













一、什么是堆
1.1 堆的定义
堆是一个完全二叉树;
堆中的每一个节点的值都必须大于等于(大顶堆)or小于等于(小顶堆)其子树中的每个节点的值;
1.2 堆上的操作
- 堆的存储
- 我们在前面二叉树的学习中就知道,完全二叉树最理想的存储方式便是数组,省去了左右节点的指针空间,而且不会造成很大的浪费。比如,节点位置为i,那么其左子树就存放在2i的位置,右子树就存放在2i+1的位置,其父节点在i/2的位置,向上向下索引都很快捷。
- 插入元素
- 我们一般都将待插入的数据作为一个节点放到当前堆的最后面,然后自下而上进行堆化操作。
在堆的最后面插入一个节点
自下而上进行堆化
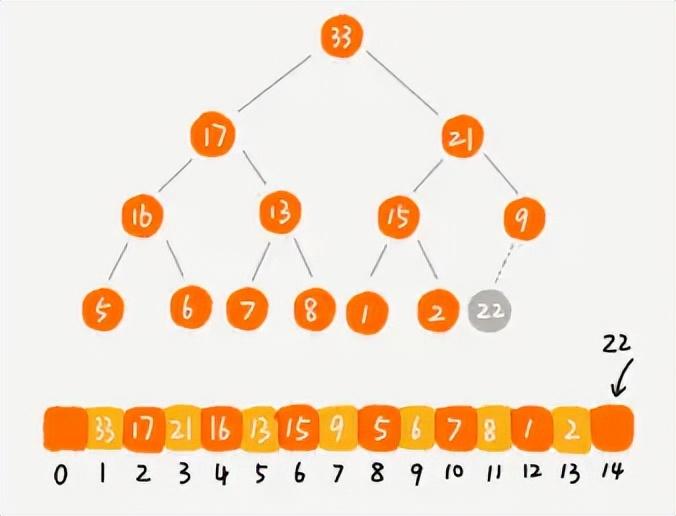
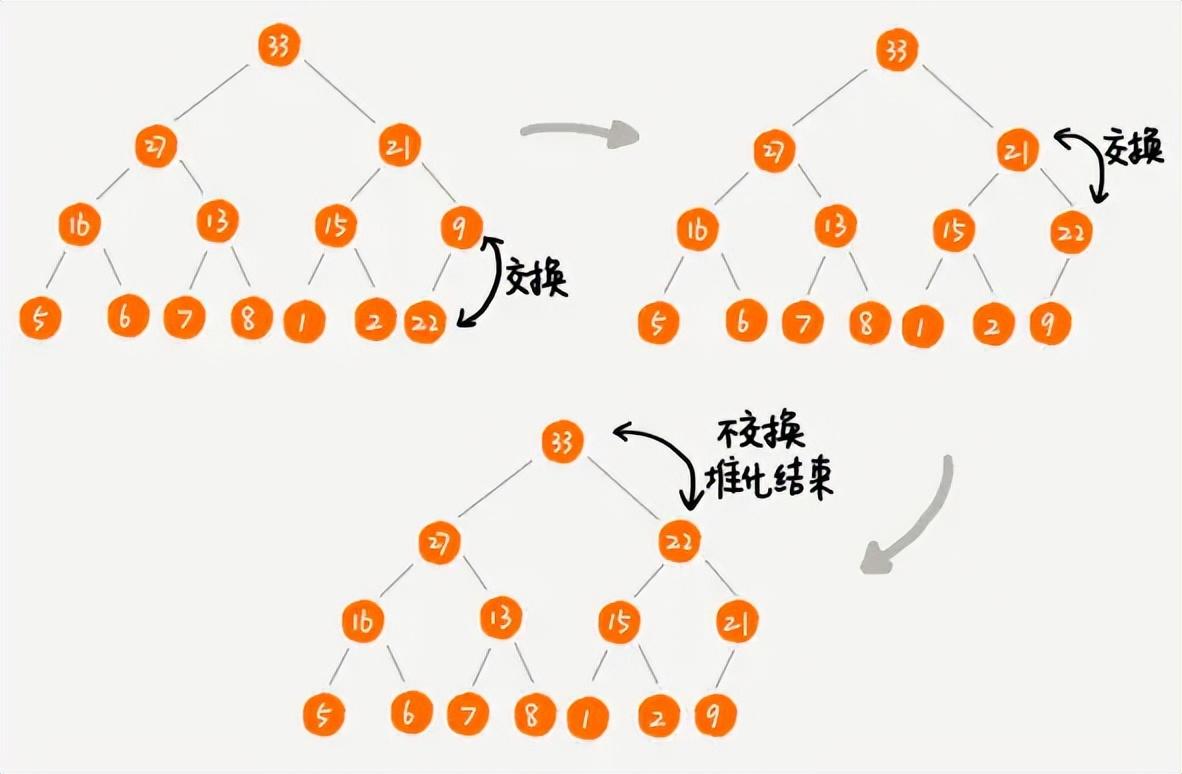
- 删除堆顶元素
- 堆一般都是进行删除堆顶元素,因为堆顶不是最大值就是最小值。一般不会删除非堆顶元素,这是堆这种数据结构的特性决定的。
- 我们先将堆中的最后一个元素赋值给堆顶元素,然后再删除最后一个元素,最后再进行自上而下的堆化操作。
删除堆顶元素的堆化操作
在如上插入和删除堆顶元素的操作中,主要的时间消耗都在堆化这个过程中,堆化操作需要比较和交换的次数最大不会超过树的高度,而前面我们说过,完全二叉树的高度是2的对数,因此插入和删除堆顶元素操作的时间复杂度是O(logn)。
二、 堆排序
给定一个数组,其中的元素都是无序杂乱的,我们怎么对它进行堆排序呢?
2.1 建堆
首先,我们需要将该数组建立为一个大顶堆(小顶堆),通常有以下两种建堆的方法:
- 自上而下
- 把下标为1的元素作为原始堆,然后从下标2开始直到n,依次插入前面的堆中,就像前面讲的插入元素操作一样,不断地进行堆化,然后形成一个大顶堆;其时间复杂度为O(nlogn),不够好。
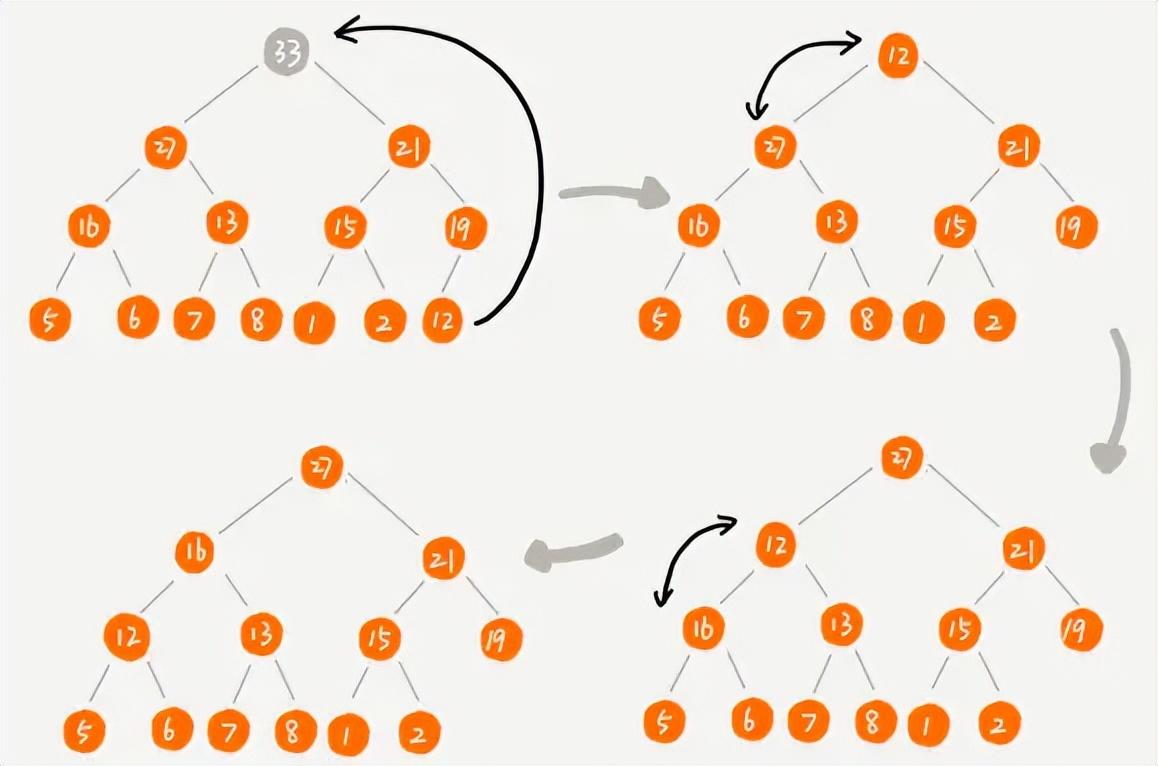
- 自下而上
- 我们注意到,在完全二叉树中,最后一个元素的下标除以2就能得到最后一个非叶子节点元素的下标n/2,光是叶子节点是无法进行堆化的,因此我们从n/2开始往前一直到下标为1为止不断进行堆化,然后形成一个大顶堆;此过程就类似删除堆顶元素之后的堆化过程;其时间复杂度为O(n),优于第一种。
建堆时自下而上进行堆化的过程
2.2 排序
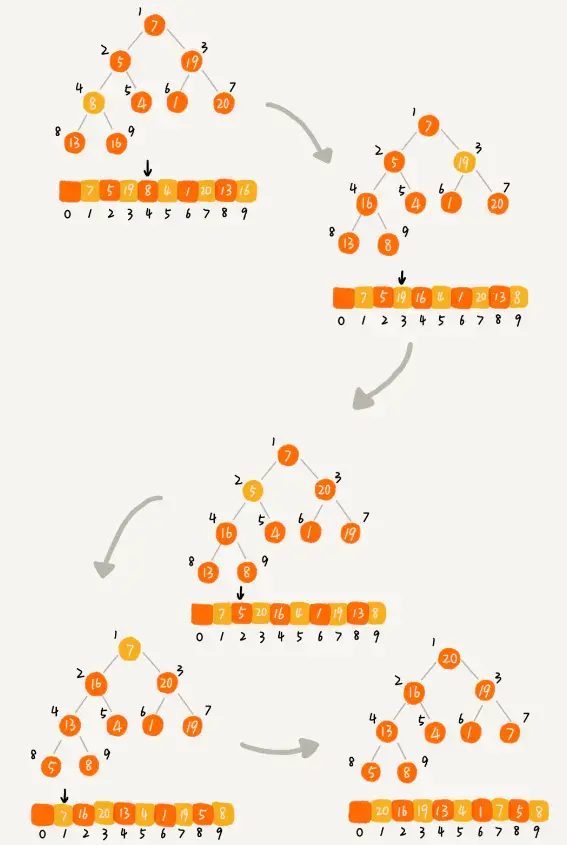
经过上一步的建堆操作,我们得到了一个大顶堆,但是数组中的数据看上去仍然是无序的,我们需要基于这个大顶堆把数组排下序。
首先从堆顶取出元素,这个元素肯定是最大的,把它和数组最后一个元素进行交换,放到位置n,然后堆中剩下的元素不断地进行堆化,并始终取堆顶元素依次放到n-1,n-2,n-3的位置上,当堆中只剩最后一个元素的时候,此时数组就是一个有序数列了。
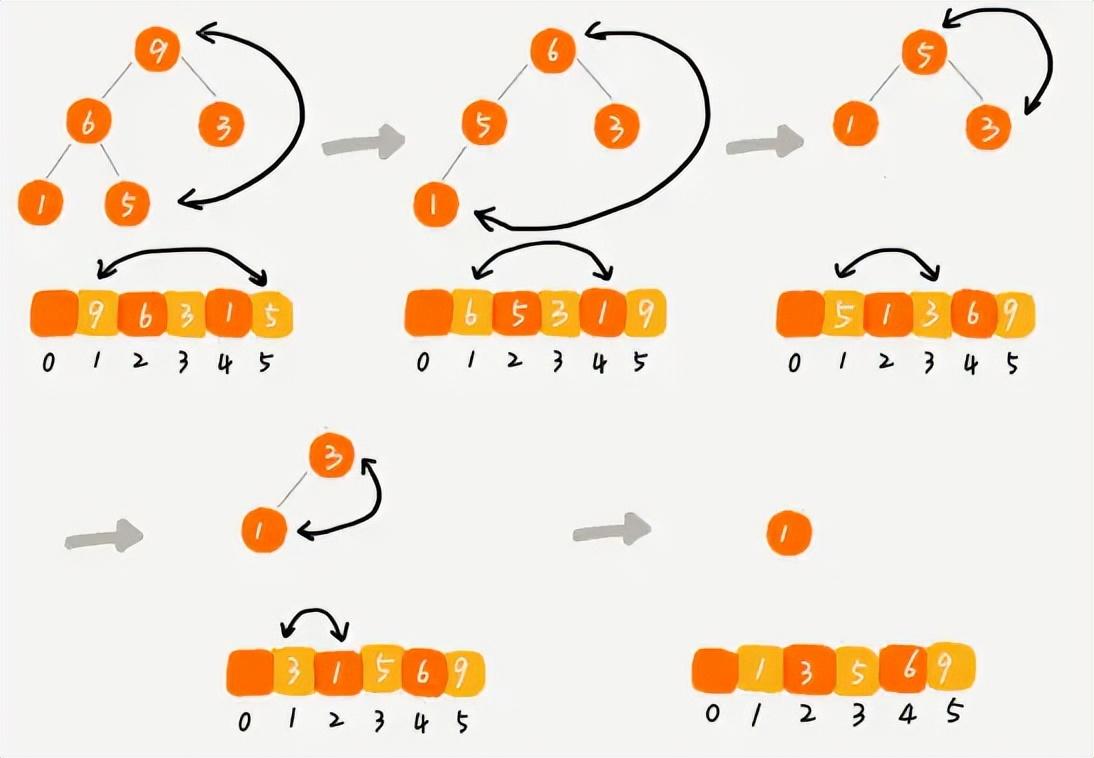
堆排序的过程示意
堆排序的过程中,我们需要对n个元素进行堆化操作,每次堆化操作时间复杂度取决于完全二叉树的高度,所以最终得到堆排序的时间复杂度为O(nlogn)。
堆排序不需要借助很多的额外存储空间,因此它属于原地排序;
堆排序过程中会可能改变相同值的位置,所以不是稳定的排序算法;
2.3 堆排序和快速排序的比较
虽然堆排序和快速排序时间的时间复杂度都是O(nlogn),但通常都认为堆排序的性能是比不上快速排序的。
- 堆排序的堆化过程中,在比较和交换元素时,读取的数据并不是局部顺序的;快速排序就是局部顺序的;所以快速排序更加显得CPU缓存友好,性能也会相对较好;
- 对于同样的数列,堆排序数据的交换次数要多于快速排序;
三、堆排序的应用
3.1 堆排序
如上已经讲解过了。
3.2 优先级队列
优先级队列中,数据的出队不是按照入队先后来决定的,而是按照优先级来的,优先级高(低)的就先出队,实现优先级队列的方法有很多,但是其中使用堆来实现是最为快捷高效的。比如Java中的PriorityQueue。
场景一:合并有序小文件
假设我们有n个小文件,每个大小为100MB,每个文件中存放的都是有序的字符串,我们如何把这n个小文件中的字符串有序地全都合并到一个大文件中呢?
这里有两个方法:
- 按照归并排序中的合并思路
- 设置n个指针各自指向每个文件的第一个字符串,将它们都加载到一个大小为n的数组中;
- 然后对数组进行遍历寻找最小元素,时间复杂度为O(n);并从数组中取出最小元素放到大文件中,将该元素从数组中删除;
- 将该元素来源的小文件中的指针移向下一位取出元素放到数组中,然后重复第二步;
- 使用小顶堆
- 设置n个指针各自指向每个文件的第一个字符串,将它们都加载到一个小顶堆中,初始是一个建堆的过程;
- 取出堆顶元素放到大文件中,并将该元素从小顶堆的堆顶删除,小顶堆会自动进行堆化;
- 将该元素来源的小文件中的指针移向下一位取出元素插入小顶堆中,小顶堆会自动进行堆化,然后重复第二步;
- 我们可以看到,这两种方法的区别在于,前者需要每次遍历数组找到最小值,后者则是有删除和插入两个堆化的过程。堆化过程的时间复杂度为O(logn),明显比遍历数组的O(n)要好,所以方法二更加高效。
场景二:实现高性能定时器
假设我们使用定时器设置了很多个待执行的任务,那么如何实现定时触发这些提前设定好的任务呢?
这里说三个方法:
- 程序每隔一段很小的时间(比如1秒)就进行任务扫描,找到最近要执行的任务进行执行,这种方法其实就是每1秒都要去寻找最小值,每次的时间复杂都是O(n),而且,假设最近一个任务是定在2小时候执行的,那么这2小时内,扫描程序都是白执行的,浪费资源。这种方法并不推荐。
- 维护一个有序列表,比如使用快速排序,只要记住最小值的执行时间即可,等到了那个时间点程序再执行,如此扫描程序就不用一直去扫描了。
- 使用小顶堆来维护任务列表,记住堆顶任务的执行时间,等到了那个时间点程序再执行,如此扫描程序就不用一直去扫描了。
- 方法2和方法3其实是类似的,关键在于采取什么样的数据结构和算法来获取最小值。如果存在中途插入或者取消任务的情况,对于方法2来说,插入一个元素到有序列表中和从有序列表中删除一个给定元素时间复杂度是多少呢?假设我们采用效率最高的二分查找,那么是O(logn),但是插入和删除元素是要搬移元素的,这个时间是O(n),所以总的下来就是O(n);如果使用方法3,那么无论插入还是删除元素,都是一个堆化的过程,时间复杂度为O(logn),所以方法3中使用堆更加高效。
3.3 求解Top-k问题
假设存量数据量为n,我们需要从n中找到Top-k的元素,并且针对不断添加进来的数据,我们都要获取最新的Top-k元素,这种问题应该怎么处理呢?
- 先从n中取出前k个元素,组成一个小顶堆,此时堆顶元素是最小的,我们从K+1个元素开始,和堆顶元素进行比较,如果比堆顶元素小,那么不做处理,继续下一个;如果比堆顶元素大,那么把堆顶元素删除,并插入k+1这个元素;等到n个元素全部遍历完,那么小顶堆中的k个元素就是Top-k数据了;
- 对于外部不断添加进来的数据其实思路是一样的,把它当成数据源,不断地和堆顶元素比较,重复上面的步骤操作即可。
时间主要耗费在一开始k个元素的初始建堆O(logk)上,还有删除堆顶元素和插入新元素时的堆化O(logk)上;所以,总的时间复杂度应该为O(nlogk),比使用排序来获取Top-k的O(nlogn)还是要高效的。
3.4 求解中位数
对于一个无序的数列,怎么求出它的中位数呢?这要看数列是静态的还是动态的。
如果是静态的数列,那么我们先进行排序,比如快速排序O(nlogn),然后如果总数是奇数,那么中位数就在n/2+1的位置上;如果总数是偶数,那么中位数有两个,在n/2和n/2+1的位置上,随便取一个即可。总的时间复杂度就是排序算法的时间复杂度O(nlogn)。
那如果是动态数列呢,我们需要维护数列的有序性,那么势必要对新插入或者需要删除的数据进行查找,时间复杂度为O(n),还有数据搬移的O(n),所以就会变得很低效,我们需要使用堆来解决这个问题。
我们先将已有数据排序,然后维护一个大顶堆和一个小顶堆,其中小顶堆存放最大的n/2个数据,堆顶元素是这n/2中最小的,大顶堆存放剩下的元素,堆顶元素是最大的。此时,中位数就是大顶堆的堆顶元素。
当动态数据添加进来时,我们将待添加元素和大顶堆的堆顶元素进行比较,如果小于等于,那么就插入大顶堆中;否则就和小顶堆的堆顶元素比较,如果大于等于,就插入小顶堆中。此时,如果小顶堆中的个数超过了n/2,就需要不断地取出堆顶元素插入到大顶堆中,直至个数为n/2;如果小顶堆中的个数小于n/2,就需要不断地取出大顶堆的堆顶元素插入到小顶堆中,直至小顶堆个数为n/2;
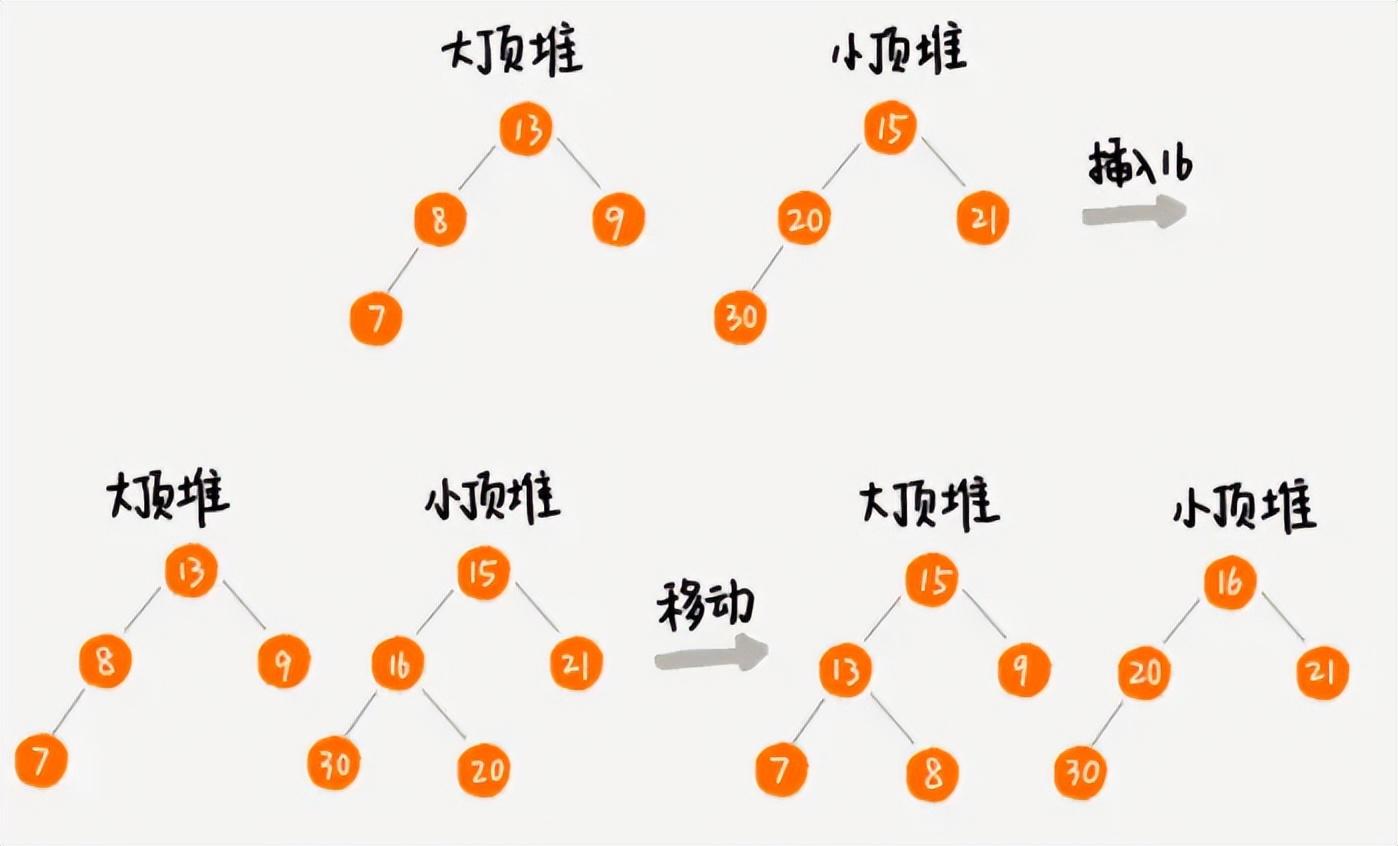
动态数列使用堆求解中位数过程示意
通过如上的过程,我们每次从大顶堆堆顶取出来的元素就是整个数列的中位数。整个过程的时间复杂度是多少呢?一开始初始化时的排序和建堆,由于数据比较少,可以算作常量;后续动态数据的插入或者删除,就是一个堆化的过程,时间复杂度为O(logn);大顶堆和小顶堆之间元素个数的调整不会有很多元素,所以也算作常数;因此,总的时间复杂度就是O(logn)。
既然动态数列求解中位数使用堆比较好,为什么静态数列求解中位数不使用堆,而是排序呢?静态数列也可以使用如上堆的方案进行求解中位数,但是时间复杂度也是O(nlogn),和排序是一样的,但是排序明显更加地简单,因此推荐使用排序的方案。
3.5 求解百分位数
求解中位数的问题其实就是求解百分位数问题的一种特殊情况, 中位数可以理解为百分位为50%,所以把中位数问题一般化的话,那么问题就是求解任意百分位数的问题。
思路和上述求解百分位是一样的,比如我们要求解90%百分位的数,那么大顶堆中需要存放90%的数据,小顶堆中存放10%的数据,当动态地增加时需要依次和大顶堆、小顶堆的堆顶元素进行比较以决定插入到哪个堆中;如果插入或者删除后,小顶堆中的数据占比不是10%了,就需要和大顶堆进行数据的交互以保证小顶堆数据的占比,如此才能保证大顶堆的堆顶元素就是我们需要的百分位数据。





















