今天跟大家分享一个并发编程领域中的一个知识点——同步工具类。
我将结合一个真实线上案例作为背景来展开讲解这一知识点。给大家讲清楚什么是同步工具类、适合的场景、解决了什么问题、各个实现方案的对比。希望对大家理解同步工具类这个知识点有所帮助。
我们先看一个案例:
需求描述
图一:逻辑架构图
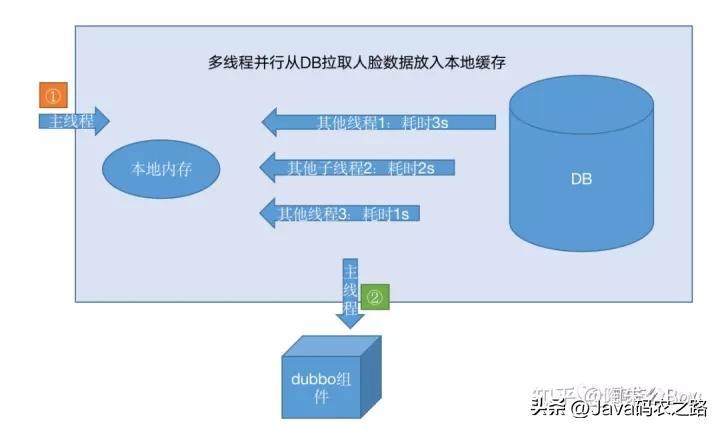
有一个线上“人脸识别”的应用,应用首次启动要求多线程并行将存储在DB中的人脸数据(512位的double类型数组)载入到本地应用缓存中,主线程需要等待所有子线程完成任务后,才能继续执行余下的业务逻辑(比如加载dubbo组件)。
拿到这个需求,大家不妨先思考一下,如果让你来实现,你打算怎么做?思考点是什么?
需求分析
让我们一起来分析一下这个需求:
首先这个需求是应用首次启动,需要用多线程并行执行任务的,充分利用CPU的多核机制,加快整体任务的处理速度。
其次大家先可以看下上述图一,多线程并行执行下,主线程需要等待所有子线程完成任务后才能继续执行余下的业务逻辑。
要实现这个需求,我们就要思考一下看有没有一种机制能让主线程等待其他子线程完成任务后,它再继续执行它余下的业务逻辑?
方案实现
方案一:Thread.join()
什么是join?
join方法是Thread类内部的一个方法,是一种一个线程等待另一个或多个线程完成任务的机制。
基本语义:
如果一个线程A调用了thread.join()方法,那么当前线程A需要等待thread线程完成任务后,才能从thread.join()阻塞处返回。
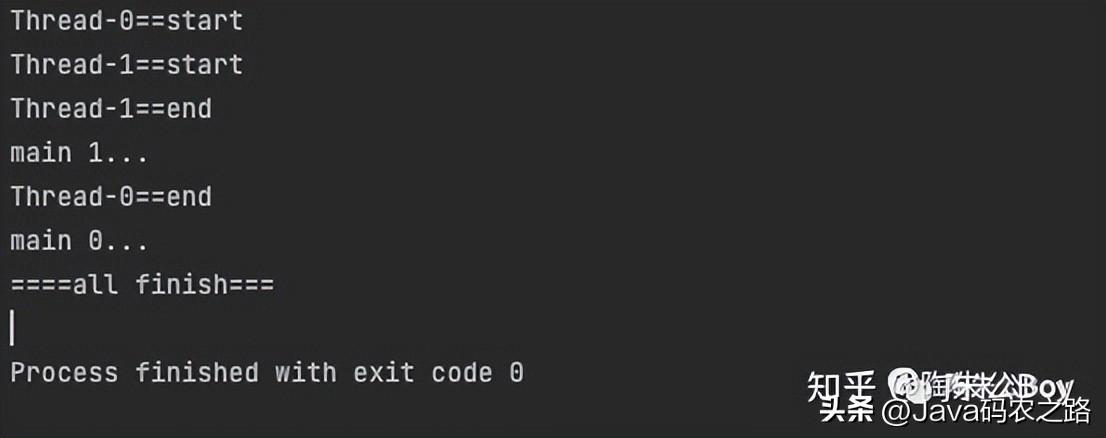
示例代码:
public class JoinDemo {
public static void main(String[] args) throws InterruptedException {
Thread thread0=new Thread(()->{
System.out.println(Thread.currentThread().getName()+"==start");
try {
Thread.sleep((long) (Math.random() * 10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"==end");
});
Thread thread1=new Thread(()->{
System.out.println(Thread.currentThread().getName()+"==start");
try {
Thread.sleep((long) (Math.random() * 10000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+"==end");
});
thread0.start();
thread1.start();
thread1.join();
System.out.println("main 1...");
thread0.join();
System.out.println("main 0...");
System.out.println("====all finish===");
}
}
结果打印:
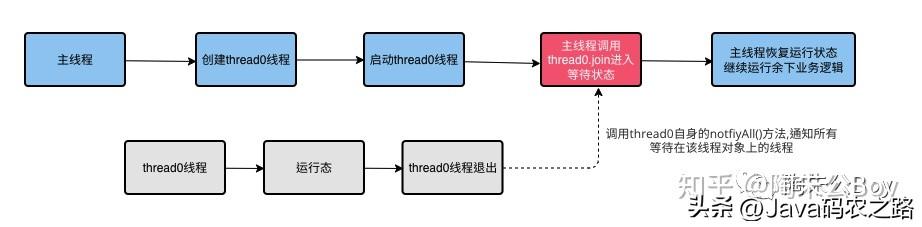
原理:
源码解析:

从源码细节来看(为了方便陈述,我们假设有一个线程A调用thread.join()),我们说线程A持有了thread对象的一把锁,while循环判断thread线程是否存活,如果返回false,表示thread线程任务尚未结束,那么线程A就会被挂起,释放锁,线程状态进入等待状态,等待被唤醒。
而唤醒的更多细节是在thread线程退出时,底层调用exit方法,详见hotspot关于thread.cpp文件中JavaThread::exit部分。如下(倒数第二行):
void JavaThread::exit(bool destroy_vm, ExitType exit_type) {
assert(this == JavaThread::current(), "thread consistency check");
...
// Notify waiters on thread object. This has to be done after exit() is called
// on the thread (if the thread is the last thread in a daemon ThreadGroup the
// group should have the destroyed bit set before waiters are notified).
ensure_join(this);
assert(!this->has_pending_exception(), "ensure_join should have cleared");
...
static void ensure_join(JavaThread* thread) {
// We do not need to grap the Threads_lock, since we are operating on ourself.
Handle threadObj(thread, thread->threadObj());
assert(threadObj.not_null(), "java thread object must exist");
ObjectLocker lock(threadObj, thread);
// Ignore pending exception (ThreadDeath), since we are exiting anyway
thread->clear_pending_exception();
// Thread is exiting. So set thread_status field in java.lang.Thread class to TERMINATED.
java_lang_Thread::set_thread_status(threadObj(), java_lang_Thread::TERMINATED);
//这里是清除native线程,这个操作会导致isAlive()方法返回false
java_lang_Thread::set_thread(threadObj(), NULL);
//唤醒等待在thread对象上的所有线程 lock.notify_all(thread); // Ignore pending exception (ThreadDeath), since we are exiting anyway
thread->clear_pending_exception();
}
方案二:闭锁(CountDownLatch)
什么是闭锁?
闭锁是一种同步工具类,可以延迟线程进度直到其达到终止状态。闭锁的作用相当于一扇门:在闭锁到达结束状态之前,这扇门一直是关闭的,并且没有任何线程能通过,直到到达结束状态时,这扇门将会永久打开。闭锁用来确保某些任务直到其他任务都完成后才继续执行。
基本语义:
countDownLatch的构造函数接收一个int类型的参数作为计数器,比如你传入了参数N,那意思就是需要等待N个点完成。当我们调用countDown方法时,这个计数器就会减1,await方法会一直阻塞主线程,直到N变0为止。
原理:
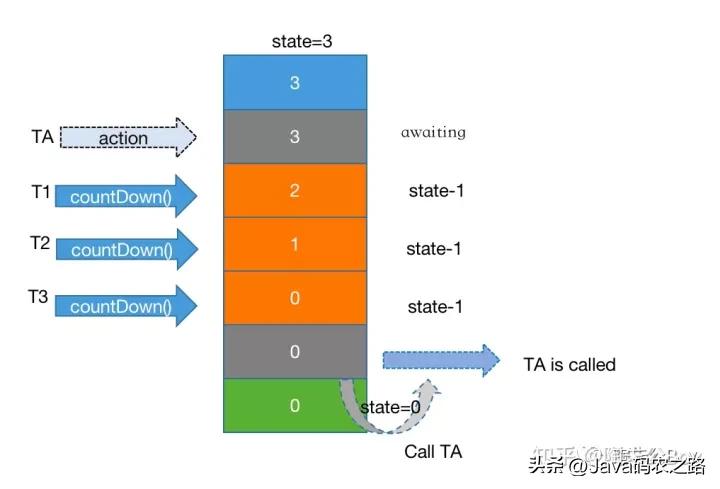
适用场景:
像应用程序首次启动,主线程需要等待其他子线程完成任务后,才能做余下事情,并且是一次性的。 像作者文章开始处提的这个需求,其实比较适合用CountDownLatch这个方案,主线程必须等到子线程的任务完成,才能进一步加载其他组件,比如dubbo。
示例代码:
public class CountDownLatchDemo {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(3);
final CountDownLatch latch = new CountDownLatch(3);
for (int i = 0; i < 3; i++) {
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
System.out.println("子线程" + Thread.currentThread().getName() + "开始执行");
//睡眠个几十毫秒
Thread.sleep((long) (Math.random() * 10000));
System.out.println("子线程" + Thread.currentThread().getName() + "执行完成");
latch.countDown();//当前线程调用此方法,则计数减一
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
service.execute(runnable);
}
try {
System.out.println("主线程" + Thread.currentThread().getName() + "等待子线程执行完成...");
latch.await(5,TimeUnit.SECONDS);//阻塞当前线程,直到计数器的值为0
System.out.println("阻塞完毕!主线程" + Thread.currentThread().getName() + "继续执行业务逻辑...");
service.shutdownNow();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
结果打印:子线程pool-1-thread-1开始执行
子线程pool-1-thread-2开始执行
子线程pool-1-thread-3开始执行
主线程main等待子线程执行完成...
子线程pool-1-thread-2执行完成
子线程pool-1-thread-1执行完成
子线程pool-1-thread-3执行完成
阻塞完毕!主线程main继续执行业务逻辑...
源码解析:
/**
* 静态内部类,自定义同步器组件
*/
private final Sync sync;
/**
* 只有一个构造方法,接收一个count值
*/
public CountDownLatch(int count) {
// count值不能小于0
if (count < 0) throw new IllegalArgumentException("count < 0");
// 自定义一个同步组件;通过继承AQS组件实现;
this.sync = new Sync(count);
}
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
// 使用构造函传递的参数值count作为同步状态值。
setState(count);
}
/** 获取当前的count值 */
int getCount() {
return getState();
}
/**共享式获取同步状态<br>
* 这是AQS的模板方法acquireShared、acquireSharedInterruptibly等方法内部将会调用的方法,
* 由子类实现,这个方法的作用是尝试获取一次共享锁,对于AQS来说,
* 此方法返回值大于等于0,表示获取共享锁成功,反之则获取共享锁失败,
* 而在这里,实际上就是判断count是否等于0,线程能否向下运行
*/
protected int tryAcquireShared(int acquires) {
// 此处判断state的值是否为0,也就是判断count是否为0,
// 若count为0,返回1,表示获取锁成功,此时线程将不会阻塞,正常运行
// 若count不为0,则返回-1,表示获取锁失败,线程将会被阻塞
// 从这里我们已经可以看出CountDownLatch的实现方式了
return (getState() == 0) ? 1 : -1;
}
/**共享式释放同步状态<br>
* 此方法的作用是用来释放AQS的共享锁,返回true表示释放成功,反之则失败
* 此方法将会在AQS的模板方法releaseShared中被调用,
* 在CountDownLatch中,这个方法用来减小count值
*/
protected boolean tryReleaseShared(int releases) {
// 使用死循环不断尝试释放锁
for (;;) {
// 首先获取当前state的值,也就是count值
int c = getState();
/**若count值已经等于0,则不能继续减小了,于是直接返回false
/* 为什么返回的是false,因为等于0表示之前等待的那些线程已经被唤醒了, *若返回true,AQS会尝试唤醒线程,若返回false,则直接结束,所以
* 在没有线程等待的情况下,返回false直接结束是正确的 */
if (c == 0)
return false;
// 若count不等于0,则将其-1
int nextc = c-1;
// compareAndSetState的作用是将count值从c,修改为新的nextc
// 此方法基于CAS实现,保证了操作的原子性
if (compareAndSetState(c, nextc))
// 若nextc == 0,则返回的是true,表示已经没有锁了,线程可以运行了,
// 若nextc > 0,则表示线程还需要继续阻塞,此处将返回false
return nextc == 0;
}
}
}
我们看下示例代码中关于latch.countDown()方法源码部分:
/**
* 此方法的作用就是将count的值-1,如果count等于0了,就唤醒等待的线程
*/
public void countDown() {
// 这里直接调用sync的releaseShared方法,这个方法的实现在AQS中,也是AQS提供的模板方法,
// 这个方法的作用是当前线程释放锁,若释放失败,返回false,若释放成功,则返回false,
// 若锁被释放成功,则当前线程会唤醒AQS同步队列中第一个被阻塞的线程,让他尝试获取锁
// 对于CountDownLatch来说,释放锁实际上就是让count - 1,只有当count被减小为0,
// 锁才是真正被释放,线程才能继续向下运行
sync.releaseShared(1);
}
/**
* 共享式的释放同步状态
*/
public final boolean releaseShared(int arg) {
// 调用tryReleaseShared尝试释放锁,这个方法已经由Sycn重写,请回顾上面对此方法的分析
// 若tryReleaseShared返回true,表示count经过这次释放后,等于0了,于是执行doReleaseShared
if (tryReleaseShared(arg)) {
// 这个方法的作用是唤醒AQS的同步队列中,正在等待的第一个线程
// 而我们分析acquireSharedInterruptibly方法时已经说过,
// 若一个线程被唤醒,检测到count == 0,会继续唤醒下一个等待的线程
// 也就是说,这个方法的作用是,在count == 0时,唤醒所有等待的线程
doReleaseShared();
return true;
}
return false;
}
接下来我们看下另一个比较重要的方法即await方法部分源码:
// 此方法用来让当前线程阻塞,直到count减小为0才恢复执行
public void await() throws InterruptedException {
// 这里直接调用sync的acquireSharedInterruptibly方法,这个方法定义在AQS中
// 方法的作用是尝试获取共享锁,若获取失败,则线程将会被加入到AQS的同步队列中等待
// 直到获取成功为止。且这个方法是会响应中断的,线程在阻塞的过程中,若被其他线程中断,
// 则此方法会通过抛出异常的方式结束等待。
sync.acquireSharedInterruptibly(1);
}
/**
*此方法是AQS中提供的一个模板方法,用以获取共享锁,并且会响应中断 */
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
// 首先判断当前线程释放被中断,若被中断,则直接抛出异常结束
if (Thread.interrupted())
throw new InterruptedException();
// 调用tryAcquireShared方法尝试获取锁,这个方法被Sycn类重写了,
// 若count == 0,则这个方法会返回1,表示获取锁成功,则这里会直接返回,线程不会被阻塞;否则返回-1
// 若count < 0,将会执行下面的doAcquireSharedInterruptibly方法,
// 此处请去查看Sync中tryAcquireShared方法的实现
if (tryAcquireShared(arg) < 0)
// 下面这个方法的作用是,线程获取锁失败,将会加入到AQS的同步队列中阻塞等待,
// 直到成功获取到锁,而此处成功获取到锁的条件就是count == 0,若当前线程在等待的过程中,
// 成功地获取了锁,则它会继续唤醒在它后面等待的线程,也尝试获取锁,
// 这也就是说,只要count == 0了,则被阻塞的线程都能恢复运行
doAcquireSharedInterruptibly(arg);
}
从源码细节来看,我们知道CountDownLatch底层是继承了AQS框架,是一个自定义同步组件。
AQS的状态变量被它当做了一个所谓的计数器实现。主线程调用await方法后,发现state的值不等于0,进入同步队列中阻塞等待。子线程每次调用countDown方法后,计数器减一,直到为0。这时会唤醒处于阻塞状态的主线程,然后主线程就会从await方法出返回。
方案三:栅栏(CyclicBarrier)
什么是栅栏?
CyclicBarrier字面意思是可循环(Cyclic)使用的栅栏(Barrier)。它的意思是让一组线程到达一个栅栏时被阻塞,直到最后一个耗时较长的线程完成任务后也到达栅栏时,栅栏才会打开,此时所有被栅栏拦截的线程才会继续执行。
基本语义:
CyclicBarrier有一个默认构造方法:CyclicBarrier(int parties),参数parties表示被栅栏拦截的线程数量。
每个线程调用await()方法告诉栅栏我已经到达栅栏,然后当前线程就会被阻塞,直到以下任一情况发生时,当前线程从await方法处返回。
- 最后一个线程到达
- 其他线程中断当前线程
- 其他线程等待栅栏超时;通过调用await带超时时间的方法。await(long timeout, TimeUnit unit)
- 其他一些线程在此屏障上调用重置
原理:
在CyclicBarrier的内部定义了一个Lock对象,每当一个线程调用await方法时,将拦截的线程数减1,然后判断剩余拦截数是否为初始值parties,如果不是,进入Lock对象的条件队列等待。如果是,执行barrierAction对象的Runnable方法,然后将锁的条件队列中的所有线程放入锁等待队列中,这些线程会依次的获取锁、释放锁。
适用场景:
1)实现多人游戏,直到所有玩家都加入才能开始。
2)经典场景:多线程计算数据,然后汇总结算结果场景。(比如一个Excel有多份sheet数据,开启多线程,每个线程处理一个sheet,最终将每个sheet的计算结果进行汇总)
示例代码:
public class CyclicBarrierTest2 {
static CyclicBarrier cyclicBarrier = new CyclicBarrier(2, new CalculateResult());
public static void main(String[] args) {
new Thread(() -> {
try {
System.out.println("线程A处理完sheet0数据...总计100");
cyclicBarrier.await();
} catch (Exception e) {
}
}).start();
try {
System.out.println("线程B处理完sheet1数据...总计200");
cyclicBarrier.await();
} catch (Exception e) {
}
}
static class CalculateResult implements Runnable {
@Override
public void run() {
System.out.println("【汇总线程】开始统计各个子线程的计算结果...,总计300");
}
}
}
响应结果打印:
线程B处理完sheet1数据...总计200
线程A处理完sheet0数据...总计100
【汇总线程】开始统计各个子线程的计算结果...总计300
★方案四:信号量(Semaphore)
什么是信号量?
信号量是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
基本语义:
从Semaphore的构造方法Semaphore(int permits)来看,入参permits表示可用的许可数量。如果我们在方法内部执行操作前先执行了acquire()方法,那么当前线程就会尝试去获取可用的许可,如果获取不到,就会被阻塞(或者中途被其他线程中断),直到有可用的许可为止。
执行release()方法意味着会释放许可给Semaphore。此时许可数量就会加一。
使用场景:
Semaphore在有限**公共资源**场景下,应用比较广泛,比如数据库连接池场景。
大家可以想象一下,比如我们平时在用的C3P0、druid等数据库连接池,因为数据库连接数是有限制的,面对突如其来的激增流量,一下子把有限的连接数量给占完了,那没有获取到可用的连接的线程咋办?是直接失败吗?
我们期望的效果是让这些没获取到连接的线程先暂时阻塞一会,而不是立即失败,这样一旦有可用的连接,这些被阻塞的线程就可以获取到连接而继续工作。
示例代码:
public class BoundedHashSet<T> {
private final Set<T> set;
private final Semaphore sem;
public BoundedHashSet(int bound) {
this.set = Collections.synchronizedSet(new HashSet<T>());
this.sem = new Semaphore(bound);
}
public boolean add(T o) throws InterruptedException {
sem.acquire();
boolean wasAdded = false;
try {
wasAdded = set.add(o);//如果元素已存在,返回false;否则true
return wasAdded;
} catch (Exception e) {
} finally {
if (!wasAdded) {//如果元素已经存在,则释放许可给信号量
sem.release();
}
}
return wasAdded;
}
public boolean remove(Object o) {
boolean wasRemoved = set.remove(o);
if (wasRemoved) {
sem.release();//从容器中移除元素后,需要释放许可给信号量。
}
return wasRemoved;
}
}
总结
上述需求的实现方案我例举了join、CountDownLatch、CyclicBarrier、Semaphore这几种。
期间也介绍了每种方案的实现原理、适用场景、源码解析。它们语意上有一些相似的地方,但差异性也很明显,接下来我们详细对它们进行一下对比。
首先我们说当前线程调用t.join()尽管能达到当前线程等待线程t完成任务的业务语义。但细致的区别是join方法调用后必须要等到t线程完成它的任务后,当前线程才能从阻塞出返回。而CountDownLatch、CyclicBarrier显然提供了更细粒度的控制。像CountDownLatch只要主线程将countDownLatch实例对象传递给子线程,子线程在方法内部某个地方执行latch.countDownLatch(),每调用一次计数器就会减1,直到为0,最后主线程就能感知到并从await阻塞出返回,不需要等到任务的完成。
其次我们说在当前线程方法内部,一旦出现超过2个join方法,整体代码就会变的很脏、可读性降低。反观JUC分装的CountDownLatch、CyclicBarrier等组件,通过对共享实例的操作(可以把这个实例传给子线程,然后子线程任务执行的时候调用相应方法,比如latch.countDown()) 显得更加清晰、优雅。
最后比较一下CyclicBarrier和CountDownLatch的差异性。比起CountDownLatch显然CyclicBarrier功能更多,比如支持reset方法。CountDownLatch的计数器只能使用一次,而CyclicBarrier可以多次使用,只要调用reset方法即可。(比如CyclicBarrier典型的数据统计场景,因为中途可能部分线程统计出错或外部数据的订正,可能需要重新再来一次计算,那么这个时候,CountDownLatch无能为力,而CyclicBarrier只要子线程调用reset方法即可)。
而Semaphore往往用来针对多线程并发访问指定有限资源的场景,比如数据库连接池场景。