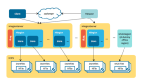
⼀个 Elasticsearch 实例即⼀个 Node,⼀台机器可以有多个实例,正常使⽤下每个实例应该会部署在不同的机器上。Elasticsearch 的配置⽂件中可以通过 node.master、node.data 来设置节点类型。
通往集群大门
⾼可⽤(High Availability)是分布式系统架构设计中必须考虑的因素之⼀,它通常是指,通过设计减少系统不能提供服务的时间。如果系统每运⾏100个时间单位,会有1个时间单位⽆法提供服务,我们说系统的可⽤性是99%。
将流量均衡的分布在不同的节点上,每个节点都可以处理⼀部分负载,并且可以在节点之间动态分配负载,以实现平衡。
将流量分发到不同机器,充分利⽤多机器多CPU,从串⾏计算到并⾏计算提⾼系统性能。
es集群的基本核心概念
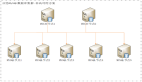
⼀个 Elasticsearch 集群由⼀个或多个节点(Node)组成,每个集群都有⼀个共同的集群名称作为标识。
⼀个 Elasticsearch 实例即⼀个 Node,⼀台机器可以有多个实例,正常使⽤下每个实例应该会部署在不同的机器上。Elasticsearch 的配置⽂件中可以通过 node.master、node.data 来设置节点类型。
node.master:表示节点是否具有成为主节点的资格
true代表的是有资格竞选主节点
false代表的是没有资格竞选主节点
node.data:表示节点是否存储数据
主节点+数据节点(master+data)
节点即有成为主节点的资格,⼜存储数据
node.master: true
node.data: true
数据节点(data)
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false
node.data: true
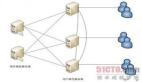
客户端节点(client)
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进⾏负载均衡
node.master: false
node.data: false
每个索引有⼀个或多个分⽚,每个分⽚存储不同的数据。分⽚可分为主分⽚( primary shard)和复制分⽚(replica shard),复制分⽚是主分⽚的拷⻉。默认每个主分⽚有⼀个复制分⽚,⼀个索引的复制分⽚的数量可以动态地调整,复制分⽚从不与它的主分⽚在同⼀个节点上
手把手教你搭建es集群
搭建步骤
拷⻉elasticsearch-7.2.0安装包3份,分别命名es-a, es-b,es-c。
分别修改elasticsearch.yml⽂件。
分别启动a ,b ,c 三个节点。
打开浏览器输⼊:http://localhost:9200/_cat/health?v ,如果返回的node.total是3,代表集群搭建成功
配置elasticsearch.yml⽂件
#集群名称
cluster.name: cyz-es
#节点名称
node.name: node-1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最⼤集群节点数
node.max_local_storage_nodes: 3
#⽹关地址
network.host: 0.0.0.0
#端⼝
http.port: 9200
#内部节点之间沟通端⼝
transport.tcp.port: 9300
#es7.x 之后新增的配置,写⼊候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"]
#es7.x 之后新增的配置,初始化⼀个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1", "node-2","node-3"]
#数据和存储路径
path.data: /usr/local/es/data
path.logs: /usr/local/es/logs
node.name: node-2
http.port: 9201
transport.tcp.port: 9400
node.name: node-3
http.port: 9202
transport.tcp.port: 9500
kibana
- 打开配置 kibana.yml,添加elasticsearch.hosts: ["http://localhost:9200","http://localhost:9201","http://localhost:9202"]
- 启动kibana,可以看到集群信息
es集群索引分片管理
介绍
- 分⽚(shard):因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, ⽽这些分布在不同节点的数据就是分⽚. ES⾃动管理和组织分⽚, 并在必要的时候对分⽚数据进⾏再平衡分配, 所以⽤户基本上不⽤担⼼分⽚的处理细节。
- 副本(replica):ES默认为⼀个索引创建1个主分⽚, 并分别为其创建⼀个副本分⽚. 也就是说每个索引都由1个主分⽚成本, ⽽每个主分⽚都相应的有⼀个copy.
- Elastic search7.x之后,如果不指定索引分⽚,默认会创建1个主分⽚和⼀个副分⽚,⽽7.x版本之前的⽐如6.x版本,默认是5个主分⽚
创建索引(不指定分⽚数量)
PUT nba
{"mappings":{"properties":{"birthDay":{"type":"date"},"birthDayStr":
{"type":"keyword"},"age":{"type":"integer"},"code":
{"type":"text"},"country":{"type":"text"},"countryEn":
{"type":"text"},"displayAffiliation":{"type":"text"},"displayName":
{"type":"text"},"displayNameEn":{"type":"text"},"draft":
{"type":"long"},"heightValue":{"type":"float"},"jerseyNo":
{"type":"text"},"playYear":{"type":"long"},"playerId":
{"type":"keyword"},"position":{"type":"text"},"schoolType":
{"type":"text"},"teamCity":{"type":"text"},"teamCityEn":
{"type":"text"},"teamConference":{"type":"keyword"},"teamConferenceEn":
{"type":"keyword"},"teamName":{"type":"keyword"},"teamNameEn":
{"type":"keyword"},"weight":{"type":"text"}}}}
创建索引(指定分片数量)
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},PUT nba
{"settings":{"number_of_shards":3,"number_of_replicas":1},"mappings":
{"properties":{"birthDay":{"type":"date"},"birthDayStr":
{"type":"keyword"},"age":{"type":"integer"},"code":
{"type":"text"},"country":{"type":"text"},"countryEn":
{"type":"text"},"displayAffiliation":{"type":"text"},"displayName":
{"type":"text"},"displayNameEn":{"type":"text"},"draft":
{"type":"long"},"heightValue":{"type":"float"},"jerseyNo":
{"type":"text"},"playYear":{"type":"long"},"playerId":
{"type":"keyword"},"position":{"type":"text"},"schoolType":
{"type":"text"},"teamCity":{"type":"text"},"teamCityEn":
{"type":"text"},"teamConference":
{"type":"keyword"},"teamConferenceEn":{"type":"keyword"},"teamName":
{"type":"keyword"},"teamNameEn":{"type":"keyword"},"weight":
{"type":"text"}}}}
索引分片分配
- 分⽚分配到哪个节点是由ES⾃动管理的,如果某个节点挂了,那分⽚⼜会重新分配到别的节点上。
- 在单机中,节点没有副分⽚,因为只有⼀个节点没必要⽣成副分⽚,⼀个节点挂点,副分⽚也会挂掉,完全是单故障,没有存在的意义。
- 在集群中,同个分⽚它的主分⽚不会和它的副分⽚在同⼀个节点上,因为主分⽚和副分⽚在同个节点,节点挂了,副分⽚和主分机⼀样是挂了,不要把所有的鸡蛋都放在同个篮⼦⾥。
- 可以⼿动移动分⽚,⽐如把某个分⽚移动从节点1移动到节点2。
- 创建索引时指定的主分⽚数以后是⽆法修改的,所以主分⽚数的数量要根据项⽬决定,如果真的要增加主分⽚只能重建索引了。副分⽚数以后是可以修改的。
手动移动分片
POST /_cluster/reroute
{
"commands": [
{
"move": {
"index": "nba",
"shard": 2,
"from_node": "node-1",
"to_node": "node-3"
}
}
]
}
修改副分⽚数量
PUT /nba/_settings
{
"number_of_replicas": 2
}
玩转es集群健康管理
查看集群的健康状态
- http://127.0.0.1:9200/_cat/health?v
- URL返回了集群的健康信息。
- 返回信息

status :集群的状态,red红表示集群不可⽤,有故障。yellow⻩表示集群不可靠但可⽤,⼀般单节点时就是此状态。green正常状态,表示集群⼀切正常。
node.total :节点数,这⾥是3,表示该集群有三个节点。
node.data :数据节点数,存储数据的节点数,这⾥是3。
shards :表示我们把数据分成多少块存储。
pri :主分⽚数,primary shards
active_shards_percent :激活的分⽚百分⽐,这⾥可以理解为加载的数据分⽚数,只有加载所有的分⽚数,集群才算正常启动,在启动的过程中,如果我们不断刷新这个⻚⾯,我们会发现这个百分⽐会不断加⼤。
查看集群的索引数
- http://127.0.0.1:9200/_cat/indices?v
- URL返回了集群中的所有索引信息,我们可以看到所有索引的健康情况和具体信息。
- 返回信息
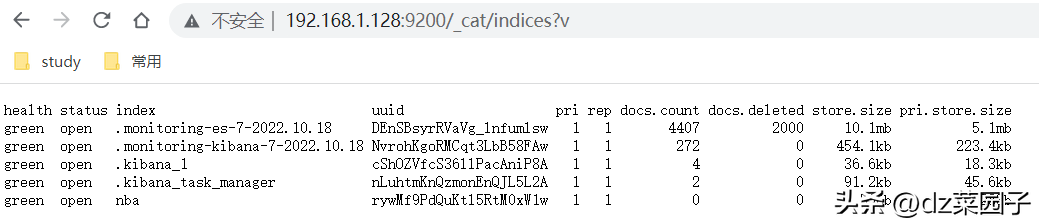
health : 索引健康,green为正常,yellow表示索引不可靠(单节点),red索引不可⽤。与
集群健康状态⼀致。
status : 状态表明索引是否打开,只索引是可以关闭的。
index : 索引的名称
uuid : 索引内部分配的名称,索引的唯⼀表示
pri : 集群的主分⽚数量
docs.count : 这⾥统计了⽂档的数量。
docs.deleted : 这⾥统计了被删除⽂档的数量。
store.size : 索引的存储的总容量
pri.store.size : 主分别的容量
查看磁盘的分配情况
- http://192.168.1.128:9200/_cat/allocation?v
- URL返回了每个节点的磁盘情况。
- 返回信息
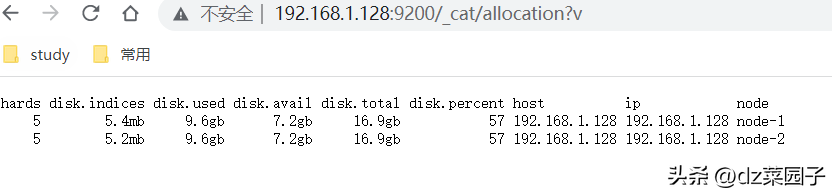
shards : 该节点的分⽚数量
disk.indices : 该节点中所有索引在该磁盘所点的空间。
disk.used : 该节点已经使⽤的磁盘容量
disk.avail : 该节点可以使⽤的磁盘容量
disk.total : 该节点的磁盘容量
查看集群的节点信息
- http://127.0.0.1:9200/_cat/nodes?v
- URL返回了集群中各节点的情况。
- 返回信息
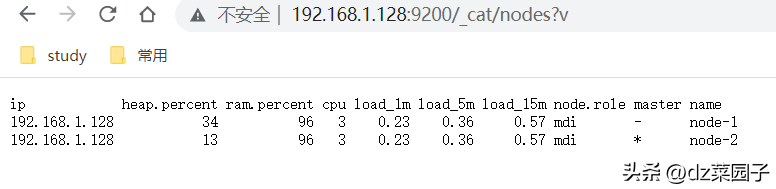
ip : ip地址
heap.percent : 堆内存使⽤情况
ram.percent : 运⾏内存使⽤情况
cpu : cpu使⽤情况
master : 是否是主节点
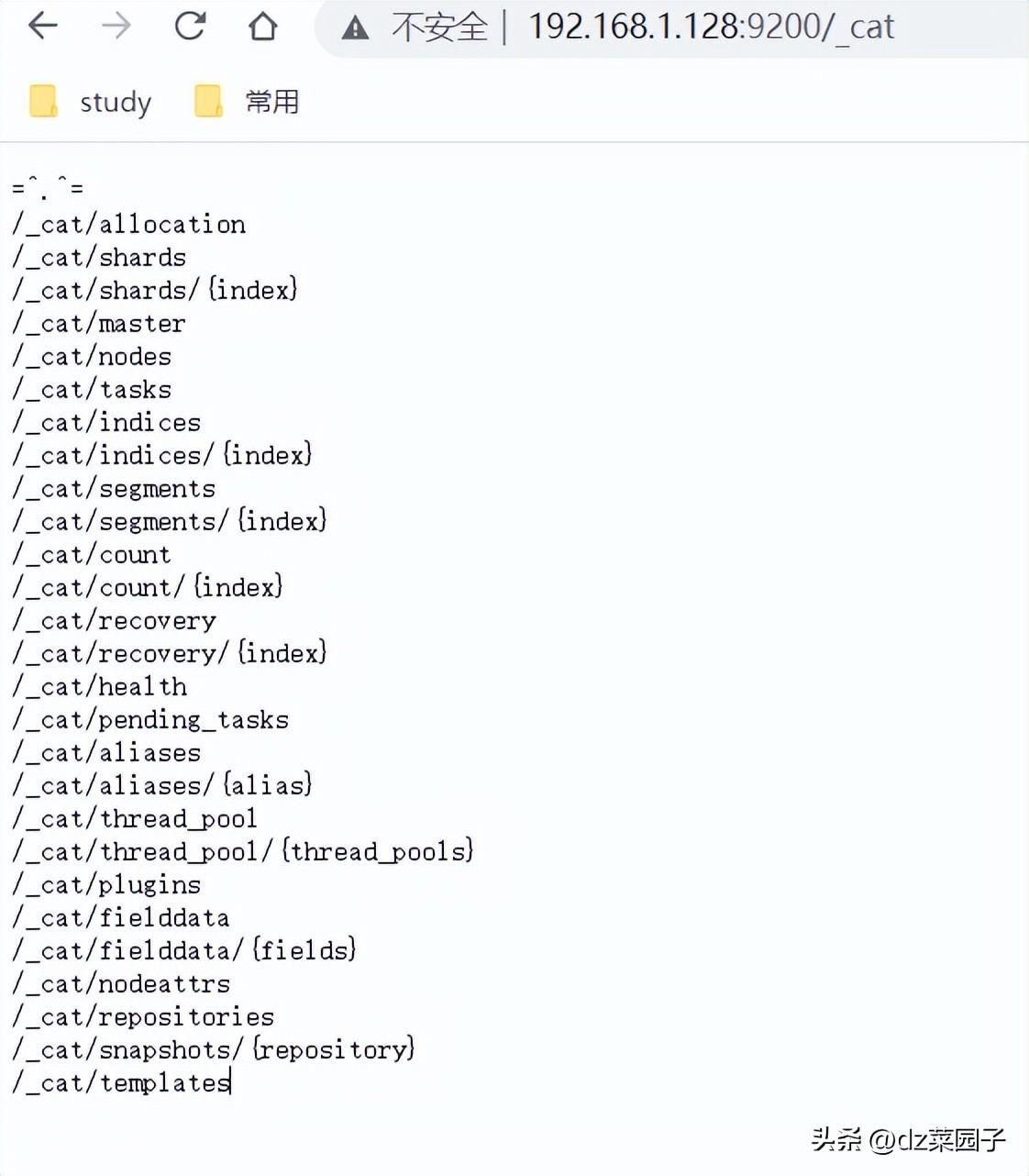
查看集群的其他信息
- http://127.0.0.1:9200/_cat
参考个人博客:http://www.sddzcyz.cn/