一、什么是散列表
散列表是由数组扩展而来,其通过散列函数将元素的键值映射为下标,然后将元素存储在数组中对应下标的位置。
关键字经过散列函数的计算得到一个散列值:hash(key)=hashCode;关于散列函数的选择和设计,应该要满足如下三个要求:
- 散列值一定是一个非负整数;
- 如果key1 == key2,那么hash(k1) == hash(k2);
- 如果key1 != key2, 那么hash(k1) != hash(k2);
这三个条件中,最难满足的就是第三点,在现实中找一个这样的散列函数几乎是不可能的;比如著名的hash算法MD5、SHA、CRC等,都只是尽量均匀地散列,尽量避免散列冲突,但是做不到完全避免;而且由于数组空间有限,散列冲突就太正常不过了。
二、如何处理散列冲突
2.1 开放寻址法
线性探测
当散列冲突发生时,存储位置已经被占用,那么就往后探测查找空闲位置;
如果想在散列表中查找某个元素,那么先计算得到散列值,找到该值对应的存储空间,如果无值,说明要查找的元素不存在;如果有值,那么就比对值是否相等,相等则说明找到了,不相等那么就依次往后探测比较,要么找到,要么遇到空闲的存储空间,说明查找的元素不存在;
如果想在散列表中删除元素,那么不能将其简单地删除,因为删除后会导致该空间后面的元素查找失败,因为将需要删除的元素置为逻辑删除,如此才能不影响后面元素的查找过程;
线性探测方法弊端比较明显,极端情况下插入、查找、删除都需要探测n个元素才能找到目标位置,时间复杂度为O(n);
二次探测
其实是在线性探测的基础上每次探测增大步长,比如,每次探测当前次数的平方之后的位置,如此可以降低探测的次数的概率;但是不能解决线性探测同样的弊端问题;
双重散列
准备多个散列函数,如果第一个散列之后冲突了,就换一个散列函数,依次类推,直到找到空闲位置;但是一样的,当元素增多后,所有散列函数都可能造成散列冲突;
使用场景
当数据量比较小,且装载因子也比较小的时候,适合使用开放寻址法,比如ThreadLocalMap;
2.2 链表法
该种方法中,每个位置(可以称为桶、槽)对应一个链表,所有散列值相同的元素都放在该位置对应的链表中,结构示意图如下:
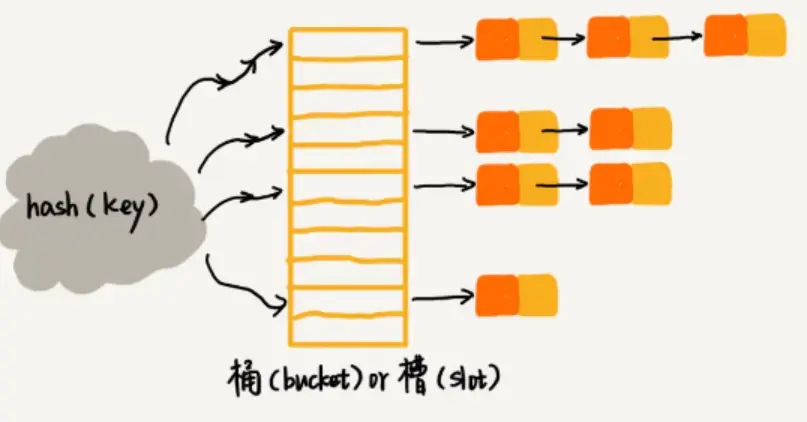
链表发解决散列冲突示意
当需要插入元素的时候,直接找到对应下标的插槽,插入链表即可,时间复杂度为O(1);
当需要查找和删除元素的时候,也是找到对应下标的插槽,然后遍历链表查找即可,时间复杂度为O(n/m),n是当前元素的个数,m是数组大小,假设散列是均匀的,那么时间复杂度就是链表的长度;
无论插入、查找还是删除,时间复杂度都要优于开放寻址法;
适用场景:
当需要存储的数据比较多,或者存储的是大对象的时候,链表法比较合适,而且链表的长度过长时可以采用灵活的优化策略,比如红黑树来代替链表,如此查找时间复杂度最坏情况下的O(n)就能优化为O(logn);
2.3 装载因子
装载因子=已经装入散列表中的元素个数/散列表总的位置个数
装载因子是用来衡量散列表当前盈满程度的指标,其越大,说明散列冲突的概率就越高,当达到一定程度,就需要对散列表进行扩容了。
开放寻址法中,装载因子不会超过100%,但是在拉链法中,装载因子是会超过100%的;
三、散列函数的设计
散列函数不能太复杂,否则计算散列值就需要花费很多时间和资源;
散列函数生成的值要尽可能随机并且均匀分布,最小化散列冲突,并避免某个槽中的链表过长;
装载因子需要根据实际情况进行设置,当超过阈值会触发散列表的扩容和rehash(重新申请一个大的散列表),时间复杂度将为O(n);当小于某个阈值会触发缩容和rehash;如果阈值设置地太大,就容易造成散列冲突,但如果设置地太小,就容易造成空间资源浪费;
为了避免扩容和rehash的影响,可以在装载因子达到阈值时先申请大的散列表,但是不做rehash,当有新的元素需要插入的时候,就插入到新的散列表中,并从旧的散列表中取小量的元素进行rehash,当插入若干新元素后,旧的散列表中的所有元素就能逐渐rehash到新的散列表,如此是将整个rehash均摊到每次插入新元素操作中,用户就不会感觉效率低了,此时的时间复杂度近似O(1);
四、散列表HashMap分析
初始大小默认为16,如果事先能知道数据量,可以在初始化的时候就设置相应的大小,避免动态扩容。
最大装载因子为0.75,触发扩容时,会扩容为原来的两倍。
当链表长度超过8时,链表就转换为红黑树,从而提高增删查改的效率;当红黑树元素个数小于8个的时候,就会再次转换会链表,因为小数据量时红黑树为了维护平衡,性能并不比链表高。
散列函数并不复杂,足够简单高效,并且分布均匀。
int hash(Object key){
// 键对象的
hashcodeint h = key.hashCode();
// capitity表示散列表的大小
return (h ^ (h >>> 16)) & (capitity - 1);
}
五、散列表LinkedHashMap分析
也是通过散列表和链表组合在一起实现的,只不过此处的链表不是单链表,而是双向链表,可以用来记录元素插入的顺序