













什么是全文搜索引擎?
常⽤的搜索⽹站,⽐如百度,⾕歌。


数据的分类
- 结构化数据:指具有固定格式或有限⻓度的数据,如数据库,元数据等。
对于结构化数据,我们⼀般都是可以通过关系型数据库(mysql,oracle等)的 table 的⽅式存储和搜索,也可以建⽴索引。通过b-tree等数据结构快速搜索数据。
- ⾮结构化数据:全⽂数据,指不定⻓或⽆固定格式的数据,如邮件,word⽂档等。
对于⾮结构化数据,也即对全⽂数据的搜索主要有两种⽅法:顺序扫描法,全⽂搜索法。
顺序扫描
- 按字⾯意思,我们可以了解它的⼤概搜索⽅式,就是按照顺序扫描的⽅式查找特定的关键字。⽐如让你在⼀篇篮球新闻中,找出"科⽐"这个名字在哪些段落出现过。那你肯定需要从头到尾把⽂章阅读⼀遍,然后标记出关键字在哪些地⽅出现过。
- 这种⽅法毋庸置疑是最低效的,如果⽂章很⻓,有⼏万字,等你阅读完这篇新闻找到"科⽐"这个关键字,那得花多少时间。
全⽂搜索
- 对⾮结构化数据进⾏顺序扫描很慢,我们是否可以进⾏优化?把我们的⾮结构化数据想办法弄得有⼀定结构不就⾏了吗?将⾮结构化数据中的⼀部分信息提取出来,重新组织,使其变得有⼀定结构,然后对这些有⼀定结构的数据进⾏搜索,从⽽达到搜索相对较快的⽬的。这种⽅式就构成了全⽂搜索的基本思路。这部分从⾮结构化数据中提取出的然后重新组织的信息,我们称之索引。
- 我们以NBA中国⽹站为例,假设我们都是篮球爱好者,并且我们是科密,那如何快速找到有关科⽐的新闻呢?全⽂搜索的⽅式就是,将所有新闻中所有的关键字进⾏提取,⽐如"科⽐","詹姆斯","总冠军","MVP"等关键字,然后对这些关键字建⽴索引,通过索引我们就可以找到对应的该关键词出现的新闻了。
什么是全⽂搜索引擎
根据百度百科中的定义,全⽂搜索引擎是⽬前⼴泛应⽤的主流搜索引擎。它的⼯作原理是计算机索引程序通过扫描⽂章中的每⼀个词,对每⼀个词建⽴⼀个索引,指明该词在⽂章中出现的次数和位置,当⽤户查询时,检索程序就根据事先建⽴的索引进⾏查找,并将查找的结果反馈给⽤户的。
搜索引擎
- Lucene
- Solr
- Elastic search
为什么不⽤mysql做全⽂搜索
前⾔
- 有⼈可能会问,为什么⼀定要⽤搜索引擎呢?我们的所有数据不是都可以放在数据库⾥吗?
- ⽽且 Mysql,Oracle,SQL Server 等数据库⾥不是也能提供查询搜索功能,直接通过数据库查询不就可以了吗?
- 确实,我们⼤部分的查询功能都可以通过数据库查询获得,如果查询效率低下,还可以通过新建数据库索引,优化SQL等⽅式进⾏提升效率,甚⾄通过引⼊缓存⽐如redis,memcache来加快数据的返回速度。如果数据量更⼤,还可以通过分库分表来分担查询压⼒。
- 那为什么还要全⽂搜索引擎呢?我们从⼏个⻆度来说
数据类型
全⽂索引搜索很好的⽀持⾮结构化数据的搜索,可以更好地快速搜索⼤量存在的任何单词⾮结构化⽂本。例如 Google,百度类的⽹站搜索,它们都是根据⽹⻚中的关键字⽣成索引,我们在搜索的时候输⼊关键字,它们会将该关键字即索引匹配到的所有⽹⻚返回;还有常⻅的项⽬中应⽤⽇志的搜索等等。对于这些⾮结构化的数据⽂本,关系型数据库搜索不是能很好的⽀持。
搜索性能
如果使⽤mysql做搜索,⽐如有个player表,这个表有user_name这个字段,我们要查找出user_name以james开头的球员,和含有James的球员。我们⼀般怎么做?数据量达到千万级别的时候怎么办?
select * from player where user_name like 'james%';
select * from player where user_name like '%james%';- 1.
- 2.
灵活的搜索
- 如果我们想查出名字叫james的球员,但是⽤户输⼊了jame,我们想提示他⼀些关键字
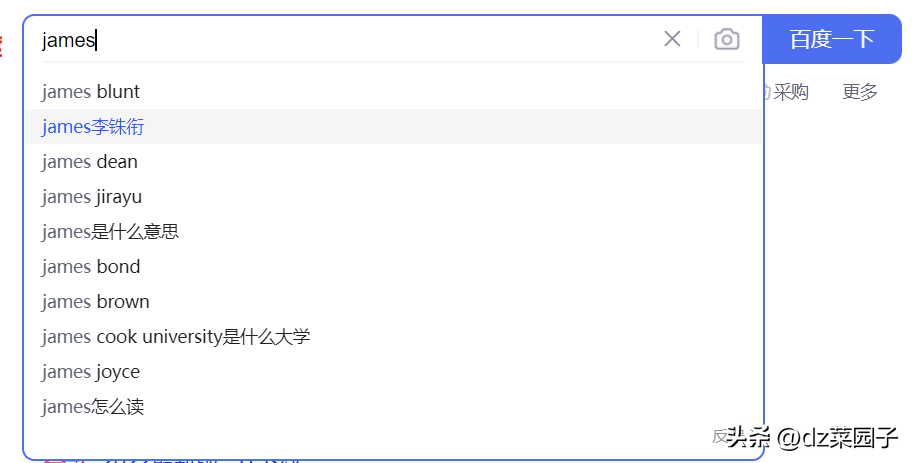
- 如果我们想查出带有"冠军"关键字的⽂章,但是⽤户输⼊了"总冠军",我们也希望能查出来。
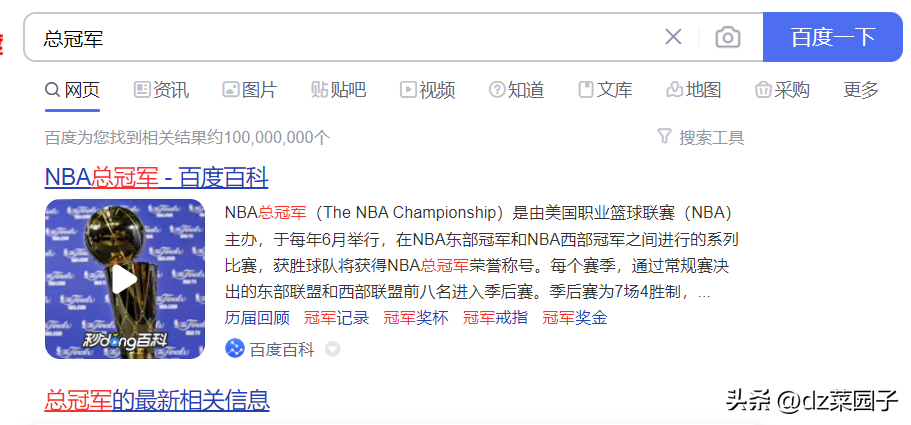
索引的维护
⼀般传统数据库,全⽂搜索都实现的很鸡肋,因为⼀般也没⼈⽤数据库存⻓⽂本字段,因为进⾏全⽂搜索的时候需要扫描整个表,如果数据量⼤的话即使对SQL的语法进⾏优化,也是效果甚微。即使建⽴了索引,但是维护起来也很麻烦,对于 insert 和 update 操作都会重新构建索引。
适合全⽂索引引擎的场景
- 搜索的数据对象是⼤量的⾮结构化的⽂本数据。
- ⽂本数据量达到数⼗万或数百万级别,甚⾄更多。
- ⽀持⼤量基于交互式⽂本的查询。
- 需求⾮常灵活的全⽂搜索查询。
- 对安全事务,⾮⽂本数据操作的需求相对较少的情况。
常⻅的搜索引擎
简介:常⻅的搜索引擎,Lucene,Solr,Elasticsearch
Lucene
- Lucene是⼀个Java全⽂搜索引擎,完全⽤Java编写。Lucene不是⼀个完整的应⽤程序,⽽是⼀个代码库和API,可以很容易地⽤于向应⽤程序添加搜索功能。
- 通过简单的API提供强⼤的功能
可扩展的⾼性能索引
强⼤,准确,⾼效的搜索算法
跨平台解决⽅案
- Apache软件基⾦会
在Apache软件基⾦会提供的开源软件项⽬的Apache社区的⽀持。
但是Lucene只是⼀个框架,要充分利⽤它的功能,需要使⽤java,并且在程序中集成Lucene。需要很多的学习了解,才能明⽩它是如何运⾏的,熟练运⽤Lucene确实⾮常复杂。
Solr
- Solr是⼀个基于Lucene的Java库构建的开源搜索平台。它以⽤户友好的⽅式提供ApacheLucene的搜索功能。它是⼀个成熟的产品,拥有强⼤⽽⼴泛的⽤户社区。它能提供分布式索引,复制,负载均衡查询以及⾃动故障转移和恢复。如果它被正确部署然后管理得好,它就能够成为⼀个⾼度可靠,可扩展且容错的搜索引擎。很多互联⽹巨头,如Netflflix,eBay,Instagram和亚⻢逊都使⽤Solr,因为它能够索引和搜索多个站点。
- 强⼤的功能
全⽂搜索
突出
分⾯搜索
实时索引
动态群集
数据库集成
NoSQL功能和丰富的⽂档处理
Elasticsearch
- Elasticsearch是⼀个开源,是⼀个基于Apache Lucene库构建的Restful搜索引擎.
- Elasticsearch是在Solr之后⼏年推出的。它提供了⼀个分布式,多租户能⼒的全⽂搜索引擎,具有HTTP Web界⾯(REST)和⽆架构JSON⽂档。Elasticsearch的官⽅客户端库提供Java,Groovy,PHP,Ruby,Perl,Python,.NET和Javascript。
- 主要功能
分布式搜索
数据分析
分组和聚合
- 应⽤场景
维基百科
Stack Overflflow
GitHub
电商⽹站
⽇志数据分析
商品价格监控⽹站
BI系统
站内搜索
篮球论坛
参考个人博客:cyz


















