本文的目的是帮助您开始在 python 中绘制数据。 我们将创建一个条形图来绘制给定文本文件中字符的频率。 在这种情况下,文本文件包含了《了不起的盖茨比》的内容。

第 1 步:创建您的虚拟环境
这个项目的环境会比较小。 虚拟环境允许您向工作区添加额外的功能,而不会影响计算机的其余部分!
创建一个目录并在代码编辑器和终端(运行命令的地方)中打开它。
让我们运行:
我们可以安装我们必要的依赖项
我们还要创建两个文件,read.txt 和 wordcount.py。
我们将使用 wordcount.py 来分析 read.txt 中的文本。
第 2 步:阅读文本
我们可以比较简单的开始,
- 首先,它导入我们的绘图和排序库
- 其次,我们使用内置的 open 函数,它允许我们打开一个文件进行读写
- 然后我们读取文件里面的文本并将其存储到文本变量中
- 最后,我们关闭文件,因为我们不再使用它了
这就是我们“读取”文件并将内容存储在变量中所需的全部内容。
第 3 步:分析字符
我们可以跟踪字符的最好方法是使用 python 字典(在其他编程语言中称为 hashmap)。
字典是一种非常有用的数据存储方式。 就像真正的字典一样,它会有一个“单词”列表,您可以查看单词以查看定义。
在编程中,这个概念被推广到“键/值”对。 这意味着我们可以设置字典,当我向字典询问“a”时,它将返回“a”出现的总次数。
所以让我们编码吧!
让我们回顾一下这里发生了什么。
- 首先我们定义一个空字典
- 接下来我们使用 def 关键字定义一个函数。 这个函数接受一个变量“字符”,检查它是否是一个空格(空格、制表符、换行符)。 您可以为您的选择添加其他标准,例如 isalpha() 以确定字符是否为字母
- 然后检查它是否已经在字典中。 如果它在字典中,它会将值更改为之前的值加 1(因为我们正在计算这个字符),否则它将在字典中添加一个初始计数为 1 的新条目
- 然后我们遍历文本变量中的每个字符,其中“i”代表一个单独的字符,我们保存并运行我们的函数来计算它们
- 最后,我们使用 OrderdedDict 导入按字母顺序对字典进行排序
第4步:画出来!
现在我们的数据集已创建,让我们将其组织成轴并绘制它!
我们将创建一个列表来表示每个轴
num_list = []
char_list = []
这些列表将相互对应,因此如果 char_list 中的第 1 项是“a”,则 num_list 中的第 1 项将是相应的频率。 让我们也把它编码出来。
我们使用两个变量循环遍历我们创建的字典中的键/值对,然后将它们添加到我们的数据列表中。
最后让我们使用 matplotlib 创建并保存这个条形图。
- 首先,我们创建一个新图形。 图为整体窗口
- 向图中添加绘图
- 使用我们选择的数据添加条形图
- 下载图片
- 显示图像
是时候测试它了!
使用下面的代码运行您的文件,为我们的结果做好准备!
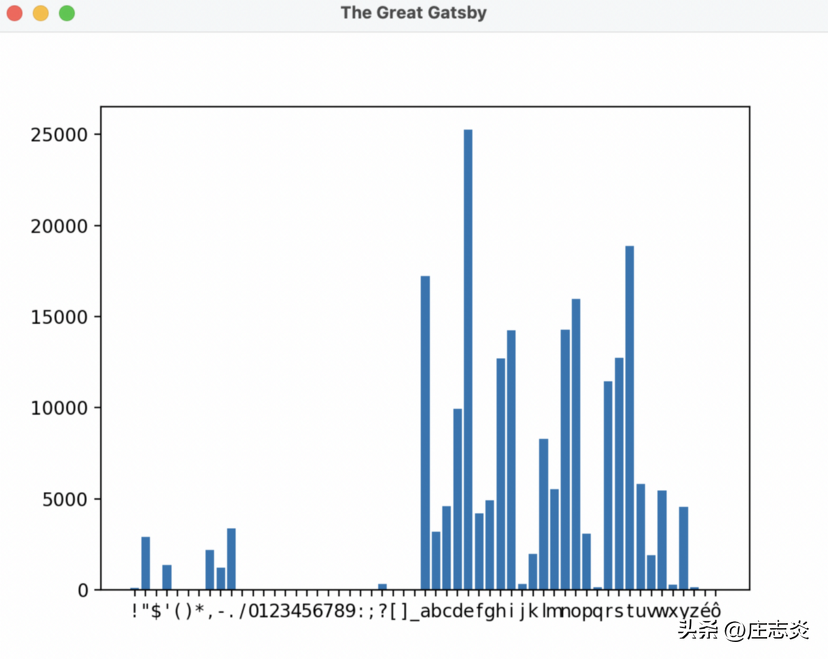
所以要回答我在文章开头提出的问题,字母 e 在《了不起的盖茨比》中被使用了超过 25,000 次! 哇!
结论
在本文结束时,我希望您对 matplotlib 和数据科学有所了解。