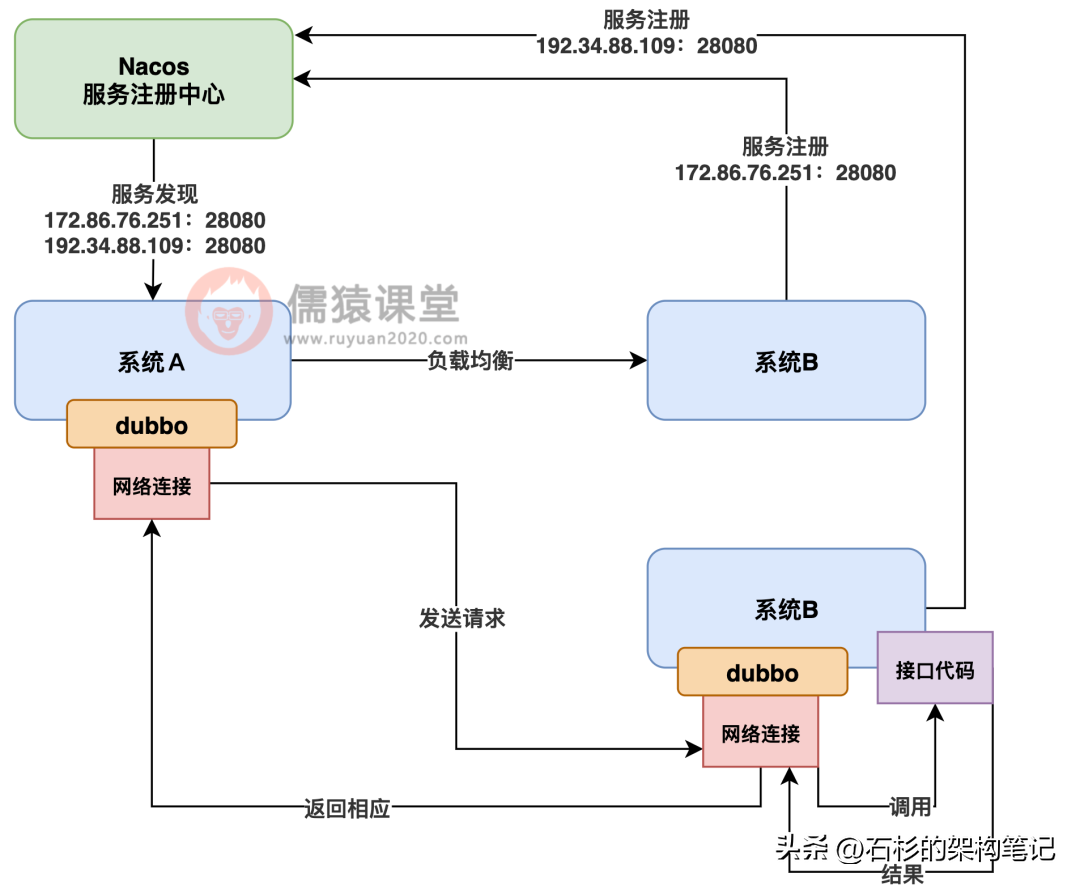
接着再来讨论下一个问题,很多人可能知道,也可能不知道,那就是:一台 4 核 8G 的服务器,每秒钟可以抗多少并发请求?
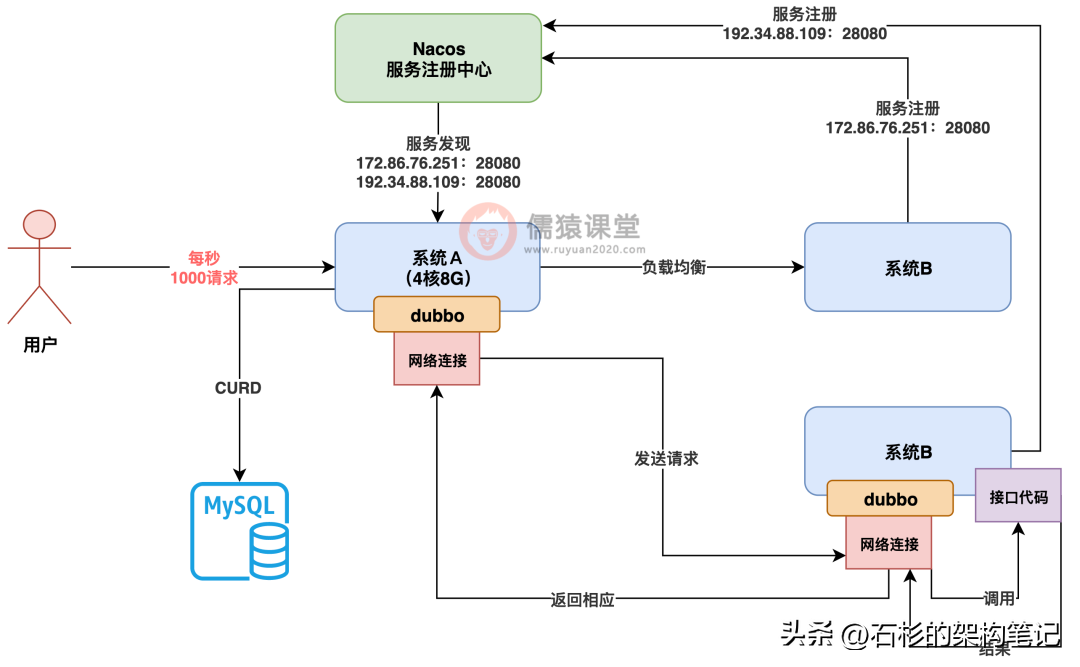
有一些兄弟平时玩儿过高并发系统,应该是知道这个数值的,那就是 4 核 8G 的服务器上部署的如果是一个 java 系统,这个 java 系统连接的是 MySQL 数据库的话,那么通常来说,这一台服务器每秒大致可以抗 1000 以内的 QPS,如下图,每秒 1000 请求我还特意标红了。
这是为什么呢?原因很简单,我们要从两个维度来分析:
第一个维度是,我们的系统 A 有多少个线程来处理请求,每个请求要耗费多少 ms 来完成,每个线程每秒可以执行多少个请求。
第二个维度是,我们系统 A 的 n 多线程拼命处理请求,这个时候会对机器的 CPU 负载造成多大压力,大概所有线程每秒处理多少请求的时候,机器的 CPU 就扛不住了。
把这两个问题解决清楚了,也就知道系统每秒可以抗多少请求了。
首先看第一个维度,系统 A 一般来说对外接受用户的请求,都是通过 Tomcat 这种 web 服务器,对外用 spring mvc 提供 controller 这种接口的,接收的都是 http 请求。
所以实际上 tomcat 一般来说,我们都会配置 200 左右的线程,就是说系统 A 有 200 个线程会并发的处理用户发来的请求,如下图。
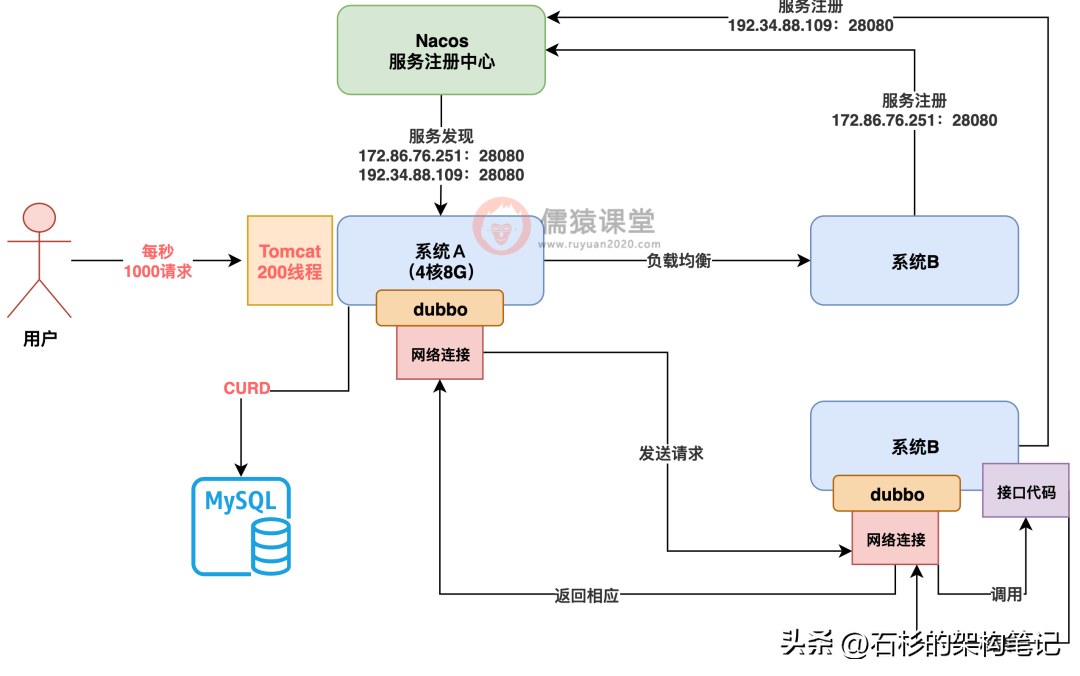
那么下一个问题来了:tomcat 线程处理一个请求要耗费多长时间?
这个就不好说了,因为一个线程处理一个请求的时候,往往会执行你自己写的一大堆业务代码,从 controller 到 service 再到 dao,如果你用 mybatis 做数据持久层框架,那么应该会用 mybatis mapper 执行一大堆的 SQL 语句。
这往往取决于你的系统代码有多复杂,执行的 SQL 语句有多复杂,要执行多少个 SQL,数据库里的表数据是万级、十万级、还是百万级,甚至是千万级、亿级。
所以影响因素太多,我们这里取一个不多不少的均值,假设你一个请求需要调用 n 多次数据库,执行 n 个 SQL 语句,而且数据库里的数据量还小,基本在十万到百万级,那么此时大概你一个请求处理要耗费 200ms,如下图。
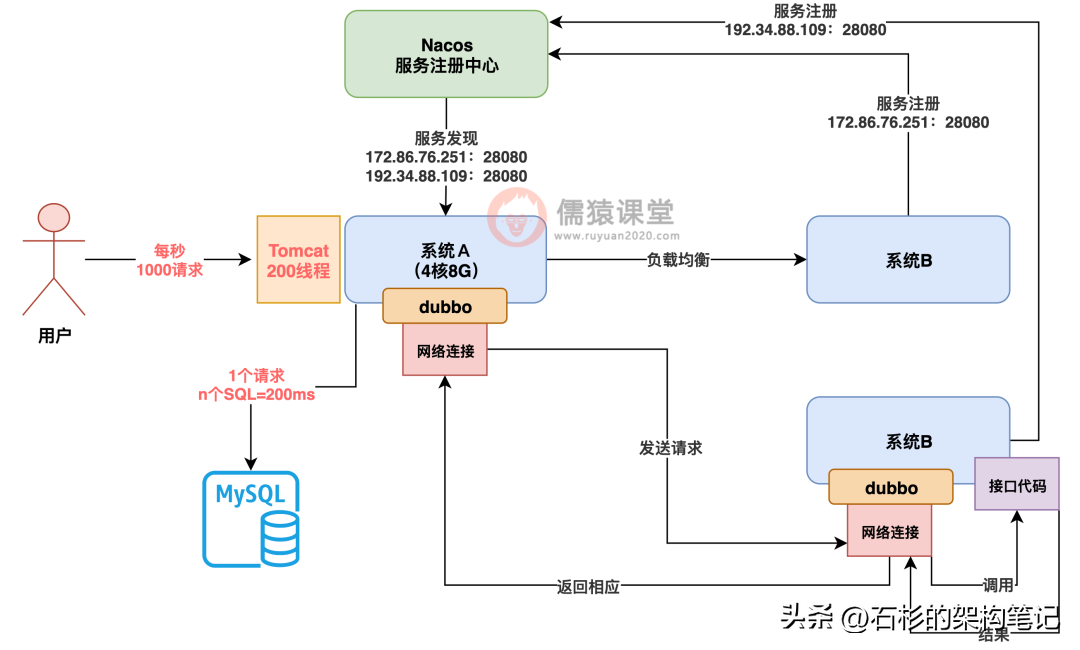
所以一个简单的小学公式就可以计算出来了,你一个线程处理一个请求要耗费 200ms,那么每秒就可以处理 5 个请求,你有 200 个线程,每秒可以处理 200*5=1000 个请求,这个小学生级别的算数大家没问题吧?
所以说,按这个维度来说,系统 A 部署在 4 核 8G 的系统上,连接了 MySQL 数据库,然后开 200 个 tomcat 线程处理请求,每秒处理 1000 个请求是比较合理的。
第二个维度呢?就是 CPU 负载这个角度来看,其实也是差不多的,这个没法用算数来计算,只能告诉大家一个经验值,那就是当你的系统部署在 4 核 8G 机器上,连接 MySQL 数据库,然后每个请求都要执行一堆 SQL 语句的时候,往往你的系统每秒处理到 1000 左右的请求量,你的机器 CPU 负载就会达到 80% 甚至 90% 的使用率,这个时候系统负载已经很高了,再让机器处理更多请求,他已经完全就做不到了。
好,那么针对这个系统 A 每秒可以处理 1000 个请求的经验值,我们来考虑一个问题,万一要是你公司搞个活动,突然之间每秒有 2000 个请求过来,或者是被黑客来了个攻击,每秒的请求数量特别多,这个时候你怎么办?
显而易见你的系统 A 会被打死,如下图:
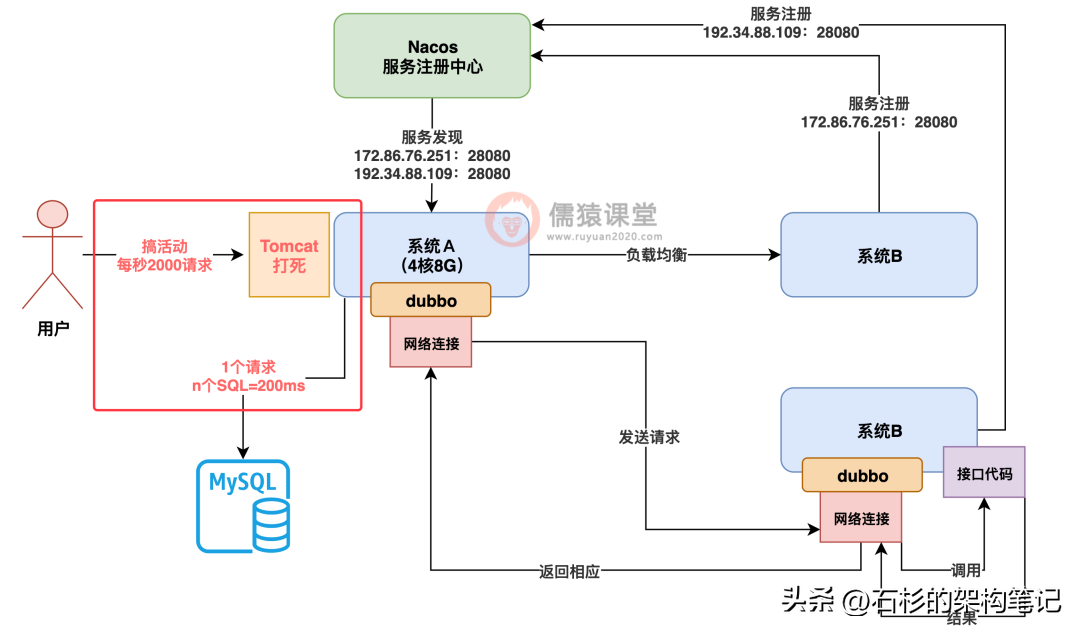
所以这个时候怎么办呢?我们就得引入 SpringCloudAlibaba 里的第三个组件了,就是 Sentinel,这个 Sentinel 就是帮助你的系统实现流量防护的。
当你在系统 A 里加入 Sentinel 以后,如果要是每秒请求超过了 1000,Sentinel 会直接帮你把多出来的那些请求都直接拒绝掉,这就叫做限流,限制你的系统可以处理的请求数量,这样就可以保护你的系统不会被打死,如下图。
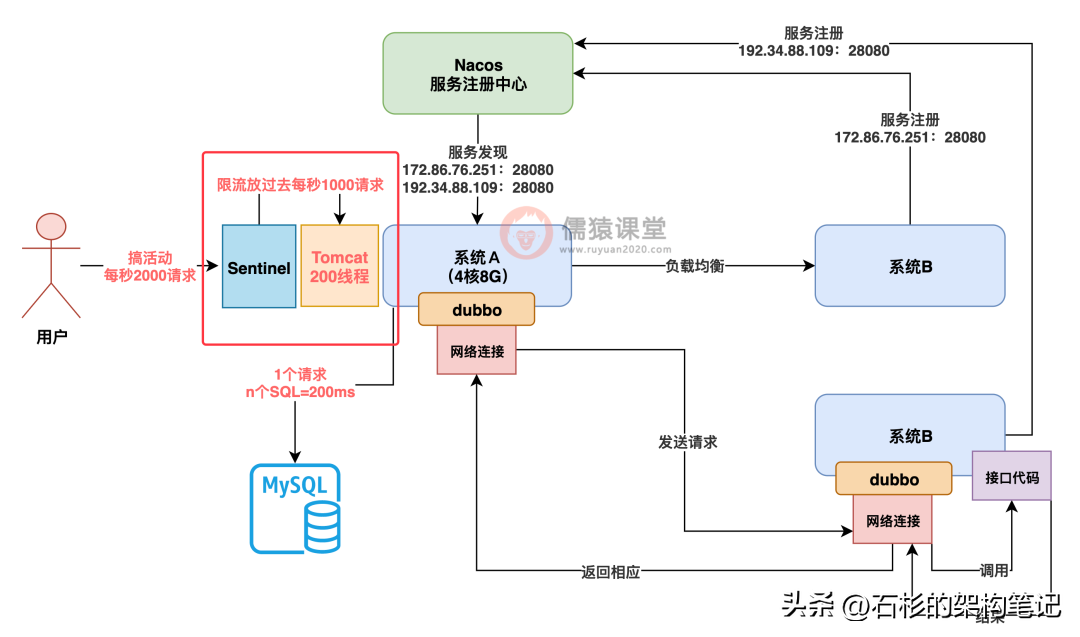
那现在我们已经搞明白 SpringCloudAlibaba 里的三个组件的运行原理和使用场景了,Nacos 是服务注册中心,Dubbo 是 RPC 调用框架,Sentinel 是流量防护组件,接着来看最后一个组件,那就是 Seata,分布式事务组件。
既然提到了分布式事务,那就肯定是跟事务是有关系的了,这个事务相信大家都知道,就是我们对 MySQL 可以开启一个事务,事务里执行 n 条 SQL,但凡有一个 SQL 失败了,事务就会回滚,这 n 个 SQL 都不会生效的。
可是在系统 A 调用系统 B 这种分布式的场景下,事务会怎么样呢?
大家看下图,假设系统 A 处理一个请求的时候,先对自己的数据库执行了一堆 SQL,提交了事务 A,然后通过 Dubbo 发起 RPC 调用系统 B,系统 B 对自己的数据库执行了一堆 SQL,提交了事务 B。
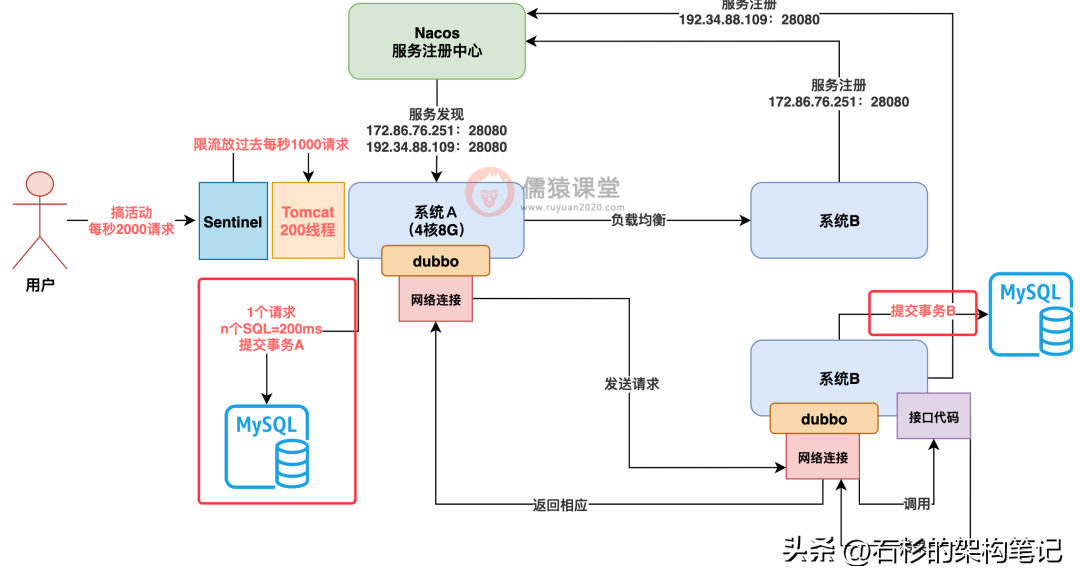
那么现在问题来了,假设我系统 A 的事务 A 都提交了,结果到系统 B 的时候,事务 B 执行失败,事务 B 回滚了,这可怎么整?
也就是说一个请求的处理不一致了,一个系统的事务成功都提交完了,没法回滚了,另外一个系统的事务失败了!
别着急,只要你引入 Seata 分布式事务框架,就可以轻松搞定这个问题,Seata 这个框架会自动记录你的事务 A 执行的 SQL 语句的逆向补偿 SQL。
什么意思呢?假设你事务 A 执行的是 insert,那么 Seata 就知道补偿的时候可以 delete 删除。
假设你执行的是 update,那么 Seata 就可以记录你 update 之前的老数据,补偿的时候可以把数据重新 update 回老版本数据,而且这个逆向补偿日志也是记录在数据库里的,如下图。
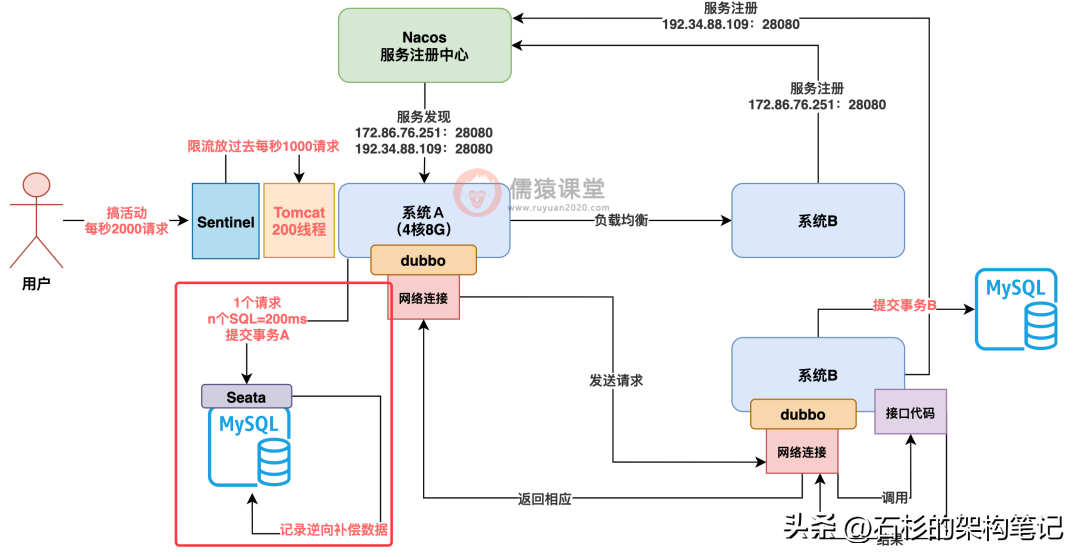
接着 Seata 还会提供一个 Seata server 来监控你的各个系统的事务执行情况,系统 A 的事务 A 执行成功了得告诉 Seata server,系统 B 的事务 B 执行失败了也得告诉 Seata server,如下图。
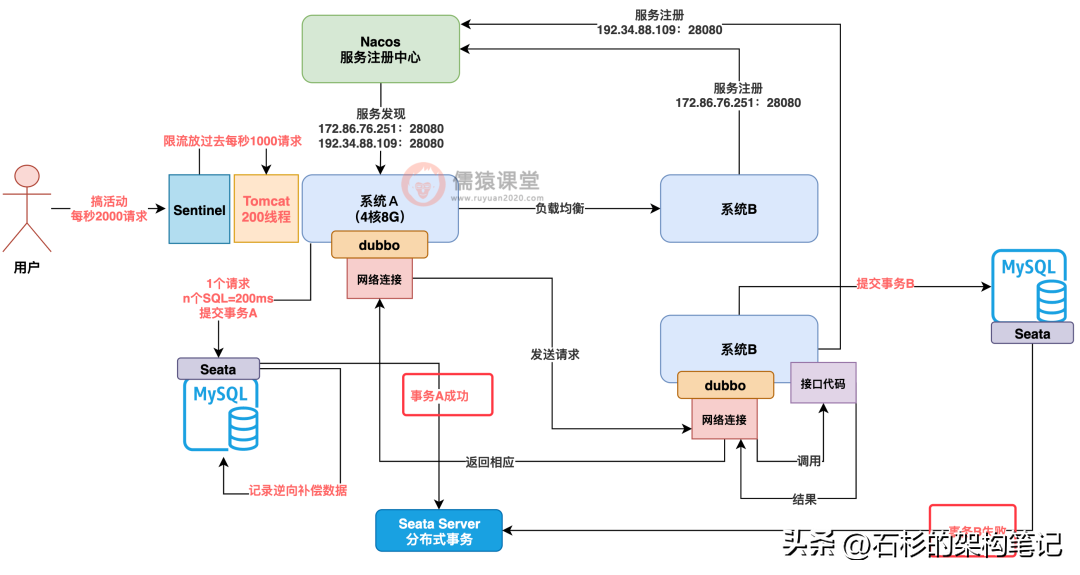
当 Seata server 知道你的系统 B 的事务 B 执行失败了,他会告诉系统 A 里的 Seata 框架,小兄弟,人家系统 B 都失败了,你赶紧的吧,别墨迹,把你之前记录的事务 A 逆向补偿日志拿出来,把你之前提交的事务恢复到提交前的数据状态,搞一个逆向回滚,如下图。
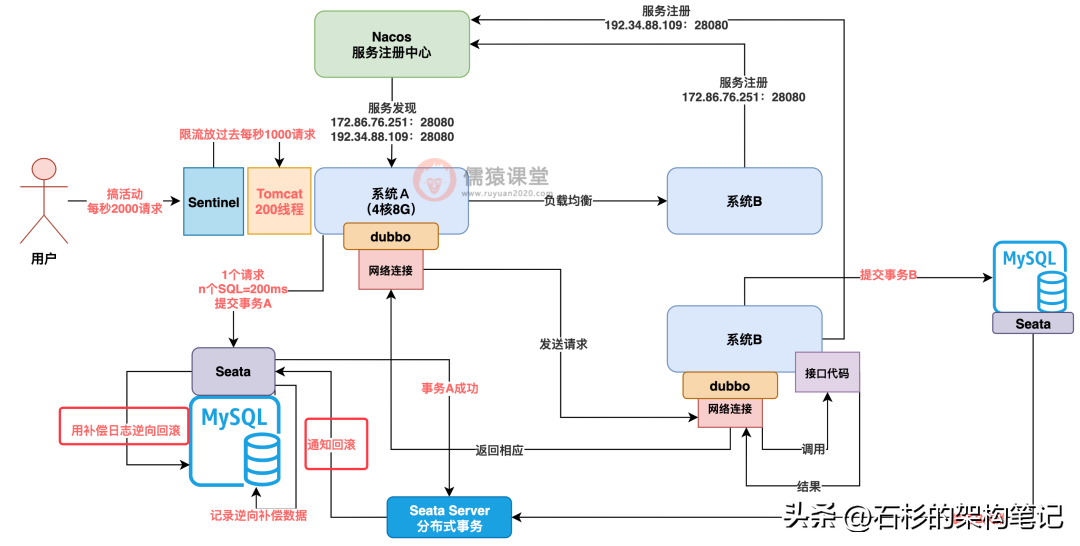
好了,到此为止,就给大家把 SpringCloudAlibaba 组件体系的几个组件的使用场景和工作原理介绍清楚了,包括 Nacos 服务注册中心、Dubbo RPC 调用框架、Sentinel 流量防护组件、Seata 分布式事务组件,大家看看上面的那个图,是不是很有成就感?