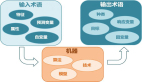
人工智能领域的下一个发展机会,有可能是给AI模型装上一个「身体」,与真实世界进行互动来学习。
相比现有的自然语言处理、计算机视觉等在特定环境下执行的任务来说,开放领域的机器人技术显然更难。

比如prompt-based学习可以让单个语言模型执行任意的自然语言处理任务,比如写代码、做文摘、问答,只需要修改prompt即可。
但机器人技术中的任务规范种类更多,比如模仿单样本演示、遵照语言指示或者实现某一视觉目标,这些通常都被视为不同的任务,由专门训练后的模型来处理。
最近来自英伟达、斯坦福大学、玛卡莱斯特学院、加州理工、清华大学和得克萨斯大学奥斯汀分校的研究人员共同提出一个基于Transformer的通用机器人智能体VIMA,利用多模态的prompt,实现极高的泛化性能,能够处理大量的机器人操作任务。

论文链接:https://arxiv.org/abs/2210.03094
项目链接:https://vimalabs.github.io/
代码链接:https://github.com/vimalabs/VIMA
输入prompt为交错使用的文字和视觉符号。
为了训练和评估VIMA,研究人员提出了一个新的模拟基准数据集,包含上千个由程序生成的带有多模态提示的桌面任务,和60多万条专家轨迹用于模仿学习,以四个等级来评估模型的泛化性能。
在同等尺寸的模型、等量训练数据的情况下,VIMA在最难的zero-shot的泛化设置下任务成功率为当下sota方法的2.9倍。
在训练数据减少10倍的情况下,VIMA的表现仍然比其他方法好2.7倍。
目前所有的代码、预训练模型、数据集和模拟基准都已完全开源。
论文的第一作者是Yunfan Jiang,斯坦福大学硕士二年级学生,目前在英伟达研究院实习。2020年本科毕业于爱丁堡大学。他的主要研究方向为具身人工智能(embodied AI),即通过与环境的互动来学习。具体研究内容为如何利用大规模的基础模型来实现开放式的的具身智能体(embodied agents)

论文包含两位导师,均为李飞飞曾经的学生。
朱玉可,本科毕业于浙江大学,并取得了浙江大学和加拿大西蒙弗雷泽大学的双学位。硕士和博士研究生就读于斯坦福大学,师从李飞飞,并于2019年8月取得博士学位。朱玉可现任UT Austin计算机科学系助理教授,同时是机器人感知和学习实验室的主任,以及英伟达研究院高级研究科学家。
范麟熙,博士毕业于斯坦福大学,师从李飞飞,目前是NVIDIA AI的研究科学家。主要研究方向为开发通用且强大的自主智能体(generally capable autonomous agents),具体的研究工作涵盖了基础模型、策略学习、机器人技术、多模式学习和大规模系统。
机器人与多模态prompt
Transformer在NLP领域多任务已经实现相当高的性能,仅一个模型就能同时完成问答、机器翻译、文本摘要等。
实现不同任务的接口就在于输入的文本提示,从而将具体的任务需求传递给通用大模型。
能不能把这种prompt接口用在通用机器人智能体上呢?
对于一个家务机器人来说,理想情况下,只需要输入给我拿<杯子的图像>,机器人就可以按照图片把杯子拿过来。
当机器人需要学习新技能时,最好可以通过输入视频演示就能学习。如果机器人需要与不熟悉的物体进行互动时,只需要通过图例即可轻松解释。
同时为了确保安全部署,用户可以进一步指定视觉约束,比如不要进入<图像>房间

为了实现这些功能,VIMA模型主要包含三部分:
1、 形式化多模态提示,将机器人操纵任务转化为一个序列建模问题;
2、一个新的机器人智能体模型,能够进行多任务操作
3、一个具有不同任务的大规模基准,以系统地评估智能体的可扩展性和通用性
首先,由多模态提示带来的灵活性可以让开发者指定和构建一个模型即可支持大量的任务规范,这篇论文中主要考虑六类任务:
1、简单物体操纵(Simple object manipulation),任务提示形如put <object> into <container>,其中对应的槽位为物体的图像;
2、实现视觉目标(Visual goal reaching),操纵物体实现目标设置,比如重新排列(rearragement);
3、接纳新概念(Novel concept grounding),提示中包含一些不常见的词,例如dax, blicket等,可以通过在提示内的图像进行解释,然后直接在指令中使用,可以测试智能体对新概念的认知速度;
4、单样本视频模仿(One-shot video imitation),观看视频演示,并学习如何以相同的移动路径对一个特定物体进行复现;
5、满足视觉限制(Visual constraint satisfaction),机器人必须小心地操纵物体,来避免触犯安全性限制;
6、视觉推理(Visual reasoning),有一些任务要求智能体需要会推理,比如「把所有和<object>相同纹理的物体都放到一个容器中」,或者要求视觉记忆,如「把<object>放到容器中,然后再放回到原位」
需要注意的是,这六类任务并非互斥,比如有的任务可能会通过演示视频(imitation)引入了一个之前没见过的动词(Novel Concept)
新基准VIM-BENCH
巧妇难为无米之炊,为了训练模型,研究人员同时准备了一些配套数据作为多模态机器人学习基准VIMA-BENCH。
在仿真环境(Simulation Environment)上,现有的基准一般都是针对特定的任务规范,目前还没有一个基准能够提供丰富的多模态任务套件和全面的测试平台来有针对性地探测代理能力。
为此,研究人员通过扩展Ravens机器人模拟器来建立VIMA-BENCH,支持可扩展的物体和纹理集合,以组成多模态提示,并按程序生成大量的任务。
具体来说,VIMA-BENCH提供了17个带有多模态提示模板的元任务,可以被实例化为1000个独立的任务。每个元任务属于上述6种任务规范方法中的一种或多种。
VIMA-BENCH可以通过脚本化的oracle智能体生成大量的模仿学习数据。
在观察和行动(Observation and Actions)上,模拟器的观察空间包括从正视图和自上而下视图渲染的RGB图像,基准还提供真实的物体分割和边界框,用于训练以物体为中心的模型。
VIM-BENCH从前人工作中继承了高级动作空间,由最基础的运动技能组成,如「取放」、「擦拭」等,具体由终端效果的姿势所决定。
模拟器还具有脚本化的oracle程序,可以通过使用特权模拟器的状态信息,如所有物体的精确位置,以及多模态指令的基础解释,生成专家示范。
最终,研究人员通过预编程的oracles生成了一个大型的专家轨迹离线数据集用于模仿学习。数据集包括每个元任务的5万条轨迹,共计65万条成功的轨迹。
同时保留一个物体模型和纹理的子集方便评估,并将17个元任务中的4个用于zero-shot泛化性测试。
VIMA-BENCH的每个任务标准只有成功和失败,不存在中间状态的奖励信号。
在测试时,研究人员在物理模拟器中执行智能体策略,以计算出成功率,所有评估的元任务的平均成功率为最终报告的指标。
评估协议包含四个层次以系统地探测智能体的泛化能力,每一级都更多地偏离训练分布,因此严格来说一级比一级难。
1、放置泛化(Placement generalization):在训练过程中,所有的提示都是逐字逐句的,但在测试时,桌面上的物体放置是随机的。
2、组合泛化(Combinatorial generalization):所有的材料(形容词)和三维物体(名词)在训练中都能看到,但在测试中会出现一些新的组合形式。
3、新物体泛化(Novel object generalization):测试提示和模拟的工作空间包括新的形容词和物体。
4、新任务泛化(Novel task generalization):测试时带有新提示模板的新型元任务
VIMA模型
多模态prompt中总共包含三种格式:
1、文本,使用预训练的T5模型进行分词及获取词向量;
2、整个桌面的场景,首先使用Mask R-CNN识别出所有的独立物体,每个物体由一个bounding box和裁剪图像表示,然后使用一个bounding bo编码器和ViT分别进行编码。
3、单个物体的图像,同样使用ViT获得tokens,然后将结果序列输入到预训练的T5编码器模型中。

机器人控制器(Robot Controller),即解码器的输入为提示序列上进行多次交叉注意力层后的表示和轨迹历史序列。
这样的设计可以增强对prompt的连接度;更好地保留且更深地处理原始prompt tokens;更好的计算效率。
在测试阶段的实验设计,主要为了回答三个问题:
1、VIMA和之前的SOTA基于Transformer的智能体在多模态提示的多种任务上的性能对比;
2、VIMA在模型容量和数据量上的缩放性(scaling properties);
3、不同的视觉分词器,条件提示和条件编码是否会影响到最终的决策。
对比的基线模型包括Gato, Flamingo和Decision Transformer(DT)
首先在模型缩放(Model scaling)上,研究人员对所有方法从2M到200M参数量进行训练,编码器的尺寸始终保持为T5-base,在所有层次的zero-shot泛化性评估上,VIMA都绝对好于其他工作。
尽管Gato和Flamingo在更大尺寸的模型上性能有所提升,VIMA也仍然好于所有模型。

在数据缩放(Data scaling)上,研究人员对各个方法的训练数据采取0.1%, 1%, 10%和全量模仿学习数据集的不同实验,VIMA仅需1%的数据,就能实现其他方法用10倍的数据训练的L1和L2泛化性指标。在L4指标上,仅需1%的训练数据,VIMA就已经要比其他模型在全量数据上训练效果要好了。

在渐进泛化(Progressive Generalization)性能对比中,在面向更难的泛化任务中,没有采用任何微调。VIMA模型的性能倒退最少,尤其是从L1到L2和L1到L3,而其他模型退化超过了20%,这也意味着VIMA学习到了更泛化的策略,更健壮的表征。
参考资料:
https://arxiv.org/abs/2210.03094