从自动驾驶的架构出发往往最能够理解自动驾驶的原理,大众对自动驾驶最浅显易懂的理解就是感知,决策,执行。所有机器人都是这样的架构。

- 感知回答周围有什么的问题,类似人的眼睛,耳朵。通过摄像头,雷达,地图等手段获得周围障碍物和道路的信息。
- 决策回答我要如何做的问题,类似大脑。通过分析感知得来的信息,生成路径和车速。
- 执行则类似于手脚,将决策获得信息转化成刹车、油门和转向信号,控制车辆按照预期行驶。
接下来我们深入一层,问题开始有一些复杂。

我们在日常生活中可能会直觉的认为,我每时每刻在根据当下眼睛看到信息决定我下一步的决策,但情况往往并不是如此。从眼睛到脑袋再到手脚总是存在一个时间的延迟,自动驾驶也是如此。但我们不曾感受到影响是因为大脑会自动处理“预测”这件事情。哪怕只有几毫秒,我们的决策也是根据对所见之物的预测来指导手脚运作的,这是我们维持正常机能的基础。因此我们会在自动驾驶决策之前增加预测这个模块。
感知过程同样内藏乾坤,仔细推敲也分为两个阶段“传感”和“感知”。“传感”获得的是传感器的原始数据比如图片,而“感知”是从图片里处理出的有用信息(诸如图里有几个人)。古语常说“眼见为实,耳听为虚”。“感知”的有用信息又可以继续分为自车感知与外部感知,人亦或是自动驾驶汽车在处理这两大类信息时往往有不同的策略。
- 自车感知-由感受器官每时每刻获得的信息(包括摄像头,雷达,GPS等)
- 外部感知-由外部智能体或过往记忆,收集处理后转告的信息(包括定位,地图,车联信息等),前提需要自车定位感知(GPS)的输入。

另外各类传感器经由算法处理后的障碍物,车道等信息往往存在矛盾。雷达看到了前方有一个障碍物而摄像头告诉你没有,这时候就需要增加“融合”模块。对不一致的信息作进一步的关联和判断。
这里我们也常常把“融合与预测”归纳为“世界模型”。这个词非常生动,无论你是唯物主义还是唯心主义。“世界”都不可能全部塞进你的脑子里,而指导我们工作生活的是“世界”的“模型”,也就是通过对我们出生后的所见所谓加以处理,在脑中逐步构建的对世界的理解,道家称之为“内景”。世界模型的核心职责就是通过“融合”来理解当下环境要素的属性和关系,并配合“先验的规律”作出“预测”为决策执行提供更从容的判断,这个时间跨度可以从几毫秒到几小时。
由于世界模型的加入,整个架构变得更加丰满,但这里还一个细节常常被忽略。也就是信息的流向。简单的理解,人是通过眼睛感知再到大脑处理最后交给手脚执行的单向过程,可实际的情况往往更加复杂。这里有两个典型的行为构成了一个完全相反的信息流,那就是“目标达成的预案”以及“注意力的转移”。
“目标达成的预案”如何理解?实际上思考的伊始并非感知而是“目标”。有目标才可以触发一个有意义的“感知-决策-执行”过程,比方说你希望开车去一个目的地,可能你知道有几个路线,而你最后会权衡拥堵情况选择其中一个线路。拥堵情况属于世界模型,而“到达目的地”属于决策。这是一个决策向世界模型传递的过程。
“注意力的转移”又如何理解?哪怕是一张图片,无论是人类还是机器都无法获取内部隐含的所有信息。从一个需求和上下文出发,我们往往会把注意力放在一个有限范围和有限的品类上。这些信息无法从图片本身获得,而是来源于“世界模型”和“目标”,是一个从决策到世界模型再向感知传递的过程。
我们补充一些必要的信息,重新整理下整个架构,它变成了如下的模样,是不是又复杂了一些。还没完我们继续看。

自动驾驶算法和大脑一样,有一个对处理时间的要求。一般的周期在10ms-100ms之间,可以满足对环境变化的反应要求。但环境有时简单有时却非常复杂。很多算法模块无法达成这个时间要求。比如思考一遍人生的意义可能不是100ms可以搞定的事情,如果每走一步路都要思考一遍人生,对大脑一定是一种摧残。计算机也是如此,存在算力和运算速度的物理限制。解决方法就是引入分层框架。
这种分层机制越往上处理周期一般会缩短3-10倍,当然并不一定需要完整出现在实际框架当中,工程上根据板上资源以及算法使用情况可以灵活调整。基本上,感知是上行过程,根据注意力不断精细化特定要素,提供有“纵深和指向”的感知信息。决策是下行过程,根据不同层次的世界模型逐层从目标分解动作到每个执行单元。世界模型一般没有特定流向,用于构建不同粒度尺度的环境信息。
根据处理任务的复杂度,人员分工以及通讯环境也会进行适当的阉割与合并。比如低阶ADAS功能(ACC),算力较少,可以只设计一层。高阶ADAS功能(AutoPilot)一般会有两层的配置。而自动驾驶功能,复杂算法较多,三层的设计有时是必须的。在软件架构设计中,也存在同一层的世界模型与感知或是决策模块合并的情况。

各类自动驾驶公司或者行业标准都会发布自己的软件架构设计,但往往都是根据现状阉割后的结果,并不具有普适性,但为了方便大家理解,我还是把当下主流的功能模块代入进来,大家来看看对照关系,对理解原理更有帮助。

这里需要提前注意下,虽然这已经有点软件架构的意味,但仍然是一种对原理的描述,实际的软件架构设计相较于此还要更为复杂,这里并没有展开所有细节,而是把容易混淆的部分重点做了展开。下面我们重点梳理下。

环境感知-ALL IN深度学习
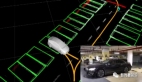
为了确保无人车对环境的理解和把握,无人驾驶系统的环境感知部分通常需要获取周围环境的大量信息,包括障碍物的位置,速度,前方车道的精确形状,标志牌的位置类型等。通常是通过融合激光雷达(Lidar),周视/环视相机(Camera),毫米波雷达(Millimeter Wave Radar)等多种传感器的数据来获取这些信息。
深度学习的发展,使得通过神经网络算法完成自动驾驶搭建成为全行业共识。感知模块的算法是整个深度学习化的“马前卒”,是最早完成转型的软件模块。
定位地图与V2X-自车感知与外部感知之间的关联与差异
传统意义上理解,外部感知是以GPS定位信号为基础,将高精地图和车联网消息(V2X)等绝对坐标系下的信息转化到自车坐标系下,供车辆使用的感知源。和人使用的高德导航仪类似。配合原本就在自车坐标系下的“自车感知”信息综合为自动驾驶提供环境信息。
但实际的设计往往更为复杂,由于GPS不可靠,IMU需要持续修正,可量产的自动驾驶定位往往使用感知地图的匹配来精确获得精确的绝对位置,利用感知结果来修正IMU获得精确的相对位置,和GPS-IMU组成的INS系统形成冗余。因此“外部感知”所必须的定位信号,往往依赖于“自车感知”信息。
另外虽然地图严格意义上属于“世界模型”的组成部分,但受限于GPS的敏感性,在国内进行软件实施的过程中,会把定位模块和地图模块进行整合,并加偏所有GPS数据,确保没有敏感定位信息的外泄。
融合预测模块-核心关注两者的差异
融合的核心是解决两个问题,一个是时空同步问题,利用坐标系转换算法和软硬协同的时间同步算法,首先将激光雷达,相机和毫米波雷达等感知测量结果对齐到一个时空点上,确保整个环境感知原始数据的统一。另一个是解决关联(Association)与异常剔除的问题,处理不同传感器映射到同一个“世界模型”元素(一个人/一根车道等)的关联,并且剔除可能由于单一传感器误检导致的异常。但融合区别于预测的根本是其只处理过去以及当前时刻的信息,并不会对外来时刻做处理。
而预测会基于融合的结果做出对未来时刻的判断,这个未来的时刻从10ms-5分钟皆有。其中包括对信号灯的预测,对周围障碍物行驶路径的预测或者是对远处的过弯位置做出预测。不同周期的预测会给到对应周期的规划,做不同粒度的预判,从而为规划的调整提供更大的空间。
规划控制-层次化策略分解
规划是无人车为了某一目标而作出一些有目的性的决策的过程,对于无人驾驶车辆而言,这个目标通常是指从出发地到达目的地,同时避免障碍物,并且不断优化驾驶轨迹和行为以保证乘客的安全舒适。规划的结构总结就是根据不同粒度的环境融合信息,从外部目标出发进行逐层的评估与分解,最终传递到执行器,形成完整的一次决策。
细分来看,规划模块一般会分成三层:任务规划(Mission Planning),行为规划(Behavioral Planning)和动作规划(Motion Planning)三层,任务规划核心是基于路网和离散路径搜索算法获得全局路径被给出大尺度的任务类型,往往周期较长,行为规划是基于有限状态机判断在一个中周期上,车辆应该采取的具体行为(左换道,绕行避让,E-STOP)并设定一些边界参数和大致的路径范围。运动规划层往往会基于采样或是最优化的方法最终获得满足舒适性,安全性要求的唯一路径。最后交由控制模块通过前馈预测和反馈控制算法完成对唯一路径的跟随,并操纵制动,转向,油门,车身等执行器最终执行命令。
不知道各位看官姥爷理解到了第几层,但以上这些也只是自动驾驶原理的入门内容,当下自动驾驶的理论,算法和架构发展都非常快,虽然上述内容是比较本源的知识点,很长时间内不会过时。但新增的需求给自动驾驶的架构和原理都带来了很多全新的认知。