Google 在上周发表了一篇博客文章,当中介绍了一个开源的 C++ 和 Python 库 —— TensorStore,开发者可以使用它来存储和操作多维数据,该库旨在通过更好地管理和处理大型数据集来解决科学计算中的关键工程挑战。
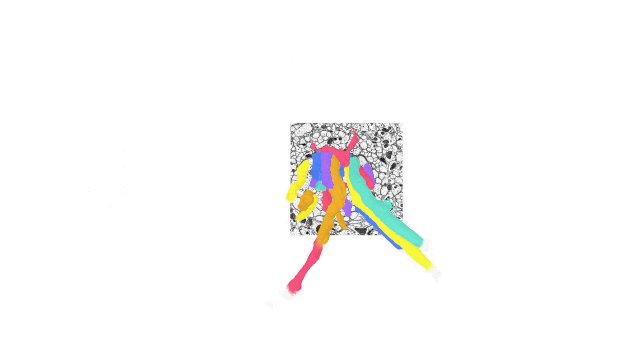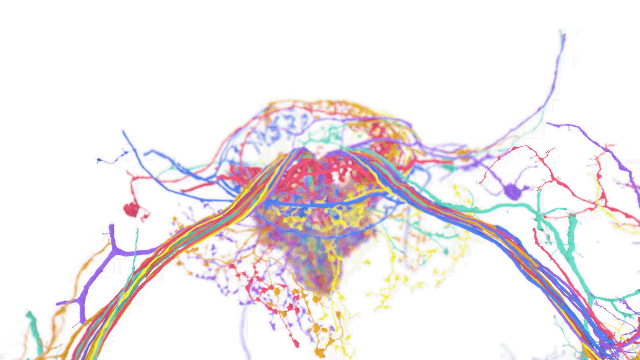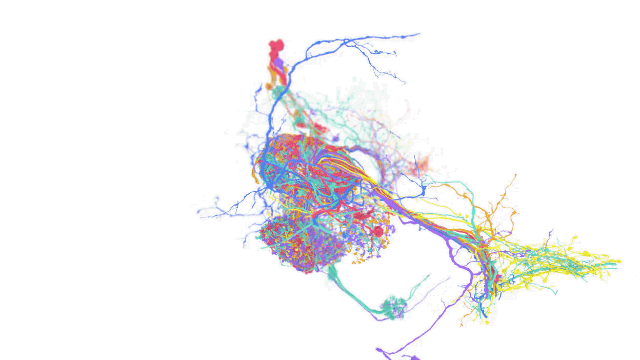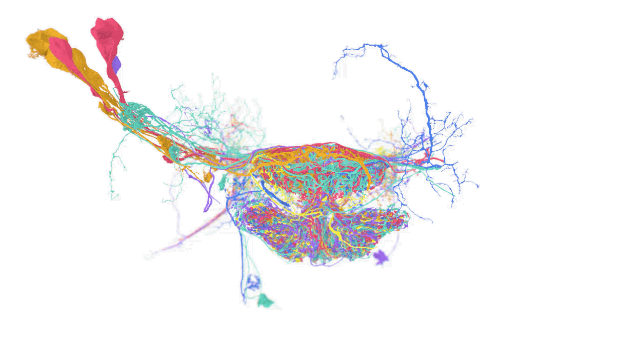
如今计算机科学和机器学习中的各种应用都在操作跨越单一坐标系的多维数据集。在这些应用中,一个单一的数据集可能就需要 PB 级的存储空间,而且处理这种数据集也同样面对挑战 —— 因为用户可能以不同的规模和不可预测的时间间隔接收和写入数据。
TensorStore 提供了一个简单的 Python API 来加载和处理大量的数据数组,任意大型的底层数据集都可以被加载和操作,而且不需要将整个数据集存储在内存中,因为在请求精确分片之前,TensorStore 不会读取实际数据或将其保存在内存中。这可以通过索引和操作语法实现,这与 NumPy 操作所用的语法基本相同。
TensorStore 还支持多种存储系统,如 Google Cloud、本地和网络文件系统等。它提供了一个统一的 API 来读写不同的数组类型(如 zarr 和 N5)。凭借强大的原子性、隔离性、一致性和持久性(ACID)保证,该库还提供了读 / 写回的缓存和事务。
此外,TensorStore 具备的并发性能够确保当许多机器访问同一个数据集时,并行操作的安全性。它与各种底层存储层保持兼容,而不严重影响性能。
研究人员提到,处理和分析大型数值数据集时,需要大量的运算资源,一般情况下,这是由分布在多个设备上的大量 CPU 或加速器核心之间的并行操作来完成的,这些资源通常也分散在众多机器上。TensorStore 的基本目标,便是要能够对单个数据集进行安全并行处理,使这些数据集不会因为并行存取模式,而产生损坏或是不一致,但又同时维持高性能。事实上,在 Google 数据中心内的一项测试中发现,随着 CPU 数量的增加,读写性能几乎呈线性增长。
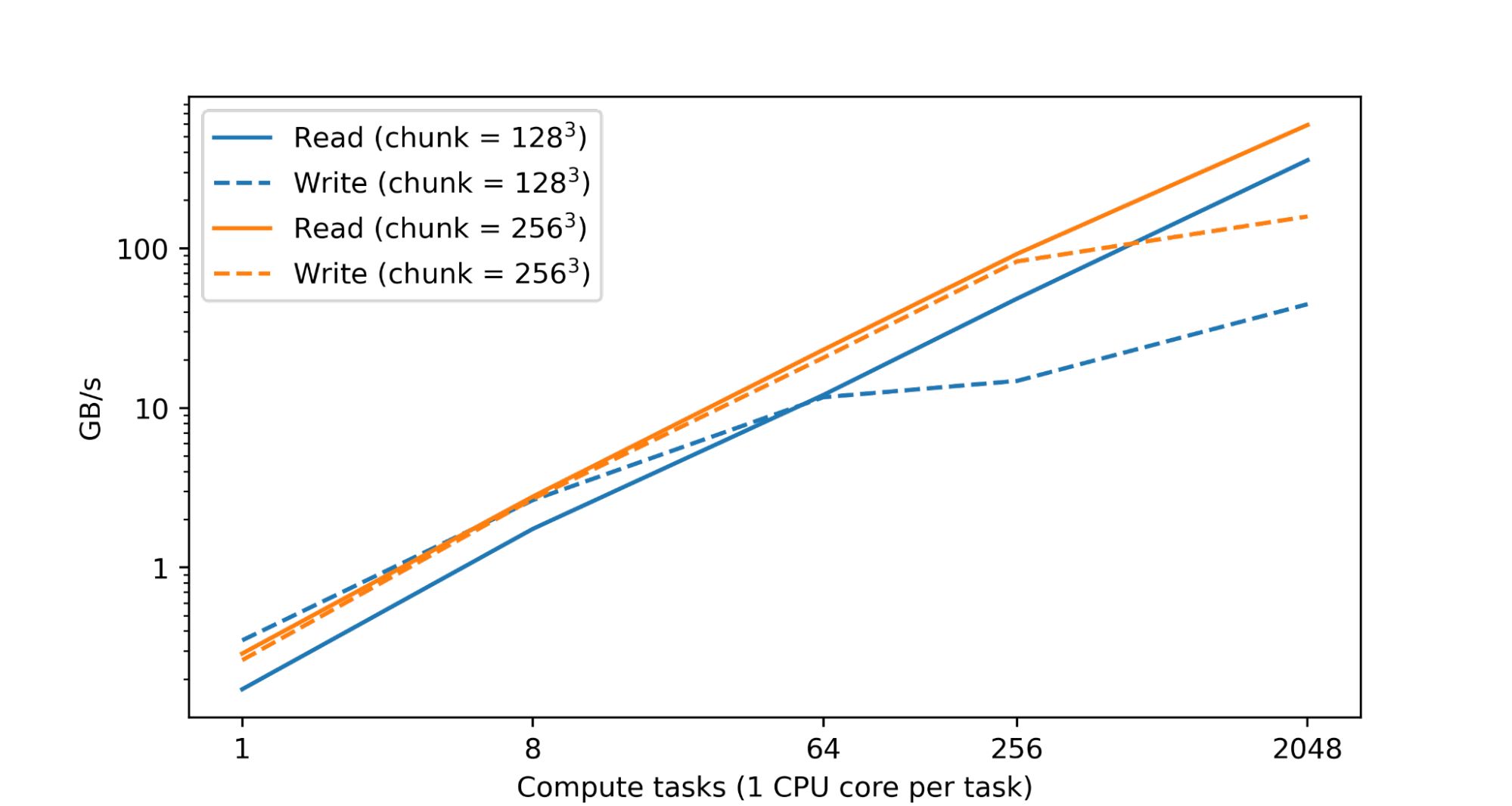
TensorStore 也有一个异步 API,允许程序在进行其他任务时,可以继续在后台进行读或写操作。TensorStore 还与 Apache Beam 和 Dask 等并行计算框架集成,以使 TensorStore 的分布式计算与当前许多数据处理工作流程兼容。
TensorStore 的用例包括语言模型,可在训练过程高效读取和写入模型参数,另外也能用于大脑映射上,储存用于描绘大脑神经的高解析度映射图。
项目 Github 地址: https://github.com/google/tensorstore
本文转自OSCHINA
本文标题:Google 开源 TensorStore,为读写大型多维数据而设计
本文地址:https://www.oschina.net/news/211942/google-tensorstore