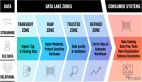
与连续处理实时工作负载的动态数据相比,为报告和分析存储静止数据需要不同的功能和服务等级协议(SLA)。目前有许多开源框架、商业产品和SaaS云服务。不幸的是,这些底层技术经常被误解,被过度用于单片和不灵活的架构,并被供应商用于错误的用例。本文将探讨面临的这个困境,了解如何使用原生云技术构建现代数据堆栈。
构建云原生数据仓库和数据湖的最佳实践
以下探索一下通过数据仓库、数据湖、数据流和湖屋构建原生云数据分析基础设施的经验和教训:
教训1:在正确的地方处理和存储数据
首先要问问自己:数据的用例是什么?
以下是一些数据用例示例和实现业务用例的示例工具:
- 管理循环报告=>数据仓库及其开箱即用的报告工具。
- 结构化和非结构化数据的交互式分析=>数据仓库或其他数据存储之上的商业智能工具,如Tableau、Power BI、Qlik或TIBCO Spotfire。
- 事务性业务负载=>在Kubernetes环境或无服务器云基础设施中运行的自定义Java应用程序。
- 高级分析,以了解历史数据=>存储在数据池中的原始数据集,用于应用强大的人工智能/机器学习技术(如TensorFlow)算法。
- 新事件的实时操作=>流式应用程序在相关数据时连续处理和关联数据。
(1)根据需要在正确的平台上进行实时或批量计算
批处理工作负载在为此而构建的基础设施中运行得最好。例如,Hadoop或ApacheSpark。实时工作负载在为此而构建的基础设施中运行得最好。例如ApacheKafka。
然而,有时两个平台都可以使用。了解底层基础设施,以最佳方式利用它。Apache Kafka可以替换一个数据库!尽管如此,它应该只在少数有意义的场景中进行(例如,简化架构或增加业务价值)。
例如,作为事件序列的可重播性(带有时间戳的保证顺序)内置于不可变的Kafka日志中。从Kafka中重放和重新处理历史数据是很直接的,也是很多场景的完美用例,其中包括:
- 新的消费者应用程序
- 错误处理
- 合规/法规处理
- 查询和分析已有事件
- 分析平台的模式变化
- 模型训练
另一方面,如果需要进行复杂的分析,如映射减少或变换、具有数十个join的SQL查询、传感器事件的健壮时间序列分析、基于摄取日志信息的搜索索引,等等。然后,最好选择Spark、Rockset、ApacheDruid或Elasticsearch作为用例。
(2)使用云原生对象存储实现分层存储以提高效率并降低成本
单个存储基础设施无法解决所有这些问题。因此,在上述用例中,将所有数据摄取到单个系统将无法成功。因此需要选择最好的方法。
现代的原生云系统将存储和计算分离开来。对于数据流平台(如Apache Kafka)和分析平台(如Apache Spark、Snowflake或谷歌Big Query)来说也是如此。SaaS解决方案实现了创新的分层存储解决方案(隐藏在内部,所以看不到它们,从而实现了存储和计算之间的低成本分离。
现代数据流服务也利用了分级存储。
第二个教训:不要为静止数据进行反向设计
问问自己:如果现在而不是以后处理数据(不管以后意味着什么),是否有任何额外的业务价值?
如果是,那么第一步不要将数据存储在数据库、数据湖或数据仓库中。数据在静止状态下存储,不再用于实时处理。如果在用例中实时数据优于慢速数据,那么像Apache Kafka这样的数据流平台是正确的选择!
研究发现,很多人把他们所有的原始数据放入数据存储中,只是为了发现他们可以在以后实时利用这些数据。然后,在启动反向ETL工具后,通过变更数据捕获(CDC)或类似方法再次访问数制湖中的数据。或者,如果使用Spark Structured Streaming(=“real-time”),但获取“实时流处理”数据的第一件事是从S3对象存储中读取数据(=“at rest and too later”)是不合适的。
(1)反向ETL不是实时用例的正确方法
如果将数据存储在数据仓库或数据湖中,则无法再实时处理数据,因为它已经在静止状态下存储。这些数据存储是为索引、搜索、批处理、报告、模型培训以及存储系统中有意义的其他使用案例而构建的。但是,不能从静态存储中实时处理动态数据。
(2)数据流是为实时连续处理数据而构建的
这就是事件流发挥作用的地方。像Apache Kafka这样的平台支持实时处理事务和分析工作负载的动态数据。
在现代事件驱动架构中不需要反向ETL!它“内置”到开箱即用的架构中。如果适当且技术上可行,每个使用者直接实时使用数据。数据仓库或数据湖仍然以接近实时或批量的速度处理数据。
同样,这并不意味着不应该将数据放在数据仓库或数据湖中。但只有在以后需要分析数据时才这样做。静态数据存储不适合实时工作。
教训3:不需要Lambda架构来分离批处理和实时工作负载
问问自己:用最喜欢的数据分析技术消费和处理传入数据的最简单方法是什么?
(1)实时数据胜过慢数据,但并不总是如此
考虑所在的行业、业务单位、解决的问题以及构建的创新应用程序。实时数据胜过慢数据。这种说法几乎总是正确的。或者增加收入,降低成本,降低风险,或者改善客户体验。
静态数据意味着将数据存储在数据库、数据仓库或数据湖中。这样,即使实时流组件(如Kafka)接收数据,数据在许多用例中处理得太晚。数据处理仍然是一个Web服务调用、SQL查询或map-reduce批处理过程,无法为问题提供结果。
静止的数据并不是一件坏事。有几个用例都可以很好地使用这种方法,例如报告(业务智能)、分析(批处理)和模型训练(机器学习) 。但在几乎所有其他用例中,实时性能优于批处理。
(2)Kappa架构简化了批处理和实时工作负载的基础设施
Kappa架构是一个基于事件的软件架构,可以实时处理事务和分析工作负载的任何规模的所有数据。
Kappa架构背后的核心前提是,可以使用单个技术堆栈执行实时处理和批处理。这是一种与众所周知的Lambda架构截然不同的方法。后者将批处理工作负载和实时工作负载分离到单独的基础设施和技术堆栈中。
Kappa基础设施的核心是流式结构。首先,事件流平台日志存储传入数据。从那里,流处理引擎可以持续实时地处理数据,或者通过任何通信范式和速度(包括实时、近实时、批处理和请求响应)将数据摄入任何其他分析数据库或业务应用程序。
教训4:理解静态数据共享和流数据交换之间的权衡
问问自己:需要如何与其他内部业务单位或外部企业共享数据?
(1)使用数据流、数据湖、数据仓库和数据湖屋进行混合和多云复制的用例
跨数据中心、区域或云计算提供商复制数据有很多理由:
- 灾难恢复和高可用性:创建灾难恢复集群,并在业务中断时时进行故障转移。
- 全球和多云复制:跨区域和云计算移动和聚合数据。
- 数据共享:与其他团队、业务线或企业共享数据。
- 数据迁移:将数据和工作负载从一个集群迁移到另一个集群(就像从传统的内部部署数据仓库迁移到云原生数据湖屋)。
(2)实时数据复制胜过慢速数据共享
围绕内部或外部数据共享的故事与其他应用程序并无不同。实时复制胜过缓慢的数据交换。因此,如果实时信息增加了业务价值,那么静态存储数据然后将其复制到另一个数据中心、区域或云提供者是一种反模式。
以下示例显示了独立利益相关者(即不同企业中的域)如何使用跨公司流数据交换:
创新不会止步于自己的边界。流复制适用于实时数据优于慢速数据的所有用例(适用于大多数场景)。举几个例子:
(3)从供应商到制造商到中间商再到售后的端到端供应链优化
- 跨越国家的追踪。
- 将第三方附加服务集成到自己的数字产品中。
- 开放API,用于嵌入和组合外部服务,以构建新产品。
另外,要理解为什么API(=REST/HTTP)和数据流(=Apache Kafka)是互补关系,而不是竞争关系。
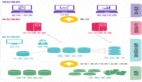
教训5:数据网格不是单一的产品或技术
问问自己:如何创建一个灵活和敏捷的企业架构来更有效地创新,并更快地解决业务问题?
(1)数据网格是逻辑视图,而不是物理视图
数据网格转变为一种借鉴现代分布式架构的范式:将域视为首要关注点,应用平台思维创建自助式数据基础设施,将数据视为产品,并实现开放标准化以实现可互操作的分布式数据产品生态系统。
下面是一个数据网格的例子:
数据网格结合了现有的范式,包括领域驱动设计、数据集市、微服务和事件流。
(2)数据仓库或数据湖不是也不可能成为整个数据网格
数据网格基础设施的核心应该是实时的、解耦的、可靠的和可伸缩的。Kafka是一个现代的云原生企业集成平台(如今也常称为iPaaS)。因此,Kafka为数据网格的基础提供了所有的功能。
然而,并不是所有的组件都可以或者应该是基于kafka的。微服务架构的美妙之处在于,每个应用程序都可以选择正确的技术。一个应用程序可能包含也可能不包含数据库、分析工具或其他补充组件。数据产品的输入和输出数据端口应独立于所选解决方案:
Kafka可以成为云原生数据网格的一个战略组件。但是,即使不使用数据流,只使用静止数据构建数据网格,也没有什么灵丹妙药。不要试图用单一的产品、技术或供应商构建一个数据网格。无论该工具是专注于实时数据流、批处理和分析,还是基于API的接口。Starburst是一个基于SQL的MPP查询引擎,由开源Trino(前身为Presto)提供支持,支持对不同数据存储进行分析。
(3)云原生数据仓库的最佳实践超越SaaS产品
构建原生云数据仓库或数据湖是一个庞大的项目。它需要数据摄入、数据集成、与分析平台的连接、数据隐私和安全模式等等。在报告或分析等实际任务开始之前,所有这些都是必需的。
超出数据仓库或数据湖范围的完整企业架构甚至更加复杂。必须应用最佳实践来构建一个有弹性的、可扩展、弹性的和具有成本效益的数据分析基础设施。服务等级协议(SLA)、延迟和正常运行时间在业务域中有非常不同的需求。最好的方法是为工作选择合适的工具。业务单元和应用程序之间的真正解耦允许专注于解决特定的业务问题。
存储和计算分离,统一的实时管道而不是批处理和实时分离,避免像反向ETL这样的反模式,适当的数据共享概念使云原生数据分析成为可能。