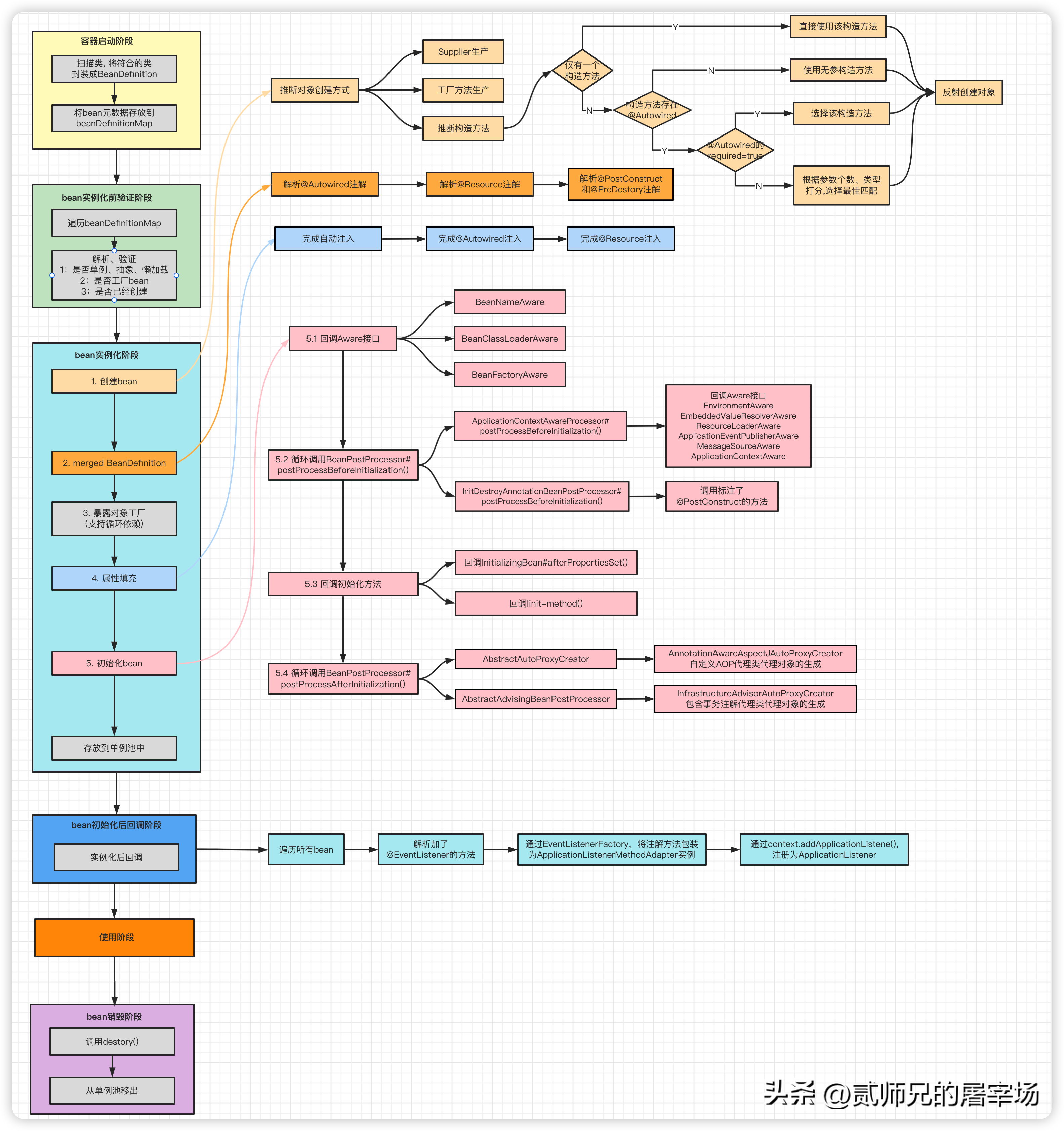
在对于Spring的所有解读中,Bean的生命周期都可谓是重中之重,甚至还有人称Spring就是个管理Bean的容器。Bean的生命周期之所以这么重要,被反复提及,是因为Spring的核心能力,比如对象创建(IOC)、属性注入(DI)、初始化方法的调用、代理对象的生成(AOP)等功能的实现,都是在bean的生命周期中完成的。清楚了bean的生命周期,我们才能知道Spring的神奇魔法究竟是什么,是怎么一步步赋能,让原本普通的java对象,最终变成拥有超能力的bean的。
1. bean的生命周期
Spring的生命周期大致分为:创建 -> 属性填充 -> 初始化bean -> 使用 -> 销毁 几个核心阶段。我们先来简单了解一下这些阶段所做的事情:
创建阶段主要是创建对象,这里我们看到,对象的创建权交由Spring管理了,不再是我们手动new了,这也是IOC的概念。
属性填充阶段主要是进行依赖的注入,将当前对象依赖的bean对象,从Spring容器中找出来,然后填充到对应的属性中去。
初始化bean阶段做的事情相对比较复杂,包括回调各种Aware接口、回调各种初始化方法、生成AOP代理对象也在该阶段进行,该阶段主要是完成bean的初始化工作,后面我们慢慢分析。
使用bean阶段,主要是bean创建完成,在程序运行期间,提供服务的阶段。
销毁bean阶段,主要是容器关闭或停止服务,对bean进行销毁处理。
当然,bean的生命周期中还包括其他的流程,比如合并beanDefinition、暴露工厂对象等,只是相对而言都是为其他功能做伏笔和准备的,在讲到对应功能时,我们在做详细分析。
1.1 创建bean
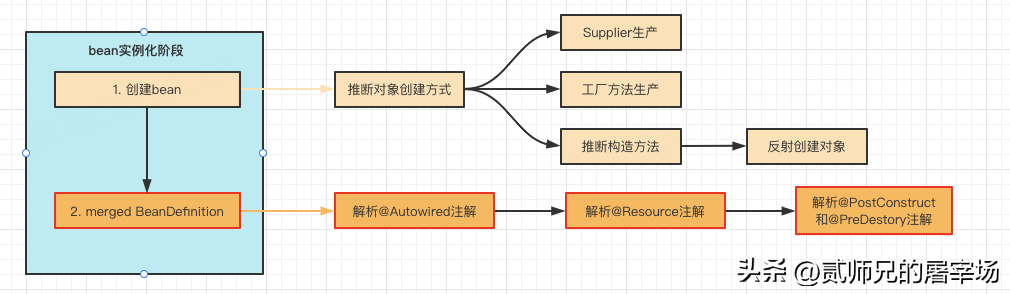
对象的创建是bean生命周期的第一步,毕竟要先有1才能有0嘛。创建对象的方式有很多,比如 new、反射、clone等等,Spring是怎么创建对象的呢?绝大多数情况下,Spring是通过反射来创建对象的,不过如果我们提供了Supplier或者工厂方法,Spring也会直接使用我们提供的创建方式。
我们秉持一贯的风格,从源码出发,看一下Spring是如何选择创建方式的:
// 源码位于 AbstractAutowireCapableBeanFactory.java
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// 再次解析BeanDefinition的class,确保class已经被解析
Class<?> beanClass = resolveBeanClass(mbd, beanName);
// 1: 如果提供了Supplier,通过Supplier产生对象
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
// 2: 如果有工厂方法,使用工厂方法产生对象
// 在@Configration配置@Bean的方法,也会被解析为FactoryMethod
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
//...省略部分代码
// 3: 推断构造方法
// 3.1 执行后置处理器,获取候选构造方法
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
// 3.2 需要自动注入的情况
if (ctors != null || mbd.getResolvedAutowireMode() == AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// 3.3 默认使用没有参数的构造方法
return instantiateBean(beanName, mbd);
}
经过我们跟踪源码,发现Spring推断创建方式还是比较聪明的,具体逻辑是:
- 先判断是否提供了Supplier,如果提供,则通过Supplier产生对象。
- 再判断是否提供工厂方法,如果提供,则使用工厂方法产生对象。
- 如果都没提供,需要进行构造方法的推断,具体逻辑为:
如果仅有一个构造方法,会直接使用该构造方法(如果构造方法有参数,会自动注入依赖参数)
如果有多个构造方法,会判断有没有加了@Autowired注解的构造方法:
如果没有,Spring默认选择无参构造方法;
如果有,且有@Autowired(required=true)的构造方法,就会选择该构造方法;
如果有,但是没有@Autowired(required=true)的构造方法,Spring会从所有加了@Autowired的构造方法中,根据构造器参数个数、类型匹配程度等综合打分,选择一个匹配参数最多,类型最准确的构造方法。
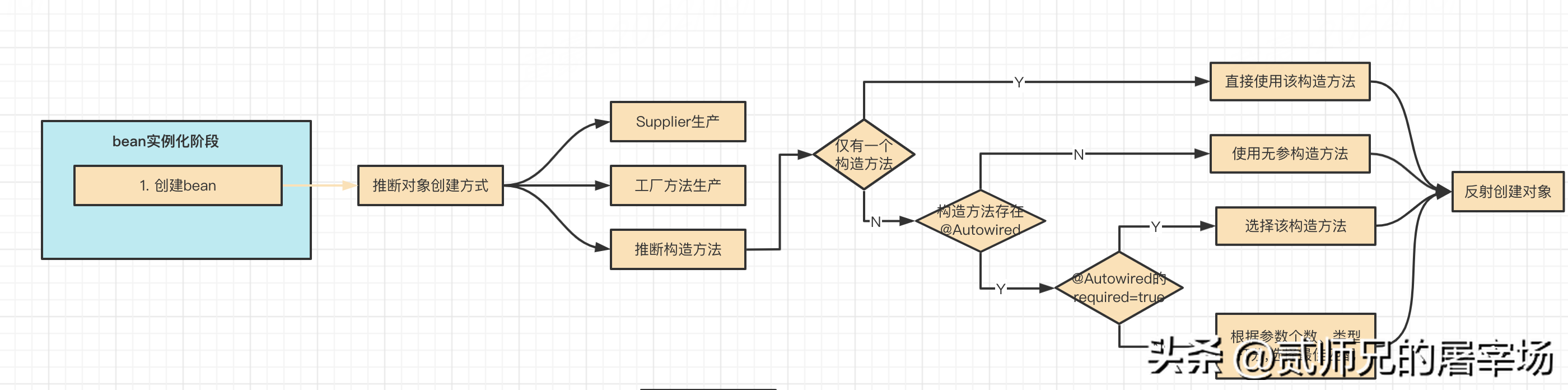
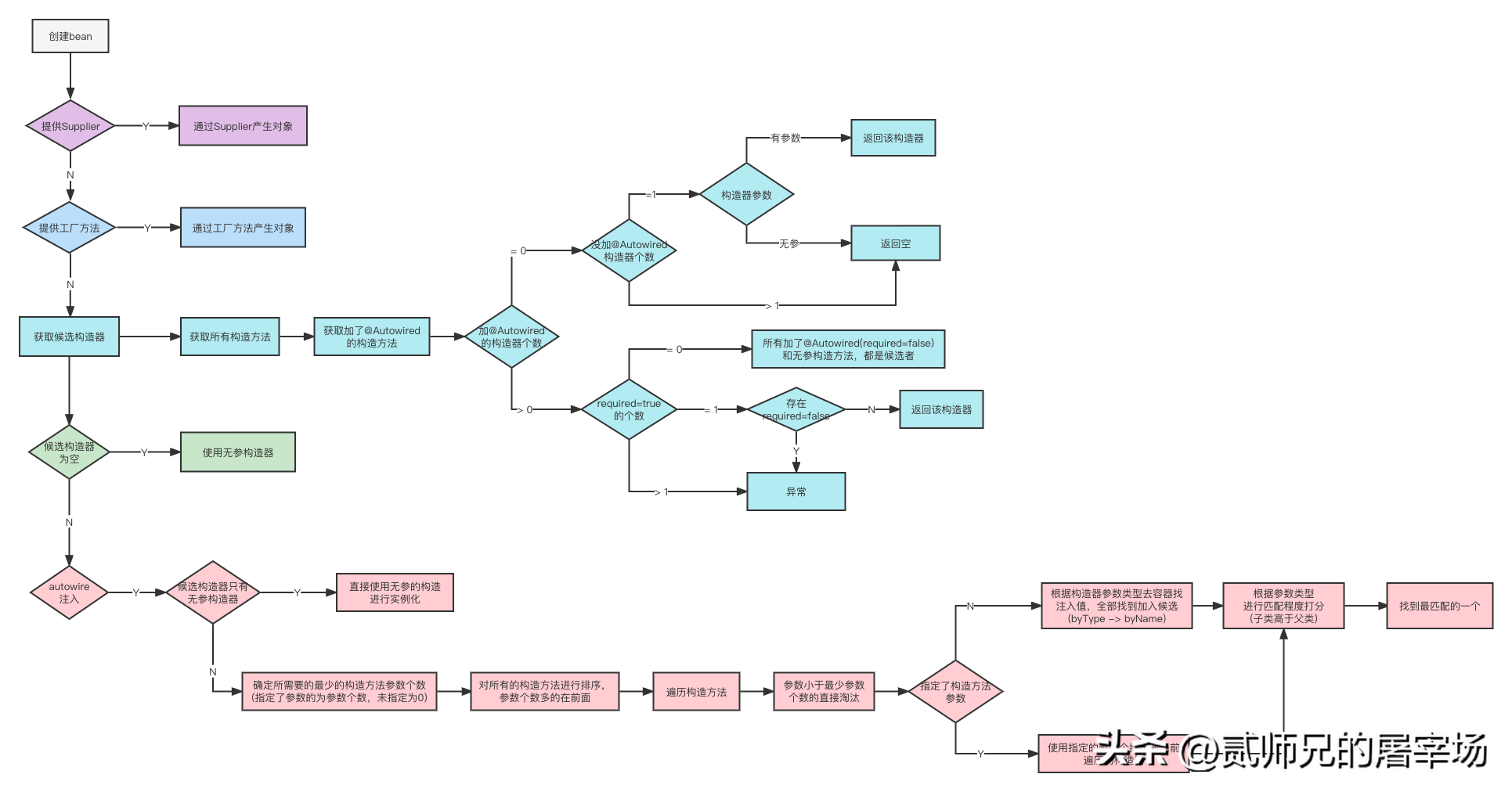
关于创建bean时,具体如何选择构造方法的,本文我们不详细展开。因为本文主旨在于分析bean的生命周期,我们只需要简单理解为:Spring会选择一个构造方法,然后通过反射创建出对象即可。其实在阅读Spring源码的时候,小伙伴们也一定要学会抓大放小,重点关注核心流程,细枝末节的地方可以先战术性忽略,后续有需要时再回过头分析也不迟,千万不要陷进去,迷失了方向。
这里给感兴趣的小伙伴附上一张流程图,感兴趣的小伙伴也可以留言,后续我们也可以单独分析。
1.2 merged BeanDefinition
本阶段是Spring提供的一个拓展点,通过MergedBeanDefinitionPostProcessor类型的后置处理器,可以对bean对应的BeanDefinition进行修改。Spring自身也充分利用该拓展点,做了很多初始化操作(并没有修改BeanDefinition),比如查找标注了@Autowired、 @Resource、@PostConstruct、@PreDestory 的属性和方法,方便后续进行属性注入和初始化回调。当然,我们也可以自定义实现,用来修改BeanDefinition信息或者我们需要的初始化操作,感兴趣的小伙伴可以自行试一下哦。
protected void applyMergedBeanDefinitionPostProcessors(RootBeanDefinition mbd, Class<?> beanType, String beanName){
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof MergedBeanDefinitionPostProcessor) {
MergedBeanDefinitionPostProcessor bdp = (MergedBeanDefinitionPostProcessor) bp;
bdp.postProcessMergedBeanDefinition(mbd, beanType, beanName);
}
}
}
1.3 暴露工厂对象
本阶段主要是将早期bean对象提前放入到三级缓存singletonFactories中,为循环依赖做支持。在后续进行属性填充时,如果发生循环依赖,可以从三级缓存中通过getObject()获取该bean,完成循环依赖场景下的依赖注入。
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 做循环依赖的支持 将早期实例化bean的ObjectFactory,添加到单例工厂(三级缓存)中
addSingletonFactory(beanName, () getEarlyBeanReference(beanName, mbd, bean));
}
该阶段完全是为了支撑循环依赖的,是Spring为解决循环依赖埋的伏笔,在Bean的生命周期中完全可以忽略。这里为了完整性,和小伙伴们简单提及一下。
如果对Spring如何解决循环依赖不是很清楚的话,可以看笔者的另一篇文章 聊透Spring循环依赖,详细分析了Spring循环依赖的解决之道,对本阶段的内容也有详细的叙述。
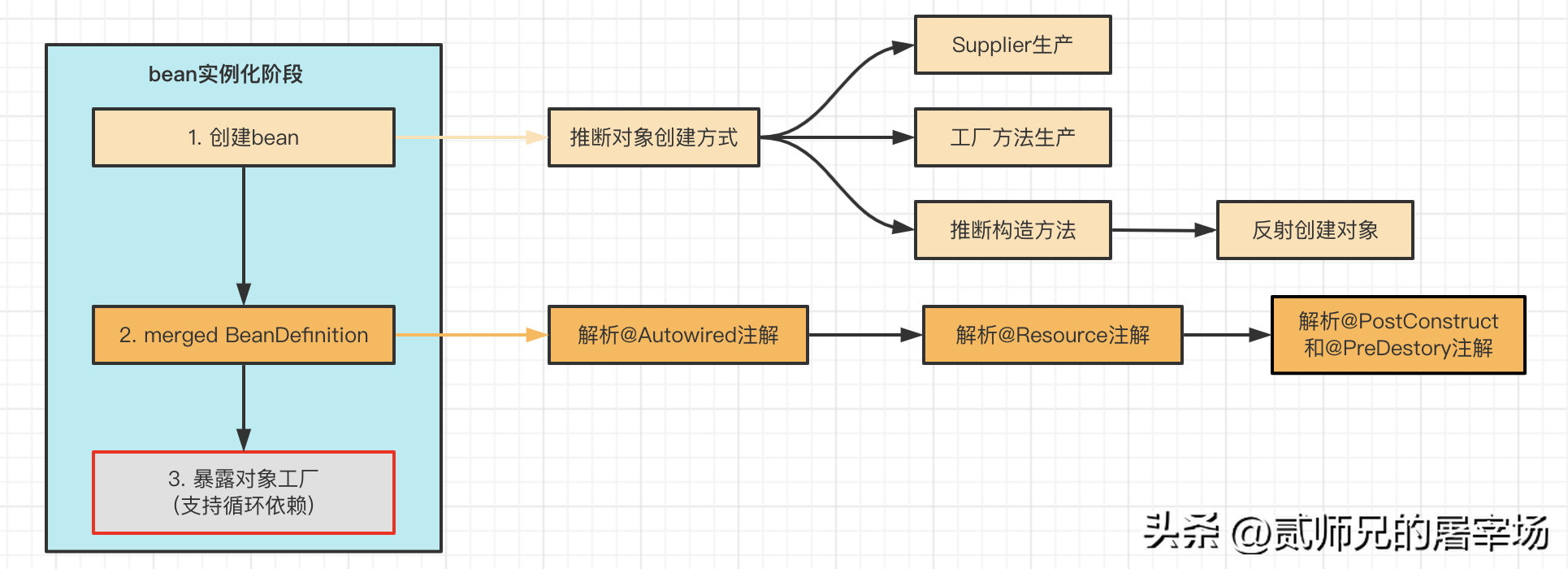
1.4 属性填充
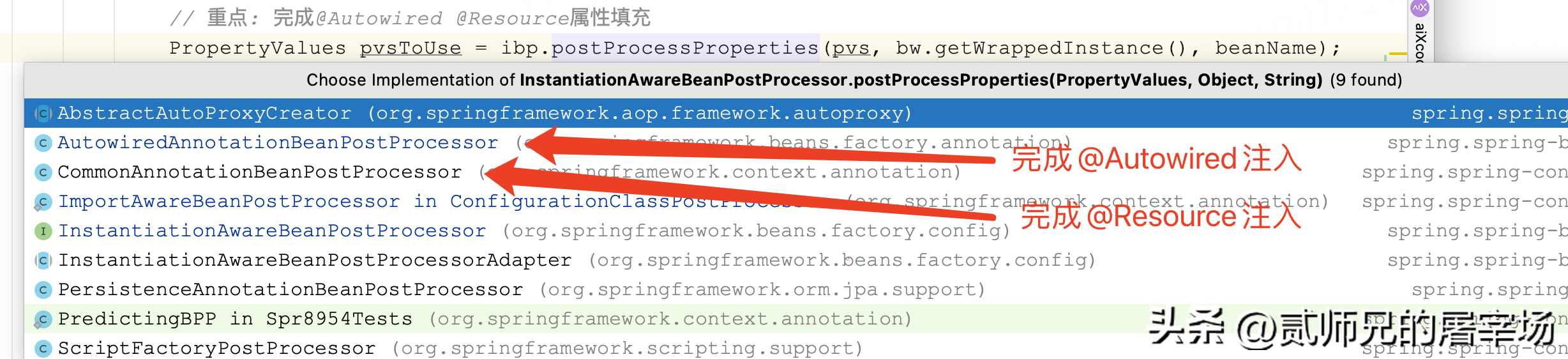
本阶段完成了Spring的核心功能之一:依赖注入,包括自动注入、@Autowired注入、@Resource注入等。Spring会根据bean的注入模型(默认不自动注入),选择根据名称自动注入还是根据类型自动注入。然后调用InstantiationAwareBeanPostProcessor#postProcessProperties()完成@Autowired和@Resource的属性注入。
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw){
// 省略部分代码
// 获取bean的注入类型
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
// 1: 自动注入
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
// 根据名称注入
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
// 根据类型注入
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
// 2: 调用BeanPostProcessor,完成@Autowired @Resource属性填充
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
// 重点: 完成@Autowired @Resource属性填充
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
// 需要注入的属性,会过滤掉Aware接口包含的属性(通过ignoreDependencyInterface添加)
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}
// 3: 依赖检查
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
// 4: 将属性应用到bean中
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
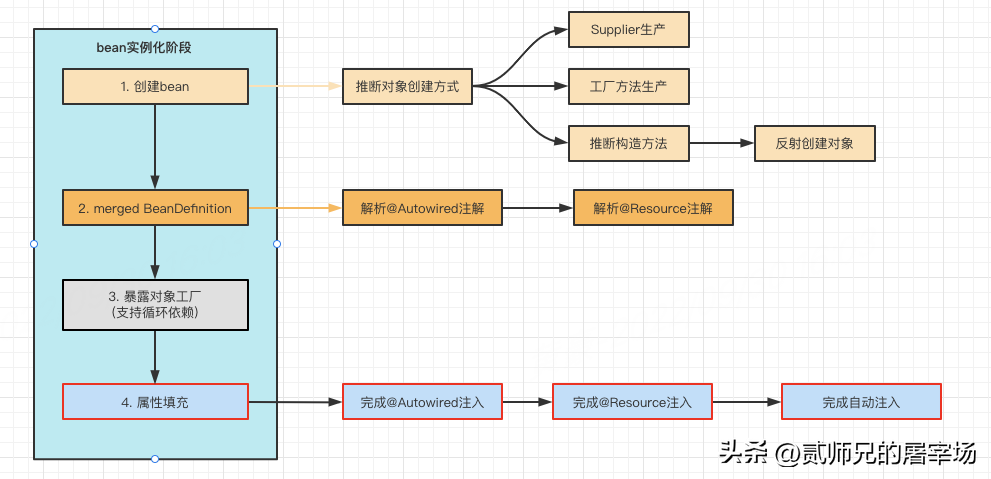
关于依赖注入,笔者在 聊透Spring依赖注入 中有详细分析,不清楚的小伙伴可以先去感受一下Spring依赖注入的奇妙之处。
1.5 初始化bean
该阶段主要做bean的初始化操作,包括:回调Aware接口、回调初始化方法、生成代理对象等。
- invokeAwareMethods():回调BeanNameAware、BeanClassLoaderAware、BeanFactoryAware感知接口。
- 回调后置处理器的前置方法,其中:
ApplicationContextAwareProcessor: 回调EnvironmentAware、ResourceLoaderAware、ApplicationContextAware、ApplicationEventPublisherAware、MessageSourceAware、EmbeddedValueResolverAware感知接口。
InitDestroyAnnotationBeanPostProcessor:回调标注了@PostConstruct的方法。
- invokeInitMethods()调用初始化方法:
如果bean是InitializingBean的子类, 先调用afterPropertiesSet()。
- 回调自定义的initMethod,比如通过@Bean(initMethod = "xxx")指定的初始化方法。
回调后置处理器的后置方法,可能返回代理对象。其中AbstractAutoProxyCreator和 AbstractAdvisingBeanPostProcessor都有可能产生代理对象,比如InfrastructureAdvisorAutoProxyCreator完成了@Transactional代理对象的生成,AsyncAnnotationBeanPostProcessor完成了@Async代理对象的生成。
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
// 1: 回调Aware接口中的方法
// 完成Aware方法的回调(BeanNameAware,BeanClassLoaderAware,BeanFactoryAware)
invokeAwareMethods(beanName, bean);
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 2: 调用before...方法
// ApplicationContextAwareProcessor: 其他Aware方法的回调
// InitDestroyAnnotationBeanPostProcessor: @PostConstruct方法的回调
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 3: 完成xml版本和@bean(initMethod)的init方法回调
invokeInitMethods(beanName, wrappedBean, mbd);
}
// 4: 调用after方法
// 重点: AOP生成代理对象
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}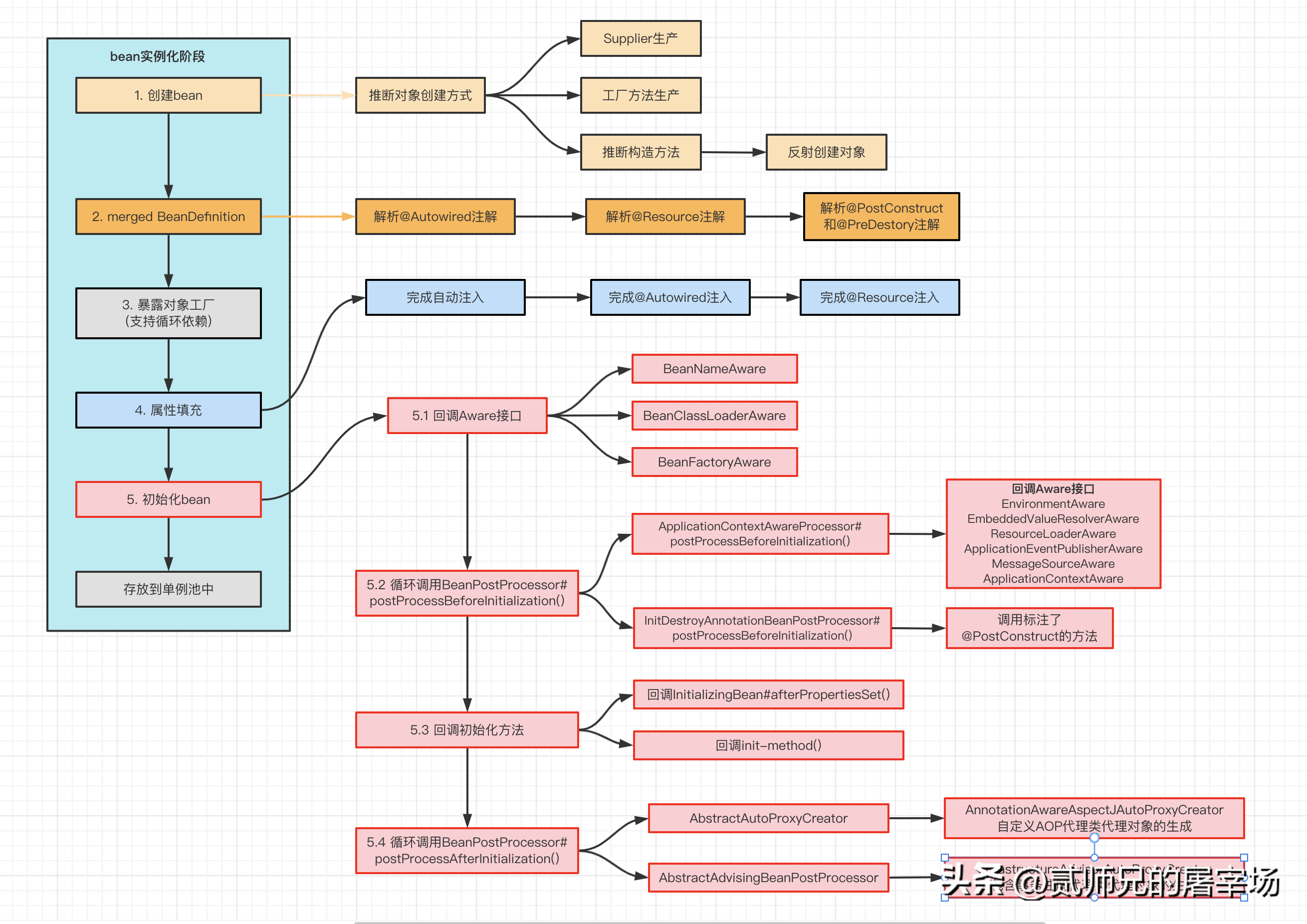
在初始化完成后,bean会被放到单例池中,正式开始自己的使命:为项目服务,比如接收http请求,进行CRUD等等。后续有使用到该bean的地方,也是直接从单例池中获取,不会再次创建bean(仅单例的哦)。
2. bean的来龙去脉
2.1 bean的扫描阶段
现在我们已经知道Spring bean是如何创建的了,那什么时候创建这些bean呢,是遵循懒加载的思想,在实际使用的时候再创建吗?其实不是的,因为bean之间的复杂关系和生命周期的原因,Spring在容器启动的时候,就会实例化这些bean,然后放到单例池中,后续即用即取。并且在创建前、创建中、创建后都会做很多检查,确保创建的bean是符合要求的,这些我们就不赘述了。
言归正传,细心的你一定发现,创建bean时主要是从RootBeanDefinition mbd这个参数获取bean的相关信息的,其实这就是大名鼎鼎的BeanDefinition,其中封装了关于bean的元数据信息,关于BeanDefinition,后续我们会单独讲解,这里我们先理解为bean的元数据信息即可。那么这些元数据信息是什么时候解析的呢?
这就要提到Spring的类扫描了,其大致流程是:通过ASM字节码技术扫描所有的类 -> 找出加了@Compont注解的(简单理解) -> 封装成BeanDefinition -> 存放到集合中。后续再实例化bean的时候,就可以遍历这个集合,获取到BeanDefinition,然后进行bean的创建了。
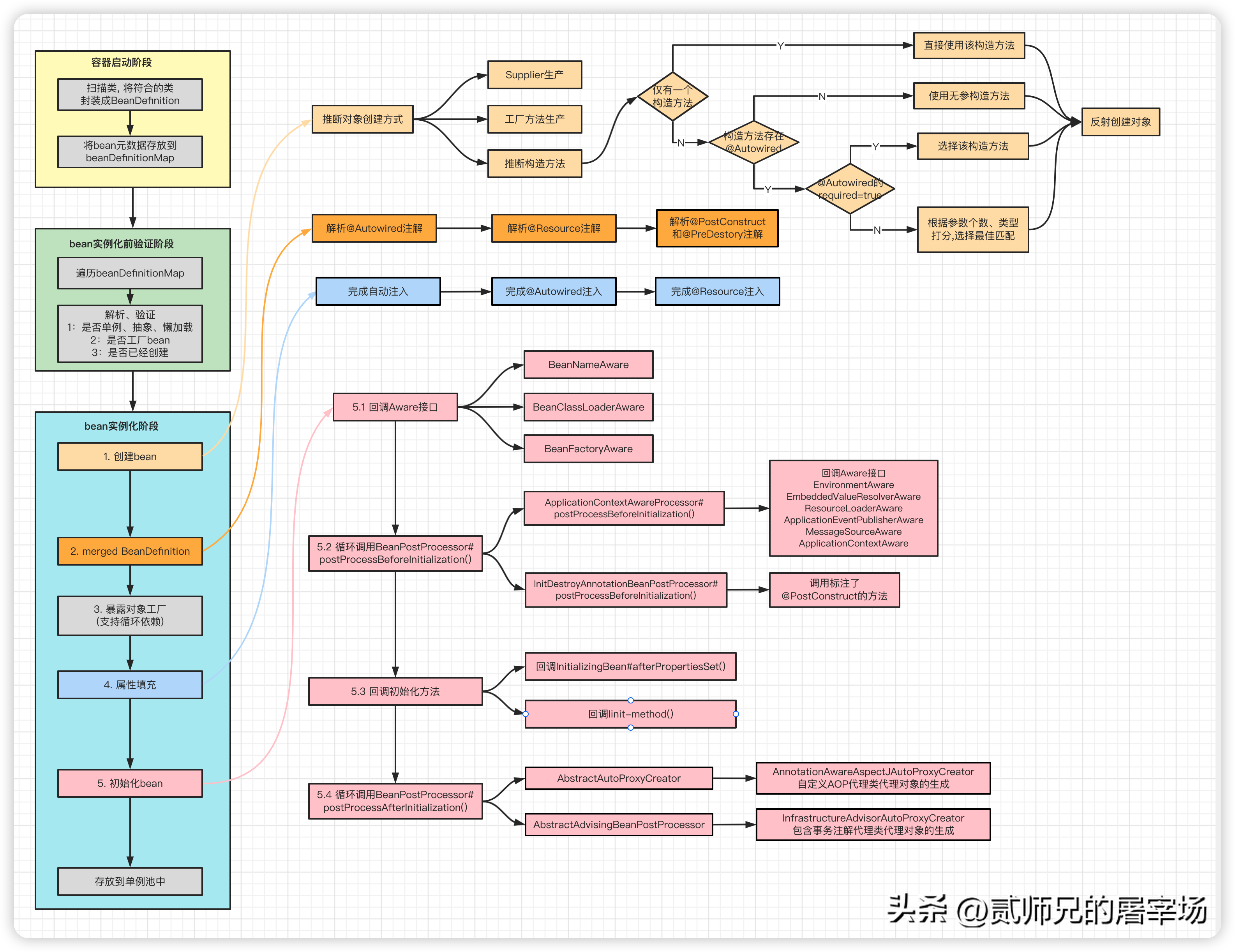
关于处理类扫描的ConfigurationClassPostProcessor后置处理器以及ConfigurationClassParser和ComponentScanAnnotationParser扫描器的具体细节,后续我们单独讲解,和本章节关系不大,我们先简单理解即可。
2.2 实例化后回调
在前面的章节我们分析过:在容器中的bean实例化,放到单例池中之后,bean在创建阶段的生命周期就正式完成,进入使用中阶段,开启对完服务之路。确实,这就是创建bean的全过程,如果有小伙伴看过笔者之前的聊Spring事件的那篇文章(聊透Spring事件机制),会发现对于@EventListener处理器的识别注册,是在afterSingletonsInstantiated阶段完成的。其实这里也是一个拓展点,我们完全可以实现SmartInitializingSingleton#afterSingletonsInstantiated(),在bean初始化完成后会回调该方法,进而触发我们自己的业务逻辑,故这里我们单独说一下。不清楚的小伙伴请移步先去了解一下哦。
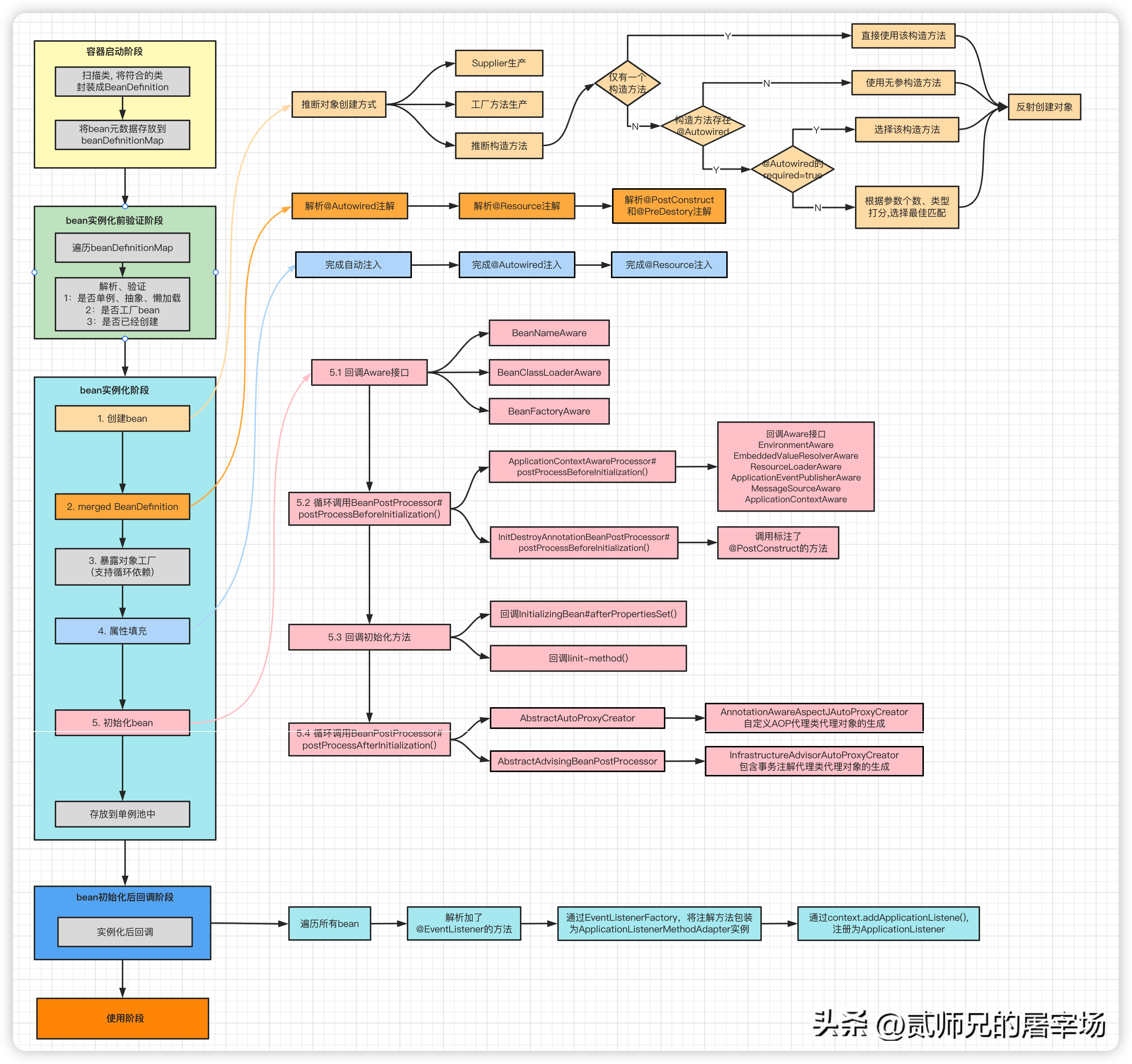
2.3 bean的销毁阶段
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// ...省略代码
try {
// 为bean注册DisposableBean,在容器关闭时,调用destory()
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
复制代码
在创建bean的时候,会判断如果bean是DisposableBean、AutoCloseable的子类,或者有destroy-method等,会注册为可销毁的bean,在容器关闭时,调用对应的方法进行bean的销毁。