













人工智能的三个层次:
运算职能:数据的存储和计算能力,机器远胜于人类。
感知职能:视觉、听觉等能力,机器在语音识别、图像识别领域已经比肩人类。
认知智能:自然语言处理、常识建模与推理等任务,机器还有很长的路要走。
自然语言处理属于认知智能范畴,由于自然语言具有抽象性、组合性、歧义性、知识性、演化性等特点,为机器处理带来了极大的挑战,有人将自然语言处理称为人工智能皇冠上的明珠。近些年来,出现了以 BERT 为代表的预训练语言模型,将自然语言处理带入了一个新纪元:预训练语言模型 + 特定任务精调。本文试图梳理自然语言预训练技术的演进之路,以期和大家相互交流学习,不足、谬误之处望批评指正。
1.古代 - 词表示
1.1 One-hot Encoding
用一个词表大小的向量表示一个词,其中词对应位置的值为1,其余位置为0。缺点:
- 高维稀疏性
- 无法表示语义相似性:两个同义词的 One-hot 向量相似度为0
1.2 分布式表示
分布式语义假设:相似的词具有相似的上下文,词的语义可由上下文表示。基于该思想,可以利用每个词的上下文分布对词进行表示。
1.2.1 词频表示
基于语料库,利用词的上下文构建共现频次表,词表的每一行代表了一个词的向量表示。通过不同的上下文选择可以捕获到不同的语言信息,如用句子中词的周围固定窗口的词作为上下文,会更多的捕捉到词的局部信息:词法、句法信息,若用所在文档作为上下文,更多的捕捉到词所表示的主题信息。缺点:
- 高频词问题。
- 无法反应高阶关系:(A, B) (B, C) (C, D) !=> (A, D)。
- 依然存在稀疏性问题。
1.2.2 TF-IDF表示
将词频表示中的值,替换为 TF-IDF,主要缓解词频表示的高频词问题。
1.2.3 点互信息表示
同样是缓解词频表示的高频词问题,将词频表示中的值替换为词的点互信息:

1.2.4 LSA
通过对词频矩阵进行奇异值分解 (Singular Value Decomposition,SVD),可以得到每个词的低维、连续、稠密的向量表示,可认为表示了词的潜在语义,该方法也被称为潜在语义分析 (Latent Semantic Analysis, LSA)。

LSA 缓解了高频词、高阶关系、稀疏性等问题,在传统机器学习算法中效果还是不错的,但是也存在一些不足:
- 词表大时,SVD 速度比较慢。
- 无法追新,当语料变化或新增语料时,需要重新训练。
2. 近代——静态词向量
文本的有序性及词与词之间的共现关系为自然语言处理提供了天然的自监督学习信号,使得系统无需额外的人工标注也能够从文本中学到知识。
2.1 Word2Vec
2.1.1 CBOW
CBOW(Continous Bag-of-Words) 利用上下文(窗口)对目标词进行预测,将上下文的词的词向量取算术平均,然后预测目标词的概率。

2.1.2 Skip-gram
Skip-gram 通过词预测上下文。

2.2 GloVe
GloVe(Global Vectors for Word Representation) 利用词向量对词的共现矩阵进行预测,实现了隐式的矩阵分解。首先根据词的上下文窗口构建距离加权的共现矩阵 X,再利用词与上下文的向量对共现矩阵 X 进行拟合:

损失函数为:

2.3 小结
词向量的学习利用了语料库中词与词之间的共现信息,底层思想还是分布式语义假设。无论是基于局部上下文的 Word2Vec,还是基于显式全局共现信息的 GloVe,本质都是将一个词在整个语料库中的共现上下文信息聚合到该词的向量表示中,并都取得了不错的效果,训练速度也很快,但是缺点词的向量是静态的,即不具备随上下文变化而变化的能力。
3. 现代——预训练语言模型
自回归语言模型:根据序列历史计算当前时刻词的条件概率。

自编码语言模型:通过上下文重构被掩码的单词。

表示被掩码的序列
3.1 基石——Transformer

3.1.1 注意力模型
注意力模型可以理解为对一个向量序列进行加权操作的机制,权重的计算。

3.1.2 多头自注意力
Transformer 中使用的注意力模型可以表示为:

当 Q、K、V 来自同一向量序列时,成为自注意力模型。
多头自注意力:设置多组自注意力模型,将其输出向量拼接,并通过一个线性映射映射到 Transformer 隐层的维度大小。多头自注意力模型,可以理解为多个自注意力模型的 ensemble。


3.1.3 位置编码
由于自注意力模型没有考虑输入向量的位置信息,但位置信息对序列建模至关重要。可以通过位置嵌入或位置编码的方式引入位置信息,Transformer 里使用了位置编码的方式。

3.1.4 其他
此外 Transformer block 里还使用了残差连接、Layer Normalization 等技术。
3.1.5优缺点
优点:
- 相比 RNN 能建模更远距离的依赖关系,attention 机制将词与词之间的距离缩小为了1,从而对长序列数据建模能力更强。
- 相比 RNN 能更好的利用 GPU 并行计算能力。
- 表达能力强。
缺点:
- 相比 RNN 参数大,增加了训练难度,需要更多的训练数据。
3.2 自回归语言模型
3.2.1 ELMo
ELMo: Embeddings from Language Models
输入层
对词可以直接用词的 embedding,也可以对词中的字符序列通过 CNN,或其他模型。

模型结构

ELMo 通过 LSTM 独立的建模前向、后向语言模型,前向语言模型:

后向语言模型:

优化目标
最大化:

下游应用
ELMo 训练好后,可以得到如下向量供下游任务使用。

是输入层得到的 word embedding, 是前、后向 LSTM 输出拼接的结果。
下游任务使用时,可以加各层向量加权得到 ELMo 的一个向量表示,同时用一个权重对 ELMo 向量进行缩放。

不同层次的隐含层向量蕴含了不同层次或粒度的文本信息:
- 顶层编码了更多的语义信息
- 底层编码了更多的词法、句法信息
3.2.2 GPT 系列
GPT-1
模型结构
在 GPT-1(Generative Pre-Training),是一个单向的语言模型,使用了12个 transformer block 结构作为解码器,每个 transformer 块是一个多头的自注意力机制,然后通过全连接得到输出的概率分布。


- U: 词的独热向量
- We:词向量矩阵
- Wp:位置向量矩阵
优化目标
最大化:

下游应用
下游任务中,对于一个有标签的数据集 ,每个实例有个输入 token:,它对于的标签组成。首先将这些 token 输入到训练好的预训练模型中,得到最终的特征向量。然后再通过一个全连接层得到预测结果:

下游有监督任务的目标则是最大化:

为了防止灾难性遗忘问题,可以在精调损失中加入一定权重的预训练损失,通常预训练损失。


GPT-2
GPT-2 的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。所以 GPT-2 并没有对 GPT-1 的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集,目标旨在训练一个泛化能力更强的词向量模型。
在8个语言模型任务中,仅仅通过 zero-shot 学习,GPT-2 就有7个超过了当时 state-of-the-art 的方法(当然好些任务上还是不如监督模型效果好)。GPT-2 的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。
同时 GPT-2 表明随着模型容量和训练数据量(质量)的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了 GPT-3。
GPT-3
依旧模型结构没啥变化,增加模型容量、训练数据量及质量,号称巨无霸,效果也很好。
小结

从 GPT-1 到 GPT-3,随着模型容量和训练数据量的增加,模型学到的语言知识也越丰富,自然语言处理的范式也从「预训练模型+精调」逐步向「预训练模型 + zero-shot/few-shot learning」转变。GPT 的缺点是用的单向语言模型,BERT 已经证明了双向语言模型能提升模型效果。
3.2.3 XLNet
XLNet 通过排列语言模型 (Permutation Language Model) 引入了双向的上下文信息,不引入特殊的 tag,避免了预训练和精调阶段 token 分布不一致的问题。同时使用 Transformer-XL 作为模型主体结构,对长文本有更好的效果。
排列语言模型
排列语言模型的目标是:

是文本序列所有可能的排列集合。
双流自注意力机制
- 双流自注意力机制 (Two-stream Self-attention)要达到的目的:通过改造Transformer,在输入正常文本序列的情况下,实现排列语言模型:
- 内容表示:包含的信息
- 查询表示:只包含的信息


该方法使用了预测词的位置信息。
下游应用
下游任务应用时,不需要查询表示,也不 mask。
3.3 自编码语言模型
3.3.1 BERT
掩码语言模型
掩码语言模型(masked language model, MLM),随机地屏蔽部分词,然后利用上下文信息进行预测。MLM 存在个问题,预训练和 fine-tuning 之间不匹配,因为在 fine-tuning 期间从未看到 [MASK] token。为了解决这个问题,BERT 并不总是用实际的 [MASK] token 替换被「masked」的 word piece token。训练数据生成器随机选择15%的 token,然后:
- 80%的概率:用 [MASK] 标记替换。
- 10%的概率:从词表随机一个 token 替换。
- 10%的概率:token 保持不变。
原生 BERT 里对 token 进行 mask,可以对整词或短语(N-Gram)进行 mask。
下一句预测
下一句预测(NSP):当选择句子 A 和 B 作为预训练样本时,B 有50%的可能是 A 的下一个句子,也有50%的可能是来自语料库的随机句子。
输入层

模型结构

经典的「预训练模型+精调」的范式,主题结构是堆叠的多层 Transformer。
3.3.2 RoBERTa
RoBERTa(Robustly Optimized BERT Pretraining Approach) 并没有大刀阔斧的改进 BERT,而只是针对 BERT 的每一个设计细节进行了详尽的实验找到了 BERT 的改进空间。
- 动态掩码:原始方式是构建数据集的时候设置好掩码并固定,改进方式是每轮训练将数据输入模型的时候才进行随机掩码,增加了数据的多样性。
- 舍弃 NSP 任务:通过实验证明不使用 NSP 任务对大多数任务都能提升性能。
- 更多训练数据,更大批次,更长的预训练步数。
- 更大的词表:使用 SentencePiece 这种字节级别的 BPE 词表而不是 WordPiece 字符级别的 BPE 词表,几乎不会出现未登录词的情况。
3.3.3 ALBERT
BERT 参数量相对较大,ALBERT(A Lite BERT) 主要目标是减少参数:
- BERT 的词向量维度和隐含层维度相同,词向量上下文无关,而BERT 的 Transformer 层需要并且可以学习充分的上下文信息,因此隐含层向量维度应远大于词向量维度。当增大提高性能时,没有必要跟着变大,因为词向量空间对需要嵌入的信息量可能已经足够。
- 方案:,词向量通过全连接层变换为H维。
- 词向量参数分解(Factorized embedding parameterization)。
- 跨层参数共享(Cross-layer parameter sharing):不同层的Transformer block 共享参数。
- 句子顺序预测(sentence-order prediction, SOP),学习细微的语义差别及语篇连贯性。
3.4 生成式对抗 - ELECTRA
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately) 引入了生成器和判别器的模式,把生成式的 Masked language model(MLM) 预训练任务改成了判别式的 Replaced token detection(RTD) 任务,判断当前 token 是否被语言模型替换过,比较类似 GAN 的思想。

生成器预测输入文本中 mask 位置的 token:


判别器的输入是生成器的输出,判别器预测各个位置的词是否是被替换过的:

此外,还做了些优化:
- 生成器和判别器分别是一个 BERT,缩放了生成器 BERT 参数。
- 词向量参数分解。
- 生成器和判别器参数共享:输入层参数共享,包括词向量矩阵和位置向量矩阵。
在下游任务只使用判别器,不使用生成器。
3.5 长文本处理 - Transformer-XL
Transformer 处理长文本的常见策略是将文本切分为固定长度的块,并独立编码各个块,块与块之间没有信息交互。

为了优化对长文本的建模,Transformer-XL 使用了两个技术:状态复用的块级别循环(Segment-Level Recurrence with State Reuse)和相对位置编码(Relative Positional Encodings)。
3.5.1 状态复用的块级别循环
Transformer-XL 在训练的时候也是以固定长度的片段的形式进行输入的,不同的是 Transformer-XL 的上一个片段的状态会被缓存下来然后在计算当前段的时候再重复使用上个时间片的隐层状态,赋予了 Transformer-XL 建模更长期的依赖的能力。
长度为 L 的连续两个片段 和。的隐层节点的状态表示为,其中 d 是隐层节点的维度。 的隐层节点的状态的计算过程为:

片段递归的另一个好处是带来的推理速度的提升,对比 Transformer 的自回归架构每次只能前进一个时间片,Transfomer-XL 的推理过程通过直接复用上一个片段的表示而不是从头计算,将推理过程提升到以片段为单位进行推理。

3.5.2 相对位置编码
在 Transformer 中,自注意力模型可以表示为:

的完整表达式为:


Transformer 的问题是无论对于第几个片段,它们的位置编码 都是一样的,也就是说 Transformer的位置编码是相对于片段的绝对位置编码(absulate position encoding),与当前内容在原始句子中的相对位置是没有关系的。
Transfomer-XL 在上式的基础上做了若干变化,得到了下面的计算方法:

- 变化1:中,被拆分成立和,也就是说输入序列和位置编码不再共享权值。
- 变化2:中,绝对位置编码替换为了相对位置编码
- 变化3:中引入了两个新的可学习的参数来替换和 Transformer 中的 query 向量 。表明对于所有的 query 位置对应的 query 位置向量是相同的。即无论 query 位置如何,对不同词的注意偏差都保持一致。
- 改进之后,各个部分的含义:
- 基于内容的相关度(): 计算 query 和 key 的内容之间的关联信息
- 内容相关的位置偏置():计算 query 的内容和 key 的位置编码之间的关联信息
- 全局内容偏置():计算 query 的位置编码和 key 的内容之间的关联信息
- 全局位置偏置():计算 query 和 key 的位置编码之间的关联信息
3.6 蒸馏与压缩 - DistillBert
知识蒸馏技术 (Knowledge Distillation, KD):通常由教师模型和学生模型组成,将知识从教师模型传到学生模型,使得学生模型尽量与教师模型相近,在实际应用中,往往要求学生模型比教师模型小并基本保持原模型的效果。
DistillBert 的学生模型:
- 六层的 BERT, 同时去掉了标记类型向量 (Token-type Embedding, 即Segment Embedding)。
- 使用教师模型的前六层进行初始化。
- 只使用掩码语言模型进行训练,没有使用 NSP 任务。
教师模型: BERT-base:
损失函数:
有监督 MLM 损失:利用掩码语言模型训练得到的交叉熵损失:
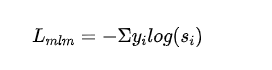
- 表示第个类别的标签,表示学生模型第个类别输出的概率。
- 蒸馏MLM损失:利用教师模型的概率作为指导信号,与学生模型的概率计算交叉熵损失:
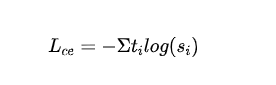
- 表示教师模型第个类别的标签。
- 词向量余弦损失:对齐教师模型和学生模型的隐含层向量的方向,从隐含层维度拉近教师模型和学生模型的距离:
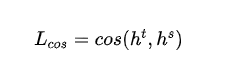
- 和分别表示教师模型和学生模型最后一层的隐含层输出。
- 最终的损失:
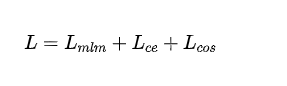
4. 参考资料
https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
https://arxiv.org/pdf/1706.03762.pdf
https://zhuanlan.zhihu.com/p/38130339
https://zhuanlan.zhihu.com/p/184970999
https://zhuanlan.zhihu.com/p/466841781
https://blog.csdn.net/Dream_Poem/article/details/122768058
https://aclanthology.org/N18-1202.pdf
https://zhuanlan.zhihu.com/p/350017443
https://life-extension.github.io/2020/05/27/GPT技术初探/language-models.pdf
https://arxiv.org/pdf/2005.14165.pdf
http://www.4k8k.xyz/article/abc50319/108544357
https://arxiv.org/pdf/1906.08237.pdf
https://zhuanlan.zhihu.com/p/103201307
https://arxiv.org/pdf/1810.04805.pdf
https://zhuanlan.zhihu.com/p/51413773
https://arxiv.org/pdf/1907.11692.pdf
https://zhuanlan.zhihu.com/p/103205929
https://arxiv.org/pdf/1909.11942.pdf
https://arxiv.org/pdf/2003.10555.pdf
https://segmentfault.com/a/1190000041107202
https://arxiv.org/pdf/1910.01108.pdf
https://zhuanlan.zhihu.com/p/271984518




















