前 言
各位读者朋友,大家好,这是分库分表实战的第一篇文章,首先介绍一下”基于ShardingSphere的分库分表实战“的设计思路及内容。
本实战的重点是分库分表实战,比较适合1~3年工作经验的程序员朋友。实战主要以外卖APP中的外卖订单来作为本次实战的核心业务。
基于外卖订单业务,儒猿技术团队开发了一个外卖订单项目,通过该项目逐步分析随着订单数据量逐步增加,系统将遇到什么问题。
并以这些问题为线索逐步分析,在分库分表之前,有没有一些方案可以初步解决这些问题,随着订单数据量的增加,为什么这些方案会失效,最后导致不得不分库分表。
而分库分表方案具体该如何设计?方案设计完成之后又该如何落地?分库分表方案引入之后又会带来什么新的问题?这些问题都可以在本实战中找到答案。
认识一下单库版本的订单系统
开始时,订单系统是用单库跑的,随着数据量的不断增大,系统将会采取各种措施逐步优化,比如索引和sql的优化、加缓存、上读写分离、垂直分库等方案,最后实在抗不住了才会进行分库分表。
从单库版本到分库分表版本的整个优化过程的基础是一个单库版本的外卖订单系统。
儒猿技术团队已提前使用Spring+SpringMVC+MyBatis开发实现了外卖订单系统,该单库版本的订单系统,整体架构图如下所示:
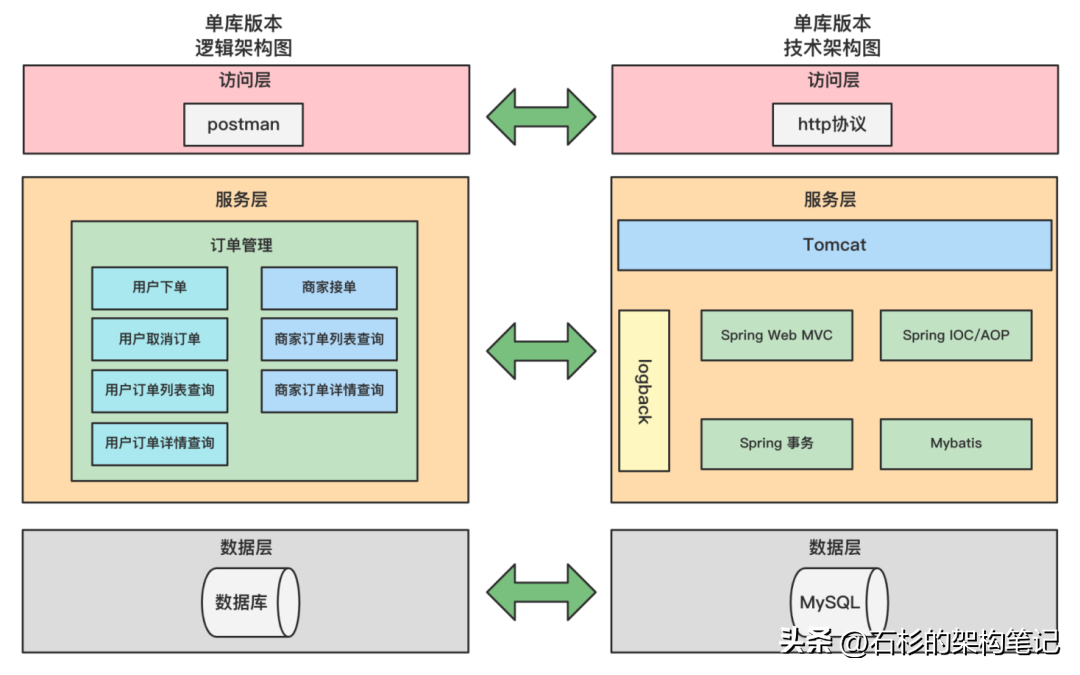
上图是单库版本订单系统的逻辑架构图和技术架构图的一个对比。该订单系统共分三层,分别是访问层、服务层和数据层。
1. 访问层:是调用后台服务的入口,这里直接使用postman来调用,因为重点是分库分表的方案落地,偏后端,所以直接使用postman来作为请求入口,非常的方便。
2. 服务层:是整个订单系统的核心,它提供了外卖订单系统的核心功能,比如用户下单、用户查询订单列表、商家接单等核心功能;而为了实现这些功能,使用了一些技术,比如使用Tomcat作为服务器来对外提供服务、使用Spring Web MVC作为web的开发框架、使用Spring IOC来管理bean、使用MyBatis来操作数据库、使用logback来记录日志。
3. 数据层:主要是用来存储外卖订单数据,这里使用的数据库是MySQL。
业务快速增长,驱动系统架构不断演进
这里设定一个背景,该外卖订单系统是位于一家初创型互联网公司的,目前积累的用户差不多10万的样子,每天活跃的用户大概就2万,每天相应的订单量也是2万的样子。

简单估算一下,一年的订单数据量也就七八百万的样子,单个数据库还是非常轻松抗住的。
索引和sql优化
但创业型公司的发展是比较迅猛的,如果踩对风口的话,用户会呈现爆发式的增长,这个时候外卖APP的用户量可能会迅速增长到了100万,日活用户20万,日订单20万,订单单表也从之前的几百万快速达到了2000万的级别,如下图:

令人担忧的是,随着时间的推移,订单单表的数据会继续快速增长,此时sql查询的性能开始慢慢下降,这时就要着手优化sql了。
此时先从索引和sql着手优化,展示sql优化的一般流程,这里将会有2个case,
- 隐式转换导致索引失效
- 一个是关于join连接查询的
引入缓存方案
优化案例 ——高峰期大量请求打到MySQL,导致数据库资源占用率很高,从而降低了MySQL的查询性能,最终导致订单sql查询突增到2s。
为了解决这个问题,引入缓存,如下图:
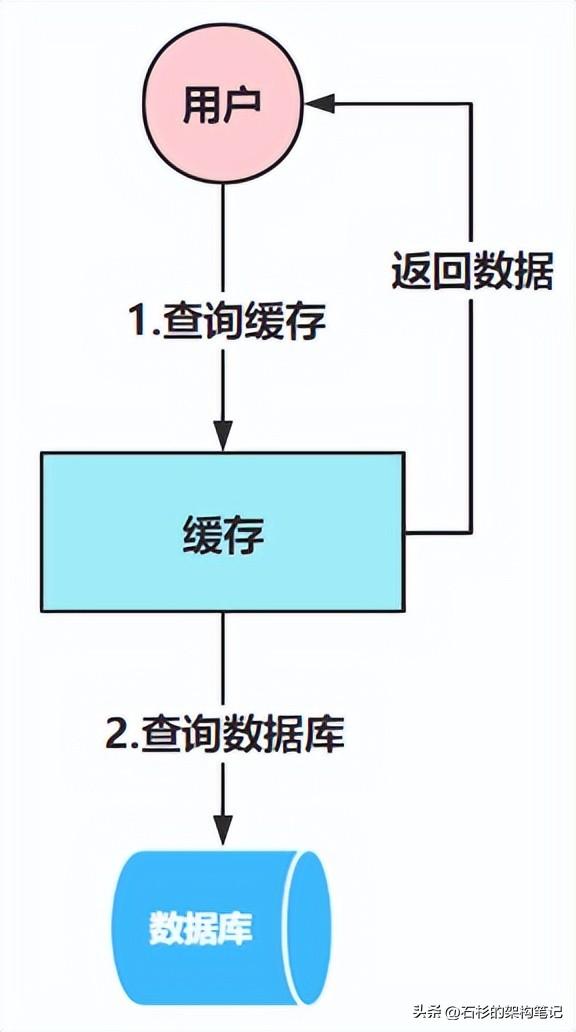
说白了,就是使用缓存来承接大多数的查询请求,这样到达数据库的请求就非常少了,数据库的资源占用率就会稳定在一个正常范围,从而使得订单sql的查询效率,不至于受到很大影响。
引入读写分离方案
优化案例 —— 由于促销活动的原因,大量下单的用户会不断刷新页面来查询订单信息,比如看一下订单是否开始配送,此时就会导致大量的请求打到MySQL上去。
此时单库又抗不了这么读请求,就导致了数据库负载很高,从而严重降低了订单sql的查询效率,最终导致在促销活动期间,订单sql的查询时间突增到2.5s。
促销活动期间对订单的操作,是典型的读多写少场景,为了解决这个问题,引入了读写分离的方案,如下图:
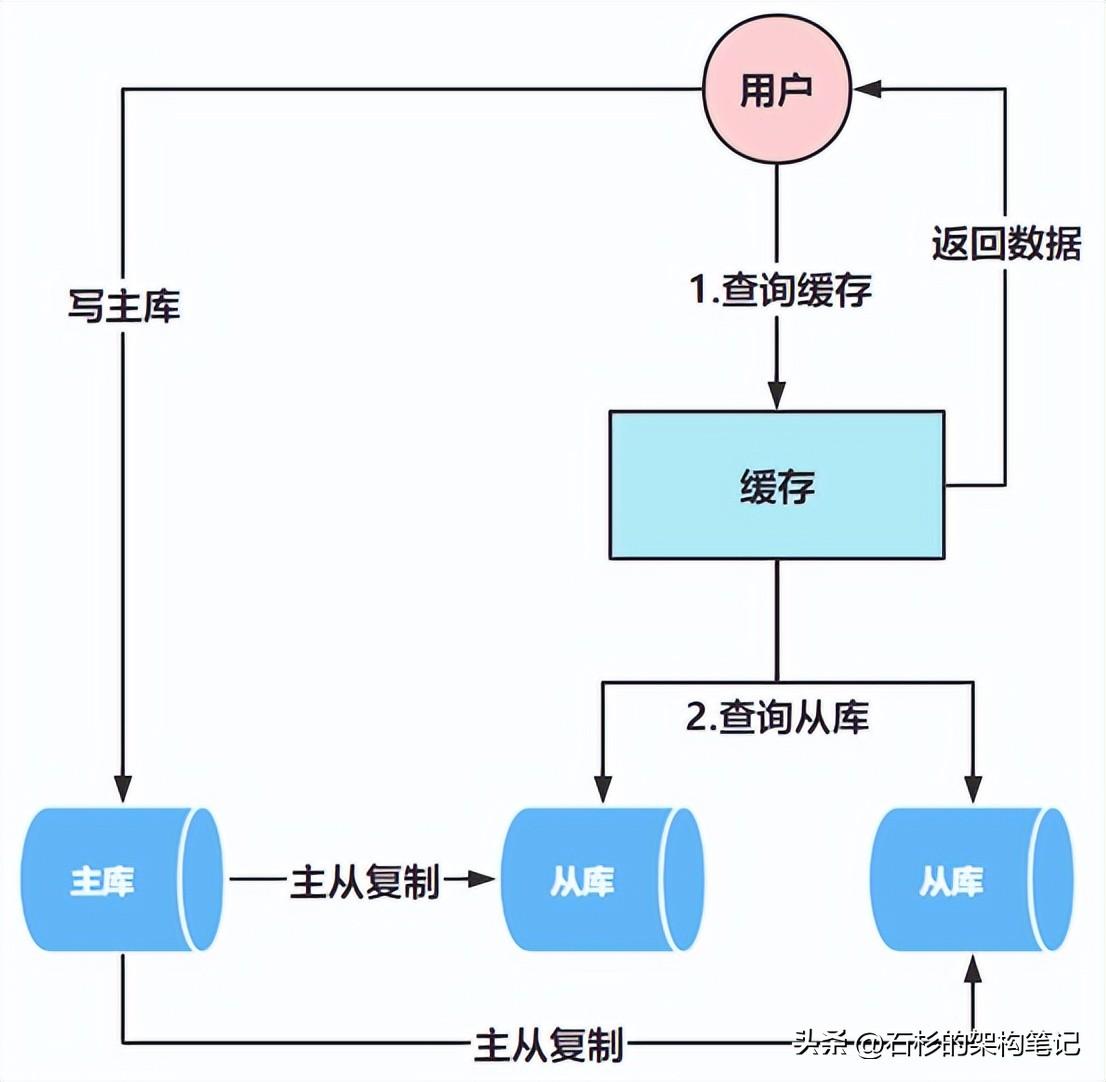
也就是写数据请求走主库,而读数据请求走从库,由于搞了2个从库,它们可以一起来抗住大量的读请求,订单sql的查询效率就可以得到显著的提升。
引入垂直分库方案
引入读写分离方案后可能又会遇到一个问题,那就是此时商品模块、订单模块、用户模块都部署在同一台物理数据库上,也就是主库上,此时这台物理数据库的CPU、内存和网络的负载能力,都是商品模块、订单模块、用户模块共用的。
如某天,商品模块做了一些活动,此时商品模块就会承接大量的读请求,尴尬的是商品模块并没有做读写分离,此时商品模块所处的这台物理数据库,它的CPU、内存和网络负载的占用都会很高。
关键是,数据库的资源是有限的,商品模块已经占用了大量的数据库资源,而订单模块能用的数据库资源就变得非常有限了,此时订单写数据的sql执行时间就可能突增到了2s,对于订单来说肯定是万万不能接受的。
所以,为了避免其他业务模块对订单模块的影响,将进行了垂直分库的改造,如下图:
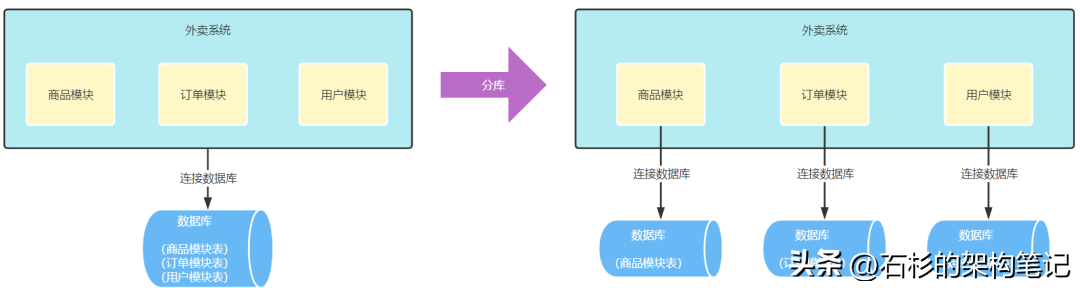
垂直分库后,每个业务都有自己独立的一台物理服务器,之前资源相互占用的问题也就不存在了,最终完美的解决了订单写数据时间突增的问题。
因为随着时间的推移,订单单表的数据量势必会越来越大,而订单sql查询的时间也会越来越慢,为了提高sql的查询效率,同时也为了更好的扩展性,最终得要引入这套分库分表的方案。
来看一下分库分表版本的订单系统架构
引入分库分表的方案后,外卖订单系统的系统架构如下图:

整个分层没有变化,分库分表后还是分为了三层,分别是访问层、服务层和数据层,还是从上到下逐一介绍:
1. 访问层:访问层使用的还是postman,这一层没有任何变化。
2. 服务层:
- 增加了根据路由key改写sql的功能,因为分库分表后会有多个库和表,比如订单库分为order_db_0和order_db_1。
- 每个数据库中有多个订单表,比如order_db_0中有订单表order_info_0和order_info_1,这个时候,如果要往数据库中插入订单或查询订单,为了确定数据落在哪个库的哪个表中,就需要根据路由key来改写sql了,根据路由key改写sql采用ShardingSphere来实现。
- 增加了数据迁移的功能,因为分库分表后,需要将之前单库中的数据迁移到新的库表中,比如这里分了8库8表,就会将原始单库中的数据迁移到新的8库8表中,数据迁移具体要用到全量同步、增量同步和数据验证等功能,数据迁移的功能会使用到canal和RocketMQ。
3. 数据层:还是使用MySQL,只不过会使用ShardingSphere来做sql改写和读写分离,然后在数据层还将引入缓存,缓存使用Redis来实现。
结束语
本节主要对整个外卖订单系统的背景、系统演进的过程、单库版本的系统架构和分库分表版本的系统架构,做了一个简单的介绍,后续就会围绕单库版本的订单系统来进行一步一步的优化,最终优化成分库分表版本的系统架构。
为了更好的阅读后续连载内容,建议读者认真查看单库版本和分库分表版本的系统架构图,了解当前订单系统架构是什么样子的,订单系统最终会做成什么样子,形成一个整体的认知。