前 言
经过前面索引和sql的优化后,现在查询速度快的飞起,然后,我们继续回归到了日常需求的开发中。
3个月过后,订单表的数据已经达到5000万了,不过sql一次查询的时间,基本稳定在300ms以下。
但是某个周一,leader刚开完周会就直接来找你了,直接说:“哎呀,周会上DBA找我了,说咱们订单组的sql偶尔会超过2s,DBA现在要求优化,平均时间要优化到300ms以下,不过,优化前你要先查下,为什么sql的查询时间会偶尔突增。”
问题排查
然后我们就接下了这个任务,接着,我们就根据DBA给的慢sql,去查这条sql的相关日志,然后结合着监控,最后发现这条sql平常一直很稳定,但是在高峰期的时候,这条sql偶尔花费的时间会超过2s。
此时,我们又查看了一下订单数据库所在物理机的资源占用情况,发现高峰期时,这台物理机的资源占用非常高,CPU和内存占用率都很高,这下基本就确定原因了。
说白了,就是一到高峰期,大量请求跑到MySQL这查询数据,此时就会有大量请求密集请求数据库,然后就会导致数据库所在机器的CPU和内存占用率都飙升,最终就会导致MySQL查询效率极速降低。
leader了解情况后说:“其实数据库查询慢,不一定就是MySQL数据量大导致的,比如当前这个情况,明显是大量请求密集请求数据库,造成数据库负载变大,从而大大降低了数据库的查询效率,这个时候,其实我们就需要在MySQL的前边,加上一层缓存,来进行流量削峰,以保证MySQL能稳定的完成查询”
经过leader一点拨,我们恍然大悟,原来是这样,说白了,这个时候我们可以加一些缓存,来为MySQL进行流量削峰,添加了缓存后的运行流程,大概是这样的:
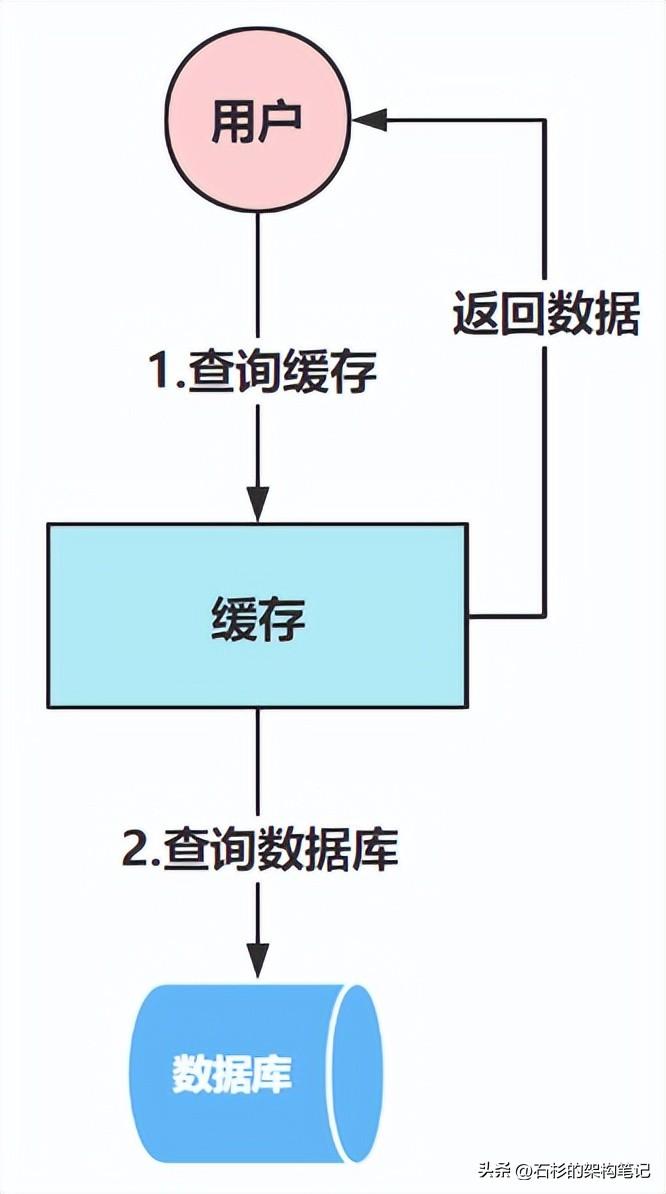
就是说,按照标准的请求流程,用户的请求是会打到数据库上的,但是加了缓存之后就不是这种流程了。这个时候请求可以直接从缓存中获取到数据并返回,此时就会减少后续流程的处理,比如查询数据库的操作,这样就有效降低了数据库的负载。
说白了,就是使用缓存来承接大多数的查询请求,达到流量削峰的效果,从而降低数据库的负载,以保证MySQL能稳定高效的完成查询,这样MySQL在高峰期查询时间突增的问题就可以完美解决了。
虽然缓存非常好用,但是使用缓存的过程中,我们要关注缓冲的命中率,命中率=返回正确结果数/请求缓存次数,命中率是衡量缓存有效性的重要指标,命中率越高,说明缓存的使用率越高。
除了要关注缓存命中率,我们还要了解缓存的清空策略,比如 先进先出策略FIFO(first in first out)、最少使用策略LFU(less frequently used) 和最近最少使用策略LRU(least recently used)。
如何提高缓存命中率
刚才我们也说了,命中率是衡量缓存有效性的重要指标,那么怎么才能提高缓存命中率呢?
其实要想提高缓存命中率,需要考虑的点有很多,大概有以下几点:
1.选择合适的业务场景
首先,缓存适合读多写少的场景,最好还是高频访问的场景,因为访问频率越高,命中率也就越高。
2.合理设置缓存容量
缓存容量如果太小的话,会触发Redis的内存淘汰机制,这样就会导致一些缓存key被删除,就会降低缓存命中率,所以,合理设置缓存容量是非常有必要的。
3.控制好缓存粒度
缓存的粒度越小,缓存命中率越高,因为单个key的数据单位越小的话,这个缓存就越不容易发生更改。
4.灵活设置缓存key的过期时间
这里说的是,要尽量避免缓存同时过期,如果缓存同时过期的话,假如此时有多个查询请求,那么这些请求就都会打到数据库上去。这种情况叫做缓存击穿,这会导致数据库的压力很大。
5.避免缓存穿透
先来了解下缓存命中率,比如当请求过来查询一条数据时,如果在缓存中没有查到这条数据,此时,我们可以说没有命中缓存,如果大量查询请求在缓存中都很少能查到数据,我们就可以说缓存命中率很低。
当缓存命中率很低时,因为在缓存中查不到数据,这个时候请求就会打到数据中,去数据库中查询数据,如果数据库中依然没有查到数据,说明这个请求已经穿透缓存了。
一旦缓存穿透了,当海量的请求涌来时,如果一直命中不了缓存,海量的请求就会转而涌向数据库,而数据库处理请求的能力是有限的,此时数据库可能因为请求量暴增压力过大而宕机,数据库一旦宕机,就很有可能演化成缓存雪崩,导致整个系统大面积的陷入瘫痪,这是非常恐怖的。
所以,我们需要提前做好兜底方案,以此来避免缓存穿透的发生,比如当一个查询请求过来时,如果缓存中没有查询到数据,数据库中也还是没有查询到数据,此时,我们可以在缓存中,给这个查询请求设置一个空对象,然后请求拿着这个空对象返回。
同样的查询请求下一次再过来时,直接就可以在缓存中命中这个空对象了,请求就不需要涌向数据库了,这样就算海量请求涌来时,也可以做到缓存命中率很高,缓存穿透的问题也就解决了。
6.做好缓存预热
一般来说,第一次查询的请求都会打到数据库上去,所以,我们可以提前将数据库的数据加载到缓存中,也就是缓存预热,这样的话第一次查询请求也可以直接走缓存了。
以上几点都做好的话,那么缓存命中率自然就提高了,好了,接下来废话也不多说了,我们一起来搞一把缓存实战,来切身感受下加了缓存后的查询效果。
缓存实战
场景介绍:历史订单查询
由于已完成的订单状态不会再发生变化,因此再进行历史订单查询时会将查询结果缓存进redis,并设置失效时间为一小时,因此在缓存失效前,用户再次查询历史订单时则会直接请求redis,减小数据库压力
未添加缓存的查询时间
Redis优化思路
查询历史订单时会先查询redis中是否有缓存,如有则直接返回redis中数据,如无则会查询MySQL,然后将查询数据返回,同时将查询结果设置到缓存中,以便下一次查询可以走缓存。
缓存Key的生成规则
用户id+页码+页数生成redis Key

缓存核心代码

缓存优化后的效果
加缓存后可以看到第二次请求时走了redis缓存查询,效率有了极大的提升。

然后,你加了缓存之后,发现效果确实不错,大量请求打到了缓存上,数据库的资源占用率也维持在一个合理的范围,sql查询时间也都稳定在了300ms以下。