














1、引言
用户画像,即用户信息标签化,它本质是对用户的一种建模,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息,在现如今应用越来越广泛。本文主要讲述用户画像在离线、实时方面的数据链路处理以及基于特定场景要求如何将离线、实时画像进行在线融合的过程。
2、背景
目前的算法画像服务分为两部分,一部分是离线画像,也就是批处理计算层,依赖DataWorks每天T+1的调度处理。批处理层是通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复数据错误;另一部分是实时画像,它的数据处理依赖流式计算层Flink。根据用户实时的行为数据进行流式处理实时更新用户画像。由于两种模式提供的状态差异,所以需要我们为批处理和流处理提供不同的服务层并在这个上面做合并处理。基于此,需要我们基于离线和实时画像进行融合处理。
整个的数据链路大致如下:
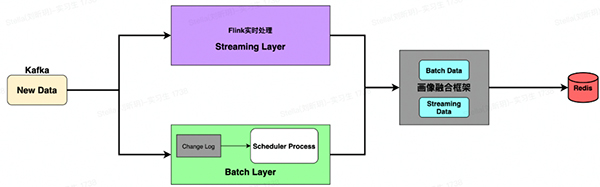
主要分为三部分:批处理层、流处理层、数据融合层。接下来逐一讲解每层的数据链路处理。
3、批处理层
批处理层依赖于定时调度,基于用户日常的行为数据通过批处理过程以精确地计算用户的离线画像。离线画像一方面用作补充实时链路的数据问题;另一方面是当用户冷启动时,如何进行用户画像的补充,在算法侧请求时能够拿到这部分用户的画像。同时在离线画像数据加工完成后,需要考虑将这部分ODPS中的离线画像及时地更新到用户画像服务中。在这里我们采取懒加载的方式,将离线画像存储到HBASE中,后续基于用户当天第一次启动App时,将用户的离线画像进行加载,这部分懒加载流程会在下文讲解。
数据链路如下:
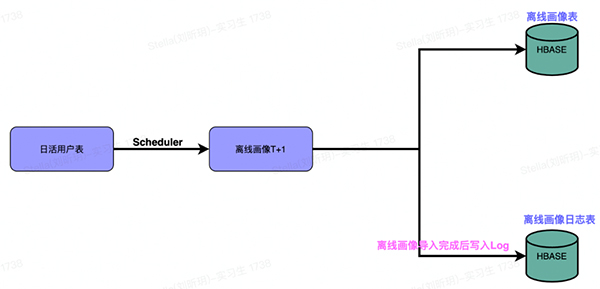
主要分为两个部分:
a、每天定时调度生成日活用户的离线画像T+1,导入HBASE中。
b、基于步骤1的完成,向HBASE中记录一条Log,代表当天T+1的离线画像已经成功写入,Log中包含当天画像的数据量、画像的版本号及完成时间。这里的Log实际是作为标志位,用于判断T+1画像的完整性,后续懒加载流程会利用当天的Log来判断是否加载离线画像以及加载几次。
4、流处理层
这里的流处理层分为两块,一块是实时画像,订阅用户的实时行为数据进行Flink处理而来;另一块实际是对批处理层提供的离线画像进行处理,基于用户的实时登录行为懒加载离线画像。
上文提到在批处理层将用户离线画像导入HBASE后,通过懒加载的方式将离线画像加载到画像融合框架。
整个懒加载流程如下:
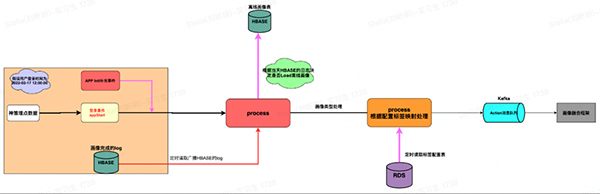
大致分为如下几个步骤:
a、订阅用户的登录行为埋点APPSTART。
b、根据订阅的用户登录行为加载HBASE中的离线画像。这里有一点需要说明的就是上述提到HBASE中的画像Log记录,利用Log来判断是否需要加载画像。假设当天T+1的画像已经完整的导入到HBASE中,当天用户第一次登录时,就会Load离线画像,同时利用Flink的State记录当天用户已经加载了T+1画像,后续用户当天再次登录时就不会再Load离线画像,做到当天只加载一次T+1画像,降低HBASE的访问压力;相反如果用户当天登录时,T+1画像并没有Log记录, Load画像时State会记录用户当天加载了T+2画像,后续只有当T+1画像完成后用户再次登录,才会去获取一次最新的离线画像,同时更改State记录。
c、读取标签配置表,根据对应标签的配置信息将画像的格式、类型进行转换满足算法侧的使用。
d、将转换后的画像统一成画像框架消费的Action格式发送到消息队列中,供后续融合框架消费和实时画像进行融合。
懒加载的流程整体上就是上面所述,在这里有一点补充就是步骤1中订阅的用户登录埋点APPSTART。在实际中由于受到埋点上报延迟、网络等一系列原因,可能会导致部分用户离线画像加载的延迟,用户请求时离线画像尚未加载到,造成画像覆盖率降低。基于此,我们通过订阅用户的Init数据(先于推荐流请求)作为补充触发事件来加载离线画像,从而进一步提升画像覆盖率。
另外就是Log中版本号的概念,主要是为了容错,防止出现画像数据版本当天迭代更新。我们要求每次迭代version都要对应+1,这样当用户登录时假如当天的version出现了变化会再次加载最新的版本画像,从而保障用户加载的离线画像版本是最新的。
接下来看下实时画像的数据链路,整个流程如下:

大致分为如下几个步骤:
1)Flink订阅用户行为数据,根据画像具体的业务要求处理行为数据。
2)将处理后的行为数据构建画像框架统一的Action算子发送到Kafka中。Action中包含标签名称、标签值、标签对应的处理算子、行为时间等相关信息。
3)画像框架消费Action信息,根据配置的信息做对应的算子类型处理。比如map、List、String等一系列类型处理。
4)将处理后的实时画像写入Redis。 离线画像的懒加载流程和实时画像处理流程大致如上,最终目的是要按照框架Action格式发送到Kafka中供画像框架融合使用,达到离线和实时画像的合并。
5、画像融合层
基于批处理层和流处理层的画像数据,我们需要将离线画像和实时画像进行融合处理。
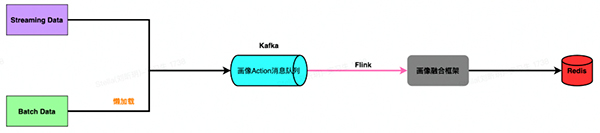
首先需要明确的一点就是离线、实时画像的数据格式一定要统一,否则谈不上融合。同时在数据处理的口径上也是要统一的,这样做的好处是校验数据时容易追溯、定位问题。
那如何进行画像融合呢?这里以具体的标签举例。假如标签a是用户的点击行为序列List,序列中包含用户点击商品cspuId、用户行为时间、商品推荐渠道等信息。标签a的数据格式如下:
在画像配置表中,我们首先会配置标签a的相关信息,比如sizeLimt为1000,排序字段为et,按照cspuId、et两个字段去重等等信息。
在实时画像层,我们知道用户实时的点击行为会产生实时的点击画像数据,假设产生的实时画像数据如下:
基于这个实时画像数据我们会构建统一的Action格式算子,实时的标签a配置的处理算子是 list.rpush,代表将针对a标签进行List的add操作。
在懒加载层,加载到的离线标签a的数据格式如下:
基于这个离线画像我们也会构建统一的Action格式算子,离线标签a配置的处理算子是 list.rpushl,代表对a标签进行List的addAll操作。
画像融合框架消费Action消息队列时,由于TTL的原因,假设Redis中用户的a标签数据已经清空,在用户冷启动时画像框架会根据消费到的离线标签数据及对应的操作算子将a标签数据补充完整。与此同时用户后续产生了上述实时的画像,同样道理根据对应的操作算子将实时画像add到标签a中,当然会根据标签a的配置信息比如大小,排序字段等取最近的sizeLimit画像。
另外比如用户的a标签中数据已经有历史累积了,这时候离线画像可以用作数据修复。画像融合框架拿到离线画像会结合已经存在的a标签数据进行去重,按照et排序等一系列操作,补充实时链路可能出现的数据丢失问题,最终得到完整的上述a标签数据。
考虑到不同类型标签的操作差异,画像融合框架会根据需求定制不同的操作算子,这样可以很灵活地处理算法侧不同的标签需求。
基于此,通过简单的标签举例,能够了解整个画像融合的过程。当然实际中还有更多细节问题可以后续进一步分享。
6、总结
整个离线、实时画像的融合链路整体上如上所述。从数据准备、数据加工、数据融合到最终提供完整画像,实际上类似于Lambda架构。当然在批处理层,考虑到不同业务域对T+1日活画像完整性的要求,我们采用了不同的处理方式。比如直接将这部分日活画像写到Redis中而不是通过懒加载方式去更新,这样可以让算法侧自身去结合实际场景融合使用。另外一点就是在批处理层是否能够进一步优化,降低维护成本,比如HBASE的中间存储,目前也在探索基于每天生成离线画像的snapshot,直接从ODPS进行Load使用,也是在进一步探索如何充分利用离线画像的同时降低开发成本。




























