前 言
读写分离方案上线后,订单sql查询时间再一次稳定在了300ms以下,此时对数据的增删改操作会走主库,而读请求会走从库,通过读写分离大大提升了数据读的处理能力,但遗憾的是没办法提升主库写数据的能力。
新的挑战
那么什么时候主库写数据的压力会过大呢?其实我们之前也聊过这个问题,那就是多个业务共用一个物理数据库的,比如商品相关的表、订单相关的表和用户相关的表等,所有表都放到了一个mysql数据库中,就像这样:
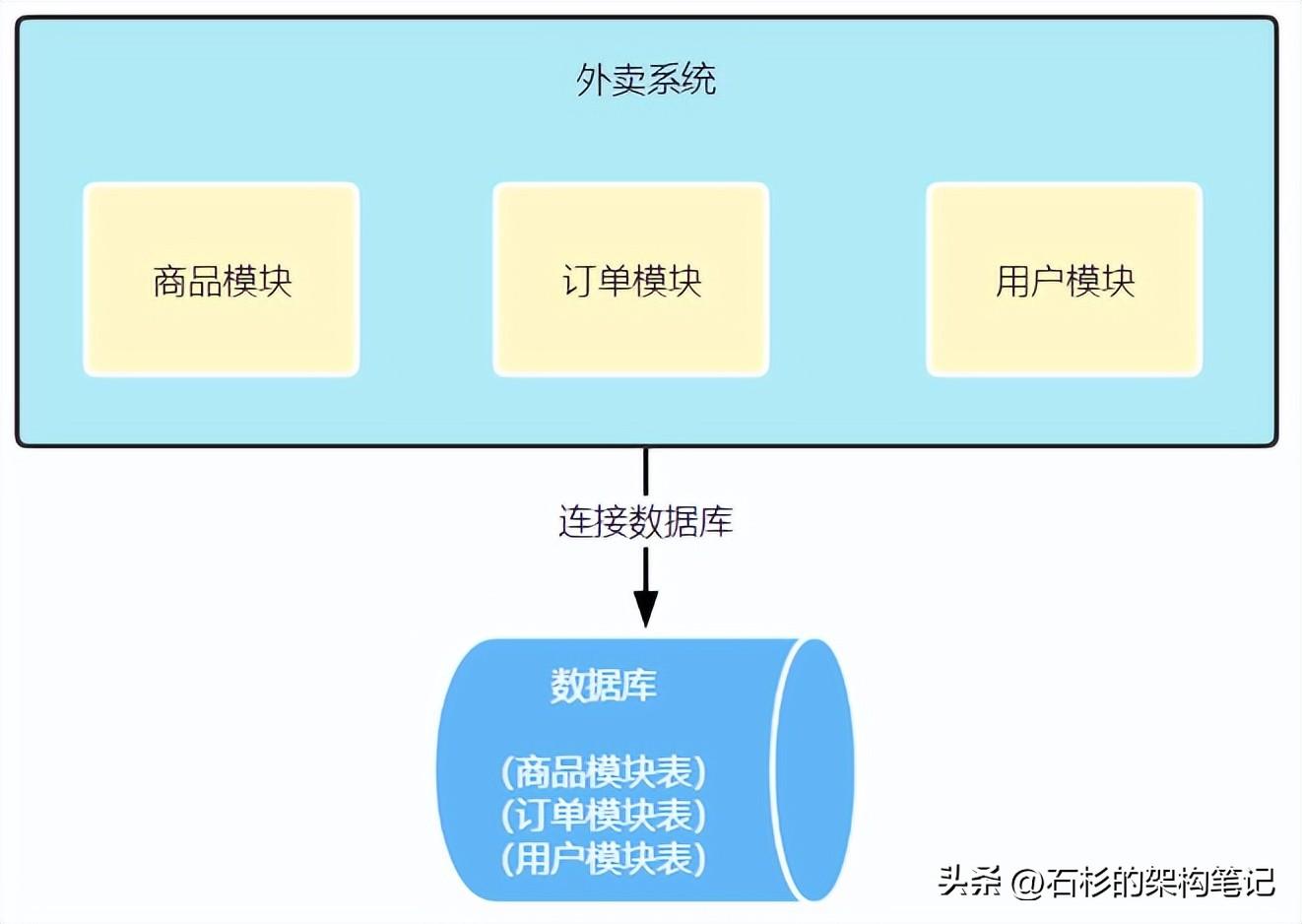
此时商品模块、订单模块、用户模块都部署在同一台物理数据库上,说白了就是主库上,那么此时这台物理数据库的CPU、内存和网络的负载能力,都是商品模块、订单模块、用户模块共用的。
这就很尴尬了,由于这3个模块是共用同一台数据库的资源,那么就势必会相互影响,比如某一天商品模块做了一些活动,尴尬的是商品模块并没有做读写分离,那么这个时候可能商品模块,会对这台物理数据库进行大量的读操作,此时这台物理数据库的CPU、内存和网络负载占用都很高。
而数据库的资源是有限的,既然商品模块占用了大量的数据库资源,那么留给订单模块可用的资源就非常少了,这个时候就会导致订单库写数据很慢,写入一条订单数据突增到了2s,对于订单来说,这个肯定是万万不能接受的
那么有没有破局之道呢?那当然是有的,那就是垂直拆分。
怎么做垂直拆分?
垂直拆分其实分为垂直分库和垂直分表,我们这里指的是垂直分库,说白了就是由一个数据库拆分出来多个数据库,那么具体怎么拆分呢?
其实可以从数据表的维度来拆分,将表做一个分类,比如之前一个库100张表,现在我分成了10个mysql数据库,每个数据库10张表的数据,这样每个数据库的压力就会很小。
垂直拆分说白了就是将一个大的系统的多张表,做一个分类,一般按照模块来拆分出一个一个的数据库,而每个数据库中只存放一类数据表,每个数据库都有一批表,而且都是同一个模块的表。
比如一般在外卖系统中,包含商品模块、订单模块、用户模块等,垂直拆分就是将每个模块的一类表,都分别放到单独的库中,分而治之,这样说白了就是分布式系统、微服务拆分后的效果了:
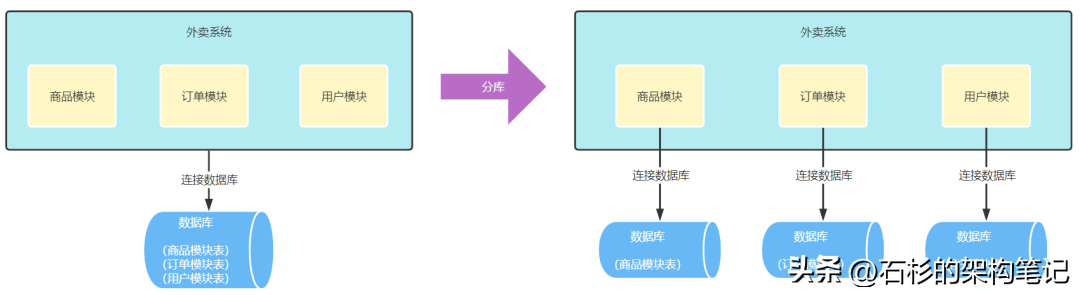
这样就可以解决刚才的问题了,因为根本原因是这3个模块共用了一台数据库的资源,结果商品模块占用数据库服务器大量资源的时候,留给订单模块的资源自然就少了,所以破局之道就是我们就需要把这3个模块的数据库拆分开,不让它们共用一台物理数据库,而是给每个业务模块,配备一台自己独立的物理数据库服务器,说白了就是将数据库进行了垂直分库,由共用一个大杂烩数据库,拆分为独立的商品数据库、订单数据库和用户数据库。
不过在实际的分库中,我们可能需要考虑一个情况,就是有些模块关联性比较大,可能经常需要一起查询。所以这时候,我们也可以把强关联的一些模块的表放在一个库,避免跨库查询带来的效率降低。
好了,此时由于我们已经把不同模块的表放到了不同的数据库中,每个库都有自己独立的一台物理服务器,那么这台物理数据库的CPU、内存和网络的负载能力都是相互隔离的,因此之前资源相互占用的问题也就不存在了。
垂直拆分有哪些好处呢?
垂直拆分是可以带来很多好处的,比如可以帮我们减轻数据库的压力,当我们按照模块分库之后,不同模块的数据表,现在已经被分到了多个数据库中了,每个数据库中的数据,就不会那么多了,查询的效率就会更高了。
另外,单个数据库的数据量变少了之后,相应的CPU、内存、网络的负载的压力,也会相应的降低,整体的查询效率也会提高。
垂直拆分后,业务会变的更加清晰,维护数据也会很方便,因为一个库拆分成了多个库,每个库中的表都是一个业务模块的,所以一个库中就一个模块的业务,很清晰。
并且,数据维护也是,需要找哪个模块的数据,就到对应库中找,不会像拆分前,多个模块的数据糅在一起,维护数据也简单,因为多个模块的数据,解耦了,修改一个库中的数据,不会影响其他库的数据。
而且,系统扩展也会变的更容易一些,现在各个模块都拆分出来了,比如订单模块,就从外卖系统中,单独拆分出来一个模块了,这个订单模块的数据,在一个数据库中和其他模块的数据,就独立了。
如果订单模块业务要做复杂了,需要扩展了,比如订单的表结构要设计的更复杂点,添加更多的业务设计,对其它模块都是透明的,很容易扩展;不会像之前一样,多个模块的多张表,耦合在一个库中,也不好拓展,因为会担心影响到其他业务。
垂直拆分有什么不足的地方吗?
好了,说了垂直分库的这么多好处,那么它有没有一些不足的地方呢?答案是肯定的。
首先就是系统会变的更复杂,因为现在垂直拆分之后,多个模块的表,都分别分到不同的数据库中了,如果现在有一个查询操作,要关联多张表,这个时候,就不能简单使用join来进行关联查询了。
比如a表在A库,b表在B库,这个时候就不能简单的join连接了,而需要先通过接口的方式,先获取到a表的数据,然后再通过接口获取b表的数据,这样操作就变复杂了。
另外,事务的处理也会变得更加的麻烦,之前要处理事务的话,在一个数据库中处理即可,出现问题直接回滚事务就行了。
但是现在要操作的数据,可能是分布在多个数据库中的,如果操作过程中的某个环节出问题了,就不能简单的回滚事务了,因为现在是横跨多个数据库的事务,这个时候就要用到分布式事务的解决方案了,就更复杂了。
而且,单库的性能也会很快的遇到瓶颈,虽然现在一个大的系统的多张表,按照不同模快切出了多个数据库,每个库有相应模块的表,可能某一个模块的数据量会特别大,比如订单模块,相比于其他模块而言,数据量会非常大。
并且这里通常是单表数据量过大,比如订单表单表可能已经6000W数据了,这个时候订单表的读写效率已经开始明显降低了。
像这种单表数据量过大的问题,垂直分库是解决不了的,所以这个时候就需要对订单表进行进一步的拆分,也就是水平拆分。
由于我们实战是以外卖订单业务为主,所以本身就只有一个订单数据库,其实天然就已经做了垂直分库,所以这个垂直分库我们就不进行实战了,后边的水平分库分表是我们的重头戏,到时候会带着大家一起设计水平分库分表的落地方案和数据迁移方案的,大家敬请期待!