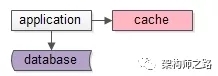
什么是 buffer pool
磁盘管理介绍完毕之后,在来看看内存的 buffer pool 管理的内容。
Buffer Pool 本质上就是一块共享内存区域,其目的主要是对磁盘上的 page 进行缓存,尽量减少磁盘 IO,提升数据库系统的性能。
前面讲存储模块的时候提到过,内存的访问速度更快,并且磁盘 page 的访问读取在时间和空间上具有局部性的特征,所以一次被访问到的 page,加载到内存之后,有可能被再次访问,这样可以避免频繁从磁盘中加载 page。
buffer pool 对内存区域划分为了被称为 frame 的小块,每个 frame 就是缓存了磁盘的 page 内容。
此外,还需要维护一个 page table,它是一个哈希表,存储的是 page id 对 buffer pool 中 frame 的一个映射,此外还需要存储一些 page 的元数据信息,例如 page 是否为脏页、page 的引用计数等等。

对于 page table 的访问,一般要保证并发安全,因为在多线程环境下,对于同一个内存中 frame 的读写不能同时进行。
PostgreSQL 中对于 buffer pool 的描述及代码可参考:https://github.com/postgres/postgres/blob/master/src/backend/storage/buffer/README
buffer pool 优化
前面简要说明了 buffer pool 的基本概念,在实际使用的时候,会针对 buffer pool 进行各种各样的优化,下面依次介绍常见的几种。
Multiple Buffer Pool
buffer pool 并不是一块内存进行划分,不同的数据库系统中,有不同的用法。
大多数系统都实现了可以开辟多个 buffer pool,避免多个线程对同一个 buffer pool 的锁竞争,这样能够更大程度上提升数据读写的效率。具体的实现可以是多样化的,例如:
- 创建多个 buffer pool 的实例
- 每个数据库分配一个 buffer pool
- 同类型的磁盘 page 分配一个 buffer pool
一般有两种方式来实现一条 tuple 到 buffer pool 的映射:object id 和 hashing。
Object ID 一般可以是一条 tuple 的隐藏列(例如在 PostgreSQL 中叫做 ctid),它主要记录了 tuple 的磁盘存储位置。根据这个 object id 就能够知道我们需要访问哪个 buffer pool,然后再获取其中的 page 进行数据读写。

另一种 hash 的方式,可以将 tuple 的某些信息进行 hash 操作,然后再定位到某一个 buffer pool上。

Pre-Fetching
prefetch 一般叫做预读取,例如当进行一个查询时,如果一个 page 不在 buffer pool,我们需要将 page 加载上来,此时我们可以通过一些预读取策略,预先将 page 记载到 buffer pool 中,这样下次查询的时候,不用读磁盘,能够提升整体的响应性能。
以一个简单的顺序扫描来说明,例如下图中,加载所有的 page 对表进行顺序扫描,如果没有 prefetch 的话,加载一个 page 之后,上层执行引擎处理完毕, 然后再次加载另一个 page,这样的话每次都会在加载的时候等待 page 加载完毕,效率较低。

如果是索引扫描,叶子节点指向的 page 有可能并不是连续的,但是作为数据库系统内部,我们可以识别出来,加载想要的 page 到 buffer pool 中(这也是上一篇文章中提到的数据库系统一般会自己管理内存,而不依赖于 mmap)。
例如下图,叶子节点的 page 分别是 3 和 5,这样的话加载的时候就跳过中间不需要的 page。

Scan Sharing
scan sharing 的思路总体来说就是如果一个 query 想要扫描一个表,此时已经有另一个查询也正在扫描这个表了,那么可以将两个查询的操作合并起来,共享同一个 page 的内容。
这个优化在大多数数据库中都有实现,例如 Sql Server、Oracle、PostgreSQL。
下面是一个简单的例子,假设有一个查询需要全表扫描,并且表内容分布在 page 0-5 中,那么它会依次读取所有的 page 到 buffer pool 中。

此时 Buffer Pool 满了,根据淘汰策略,在加载 page3 的时候,需要淘汰掉一个 page 出去,这里我们假设淘汰的是 page0。

淘汰掉 page0 后,然后将 page3 加载进来。
如果此时有另一个查询,也需要对这个表进行全表扫描,在没有任何优化的情况下,它也从头开始读写该 table 的所有 page。首先它也会去加载 page0,但实际上 page0 刚刚从 Buffer Pool 中被替换出去。

于是一个优化策略是将两个查询的扫描指针会合起来,共享同一个 Buffer Pool 中的内容,等到前面的结束之后,第二个查询再把前面没扫描到的 page 继续扫描完。
Buffer Pool Bypass
在一些特殊的情况下,我们可能并不需要 Buffer Pool,例如顺序扫描磁盘 page,如果我们需要加载的磁盘 page 的分布是连续的,我们可以直接加载磁盘数据,因为是顺序 IO,性能仍然能够不错,并且省去了 Buffer Pool 换入换出的开销。
PostgreSQL demo
下面以 postgres 为例,说明一下数据库 buffer pool 的具体行为。
postgres 的默认 buffer pool 大小是 128MB,当进行查询时,我们可以加上explain (analyze, buffers)前缀,打印 sql 执行的时间和详细计划,以及 buffer pool 的使用情况。
当首次启动系统时,没有任何数据在 buffer pool 中,因此一次查询需要从磁盘中获取所有的表数据,可以看下面的这个例子:

read 55140 表示从磁盘中获取的 page 数量。
当我们再次运行这个查询时,由于在前一次查询中已经将部分数据缓存在 buffer pool 中,因此相应的执行计划就会发生一些改变:

shared hit 表示命中了 buffer pool 中的数据,比前一次查询从磁盘中获取的 page 就会更少了。
buffer pool 淘汰策略
由于 buffer pool 是一块容量有限的内存区域,并且大小通常比存储在磁盘上的数据容量小得多,因此当 buffer pool 已满时,如果有新的数据需要加载,则需要合适的淘汰替换策略,来保证将旧的数据剔除掉,插入新的数据。
LRU
lru 即 Least Recently Used,最近最少使用原则,这是应用较为广泛的一种缓存淘汰算法了,思路也比较简单直观。
可以为每个 page 分配一个访问的时间戳,当访问了一个 page,则更新该时间戳。当需要淘汰旧的 page 时,直接选择最久未被访问的 page 即可。
Clock
clock 时钟淘汰算法跟 LRU 的思路比较类似,但是实现上不太一样。这种算法将 page 区域看做一个环,每个 page 都有一个标记为叫做 reference bit,初始情况下都为 0。

如果 page 被访问到了的话,则会将 reference bit 设置为 1。

一般会设定一个定时任务,然后我们可以顺序扫描每一个 page,如果 bit 值为 1,则说明该 page 被访问过,就将 bit 重置为 0。如果 bit 为 0,则说明该 page 没有被访问过,则直接清除这个 page。
LRU-K
前面提到的 LRU 算法虽然思路简单,但是也存在一些问题,如果一个频繁访问的热点 page,在短时间内被仅访问一次的页面所替换,那么会使缓存命中率下降,这种情况通常叫做缓存污染。
所以我们可以提升页面访问的次数上限,当达到 k 次时才能够替换其他的页面,所以不难理解传统的 LRU 算法可以看做是 LRU-1。
Localiztion
这种淘汰策略也能够缓解 LRU 可能产生的缓存污染问题,它实际上比较类似前面提到的 multi buffer pool,当多个 query 进行时,它可以从全局的 buffer pool 中获取 page 数据,但是当淘汰数据时,它可以自己再维护一个 buffer pool,在这个 buffer pool 中淘汰数据,不会对全局的 buffer pool 产生影响。
例如 PostgreSQL 在对表顺序扫描时会维护一个本地的 ring buffer 缓存。
Dirty Page
最后再来看一个简单的概念 dirty page。
dirty page,即脏页,指的是缓存在 buffer pool 中的数据被修改了,但是还没有来得及写到磁盘中。每个 page 都有一个相应的标志位,来表示自己是否是脏页。
如果一个 page 不是脏页,那么在替换该 page 时,系统可以直接将它从 buffer pool 中移除,反之,则需要将 page 中的数据持久化。
一般我们可以启动一个后台进程,定期对脏页进行处理,当将脏页数据写到磁盘后,可以将脏页从 buffer pool移除,也可以直接重置 page 的脏页标志位。
这一节讲述了内存缓冲区的管理,淘汰策略,以及它是怎么和磁盘 page 进行交互的,下一节会开始讲关于索引的部分。