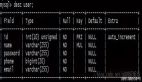
大家都知道,数据库中使用索引,进行检索数据的话,那么就会大幅度的提升你的查询效率,原本可能需要三秒甚至四秒左右的查询SQL,增加索引之后,会可以能让查询速率至少提升百分之30,那么加索引怎么才能如何让自己的查询命中索引呢?又应该怎么去给自己的表结构建立索引呢?这才是阿粉想要讲的事情。
索引失效
我们在日常开发的时候,很多时候都会在创建表完成之后,给这个对应的表建立上一个索引,而这个索引的定义呢,一般也是根据自己的业务需求来的,但是有些虽然根据自己的业务需求弄好了之后,发现有些查询明明自己感觉都运用了索引,但是最终却发现自己的索引失效了。
那么引发索引失效,都有哪些骚操作呢?
实际上就是七个字,模 型 数 空 运 最 快
模:模糊查询的意思。like的模糊查询以%开头,索引失效。比如:
SELECT * FROM user WHERE name LIKE '%极客技术';
型:代表数据类型。类型错误,如字段类型为varchar,where条件用number,索引也会失效。比如:
SELECT * FROM user WHERE height= 10;
height为varchar类型导致索引失效。
数:是函数的意思。对索引的字段使用内部函数,索引也会失效。这种情况下应该建立基于函数的索引。比如:
SELECT * FROM user WHERE DATE(create_time) = '2020-09-03';
create_time字段设置索引,那就无法使用函数,否则索引失效。
空:是Null的意思。索引不存储空值,如果不限制索引列是not null,数据库会认为索引列有可能存在空值,所以不会按照索引进行计算。比如:
SELECT * FROM user WHERE address IS NULL不走索引。
SELECT * FROM user WHERE address IS NOT NULL;走索引。
建议大家这设计字段的时候,如果没有必要的要求必须为NULL,那么最好给个默认值空字符串,这可以解决很多后续的麻烦(切记)。
运:是运算的意思。对索引列进行(+,-,*,/,!, !=, <>)等运算,会导致索引失效。比如:
SELECT * FROM user WHERE age - 1 = 20;
最:是最左原则。在复合索引中索引列的顺序至关重要。如果不是按照索引的最左列开始查找,则无法使用索引。
快:全表扫描更快的意思。如果数据库预计使用全表扫描要比使用索引快,则不使用索引。
如何建立索引呢?
这个时候,如果面试官问你的时候,说,如何建立索引,就是建立索引的规范的时候,你应该怎么回答呢?
其实这就是问你,你在设计表的时候,怎么去设计表里面的索引比较合适呢?阿粉列出几个:
1.经常与其他表进行连接的表,在连接字段上应该建立索引
也就是在关联条件上面,建立索引,比如a.id = b.aid
a表的id,是主键,而这时候,我们就需要把b表的对应a表的id建立一个索引,这样在使用关联查询的时候,能够命中索引。
2.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引
3.索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引
4.频繁进行数据操作的表,不要建立太多的索引
5.在经常需要排序的列上创建索引
6.为经常出现在关键字order by、group by、distinct后面的字段,建立索引。
哪些字段不适合去建立索引
这些字段是索引应该建立的在什么字段上,那么什么样的表字段,不适合去建索引呢?
1.对于那些在查询中很少使用或者参考的列不应该创建索引
2.不要在有大量相同取值的字段上,建立索引
3.当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
所以在我们创建表的时候,适当的索引能够加快我们的查询速度,不适当的索引,反而对我们的表,有害而无益。你学会了么?