有朋友问我:
沈老师,我们有个业务,同一个用户在并发“查询,逻辑计算,扣款”的情况下,余额可能出现不一致,请问有什么优化方法么?
今天和大家聊一聊这个问题。
画外音:文章较长,建议提前收藏。

问题一:用户扣款的业务场景是怎样的?
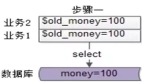
用户购买商品的过程中,要对余额进行查询与修改,大致的业务流程如下:
第一步,从数据库查询用户现有余额:
不妨设查询出来的$old_money=100元。
第二步,业务层实施业务逻辑计算,比如:
(1)先查询购买商品的价格,例如是80元;
(2)再查询产品是否有活动,以及活动折扣,例如是9折;
(3)比对余额是否足够,足够时才往下走;
第三步,将数据库中的余额进行修改。
在并发量低的情况下,这个流程没有任何问题,原有金额100元,购买了80元的九折商品(72元),剩余28元。
问题二:同一个用户,并发扣款可能出现什么问题?
在分布式环境中,如果并发量很大,这种“查询+修改”的业务有一定概率出现数据不一致。
极限情况下,可能出现这样的异常流程:
步骤一,业务1和业务2并发查询余额,是100元。

画外音:这些并发查询,是在不同的站点实例/服务实例上完成的,进程内互斥锁肯定解决不了。
步骤二,业务1和业务2并发进行逻辑计算,算出各自业务的余额,假设业务1算出的余额是28元,业务2算出的余额是38元。

步骤三,业务1对数据库中的余额先进行修改,设置成28元。
业务2对数据库中的余额后进行修改,设置成38元。

此时异常出现了,原有金额100元,业务1扣除了72元,业务2扣除了62元,最后剩余38元。画外音:假设业务1先写回余额,业务2再写回余额。
问题三:有什么常见的解决方案?
对于此案例,同一个用户,并发扣款时,有小概率会出现异常,可以对每一个用户进行分布式锁互斥,例如:在redis/zk里抢到一个key才能继续操作,否则禁止操作。
这种悲观锁方案确实可行,但要引入额外的组件(redis/zk),并且会降低吞吐量。对于小概率的不一致,有没有乐观锁的方案呢?
对并发扣款进行进一步的分析发现:
(1) 业务1写回时,旧余额100,这是一个初始状态;新余额28,这是一个结束状态。理论上只有在旧余额为100时,新余额才应该写回成功。
而业务1并发写回时,旧余额确实是100,理应写回成功。
(2) 业务2写回时,旧余额100,这是一个初始状态;新余额28,这是一个结束状态。理论上只有在旧余额为100时,新余额才应该写回成功。
可实际上,这个时候数据库中的金额已经变为28了,所以业务2的并发写回,不应该成功。
如何低成本实施乐观锁?
在set写回的时候,加上初始状态的条件compare,只有初始状态不变时,才允许set写回成功,Compare And Set(CAS),是一种常见的降低读写锁冲突,保证数据一致性的方法。
此时业务要怎么改?
使用CAS解决高并发时数据一致性问题,只需要在进行set操作时,compare初始值,如果初始值变换,不允许set成功。
具体到这个case,只需要将:
升级为:
即可。
并发操作发生时:
业务1执行:
业务2执行:
这两个操作同时进行时,只可能有一个执行成功。
怎么判断哪个并发执行成功,哪个并发执行失败呢?
set操作,其实无所谓成功或者失败,业务能通过affect rows来判断:
- 写回成功的,affect rows为1;
- 写回失败的,affect rows为0;
高并发“查询并修改”的场景,可以用CAS(Compare and Set)的方式解决数据一致性问题。对应到业务,即在set的时候,加上初始条件的比对即可。
优化不难,只改了半行SQL,但确实能解决问题。
问题四:能不能使用直接扣减的方法
来进行余额扣减?
明显不行,在并发情况下,会将money扣成负数。
问题五:为了保证余额不被扣成负数,再加一个where条件:
这样是否可行?
很遗憾,仍然不行。
这个方案不幂等。
那什么是幂等性?
聊幂等性之前,先看另一个测试用例的case。
假设有一个服务接口,注册新用户:
有一个测试工程师,对该接口写了一个测试用例:
这是不是一个好的测试用例?这个用例存在什么问题?
你会发现,相同条件下,这个测试用例执行两次,得到的结果不一样:
- 第一次执行,第一次造数据,调用接口,注册成功;
- 第二次执行,又造了一次相同的数据,调用接口,注册会失败;
这不是一个好的测试用例,多次执行结果不同。
什么是幂等性?
相同条件下,执行同一请求,得到的结果相同,才符合幂等性。
画外音:Google一下,比我解释得更好,但意思应该说清楚了。
如何将上面的测试用例改为符合“幂等性”的测试用例呢?
只需要加一行代码:
这样,在相同条件下,不管这个用例执行多少次,得到的测试结果都是相同的。
读请求,一般是幂等的。
写请求,视情况而定:
- insert x,一般来说不是幂等的,重复插入得到的结果不一定一样;
- delete x,一般来说是幂等的,删除多次得到的结果仍相同;
- set a=x是幂等的;
- set a=a-x不是幂等的;
- …
因此,这么扣减余额:
是幂等操作。
要是这么扣减余额:
不是幂等操作。
聊到这里,或许有朋友要抬杠了,测试用例会重复执行,扣款怎么会重复执行呢?
重试。
重试,是异常处理里很常见的手段。
你在写业务的时候有没有写过这样的代码:
当然,又会有朋友抬杠了,我从来不重试!!!
画外音:额,这是合格,还是不合格呢?
你可以决定业务代码怎么写,你不能决定底层框架代码怎么写:
- 站点框架有没有自动重试?
- 服务框架有没有自动重试?
- 服务连接池,数据库连接池有没有自动重试?
画外音:
- 服务化分层的架构中,建议只入口层重试,服务层不要重试,防止雪崩;
- dubbo底层,调用超时是默认重试的,这个设计不好;
因此,在有重试的架构体系里,幂等性是需要考虑的一个问题。
因此,扣款和充值业务,一般使用:
select&set,配合CAS方案
而不使用:
set money-=X方案
问题五:CAS方案,会不会存在ABA问题?
什么是ABA问题?
CAS乐观锁机制确实能够提升吞吐,并保证一致性,但在极端情况下可能会出现ABA问题。
考虑如下操作:
- 并发1(上):获取出数据的初始值是A,后续计划实施CAS乐观锁,期望数据仍是A的时候,修改才能成功
- 并发2:将数据修改成B
- 并发3:将数据修改回A
- 并发1(下):CAS乐观锁,检测发现初始值还是A,进行数据修改
上述并发环境下,并发1在修改数据时,虽然还是A,但已经不是初始条件的A了,中间发生了A变B,B又变A的变化,此A已经非彼A,数据却成功修改,可能导致错误,这就是CAS引发的所谓的ABA问题。
余额操作,出现ABA问题并不会对业务产生影响,因为对于“余额”属性来说,前一个A为100余额,与后一个A为100余额,本质是相同的。
但其他场景未必是这样,举一个堆栈操作的例子:

并发1(上):读取栈顶的元素为“A1”

并发2:进行了2次出栈

并发3:又进行了1次出栈
并发1(下):实施CAS乐观锁,发现栈顶还是“A1”,于是修改为A2

此时会出现系统错误,因为此“A1”非彼“A1”
ABA问题可以怎么优化?
ABA问题导致的原因,是CAS过程中只简单进行了“值”的校验,在有些情况下,“值”相同不会引入错误的业务逻辑(例如余额),有些情况下,“值”虽然相同,却已经不是原来的数据了(例如堆栈)。
因此,CAS不能只比对“值”,还必须确保是原来的数据,才能修改成功。
常见的实践是,将“值”比对,升级为“版本号”的比对,一个数据一个版本,版本变化,即使值相同,也不应该修改成功。
余额并发读写例子,引入版本号的具体实践如下:
(1) 余额表要升级。
升级为:
(2) 查询余额时,同时查询版本号。
升级为:
假设有并发操作,都会将版本号查询出来
(3) 设置余额时,必须版本号相同,并且版本号要修改。
旧版本“值”比对:
升级为“版本号”比对:
此时假设有并发操作,首先操作的请求会修改版本号,并发操作会执行失败。
画外音:version通用,本例是强行用version举例而已,实际上本例可以用余额“值”比对。
总结
- select&set业务场景,在并发时会出现一致性问题
- 幂等性是一个需要考虑的问题
- 基于“值”的CAS乐观锁,可能导致ABA问题
- CAS乐观锁,必须保证修改时的“此数据”就是“彼数据”,应该由“值”比对,优化为“版本号”比对
思路比结论重要。