













对比学习和文本生成的结合并不是一个新话题。但是,之前的大多方法都局限于某些特定的任务场景。例如,在一个对话的场景中,可能需要利用对比学习,去区分说话者,或者说话的主题,达到更好的表示学习的效果。在摘要中,也有一些工作通过构造具有事实性错误的负样本来使用对比学习,增强生成的摘要和原文的一致性。然而,对于比较通用的任务(以使用 Transformer的编码器和解码器为生成模型为例),在用于机器翻译、摘要、数据到文本生成的各种任务下,如何去引用对比学习才最有效?为什么要去用对比学习?关于这方面的研究比较少,本文将就此进行讨论。
今天的介绍会围绕下面四点展开:
- 动机
- 方法
- 实验
- 讨论
01 动机
先来讲一下为什么要使用对比学习。
1. 为什么在文本生成上应用对比学习
首先,对比学习是一种很好的表示学习的方式,尤其是在CV的场景下,对比学习更是非常火,在文本生成任务场景下,如果可以去构造出对于这个任务有意义的、有价值的样本,可以帮助模型通过不同样本之间的比较,学到更好的意义和表示。
其次,最近有研究表明,对比学习是有助于缓解曝光偏差问题的一个新思路。所谓曝光偏差,就是指目前大多数的生成框架(大多基于最大似然估计进行训练的)存在着测试和训练的不一致性,这个不一致性将会损害模型的泛化性能。模型在训练阶段解码器只曝光给了正确的输入,而在测试阶段模型不得不基于自己生成的字符来预测,由此形成了测试和训练的偏差。之前已经有很多工作来解决这个问题,比较有名的就是scheduled-sampling:既然曝光偏差是由于训练和测试的不一致导致的,那就让模型在训练的时候也以一定概率和测试采取同样的机制。也就是说,以一定概率利用上一步预测的词语指导下一步的生成。
除此之外,还有一些比较有名的方法,如基于强化学习,生成对抗网络等。除了token-level监督和最大似然的训练目标以外,还让模型去显示的优化一个难以微分的目标。但是这两种技术,在实现中存在着一定的难度,如果不是一个富有经验的研究者,可能训练出来的基于强化学习或者生成对抗网络的模型还不如一个纯粹的MLE模型训练的效果好。
2. 应用对比学习可以缓解自回归模型的曝光偏差问题

对比学习是如何解决这个问题的?
首先回顾下对比学习的目的。对比学习就是在表示上把正例拉近,把负例拉远。在生成的场景下,对正负样本的一个非常直观的定义就是,把比人写的质量高的样本当做正例。以翻译任务为例,人翻译的结果就是正例,然后再另外去找一些包含错误的翻译结果就是负例。
如何缓解曝光偏差?就是将错误的样本和正确的样本在训练阶段同时曝光给解码器,利用对比学习损失函数,让模型学习到正确标签的表示和错误标签的表示。相比强化学习和GAN,对比学习的一个好处就是训练过程没有不稳定的问题。
3. 一个简单的方法

看一个如何应用对比学习的例子。最简单的方式就是采用CV上SimCLR的方式,即正样本是给定的人写的目标语句(也称为ground truth),将一个batch中其他的样本当做是负样本。锚点是生成中的source sequence输入。
如右图所示,是一个德英翻译的例子。有一个德语输入,目标是要把它翻译成合适的英语输出。图中的绿色框就是人类所写的标准的翻译,红色框是在训练阶段和它同一个batch里进行一个随机采样出来的结果。绿色的就是正样本,其他的就是负样本。对比学习损失函数可以采用比较常见的NCE loss:一个正样本是一个分子,整个样本集是一个分母。最终的训练目标就是把原始的token-level的NLL损失加上新的对比学习损失。解码阶段采用普通的beam-search算法即可。
4. 其他构造正负样本的方法

这个方法存在一个明显的问题。在对比学习中,最重要的就是正负样本是否对任务有意义,可以看出来,这个方法的负样本的质量实在堪忧,这就导致正负样本非常容易区分,使模型学不到更好的表示。右图是对区分正负样本难度的分析。Batch size越大,从中找出正例的概率越低。红色这条线使用的是T5模型,表示学习效果更好,比Scratch的方法区分正负样本的准确率高很多,甚至不需要做对比学习的微调就可以找出正负样本。这意味着对比学习是没有挑战的。所以说直接从batch中选择正负样本的方法是不充分的。在实验中也发现,这样训练损失函数下降的是很快的,很难捕捉到对这个任务比较好的特征。
现在也有相关研究者做出了一些改进。
- SSMBA:在离散空间添加扰动,如随机mask一些词,用masked language model 将那些词预测回去生成新的正样本。
- Dropout:使用dropout机制类似于SimCSE,将ground truth输入进带有dropout机制的decoder两次,所得到的不同表示为一对正样本。
- CLAPS: 在embedding空间对ground truth加扰动,通过和原来的序列语义变化的大小作为划分正负样本的依据。
5. 目前基于对比学习的文本生成方法仍然存在瓶颈

基于对比学习的文本生成方法,仍然存在一系列的瓶颈,还没有发挥出其真正的优势。主要有以下三点:
- 正负例构建: 尽管之前的方法已经做出了一定的改进,但是对目标序列进行扰动并不能反映模型当前可能会出现的错误。
- 对比学习损失函数: 对比学习损失函数的选择也存在问题。InfoNCELoss 只区分正负样本,但会忽略负样本之间的差异性。
- 解码目标: 仅仅是简单的使用普通的beam search算法意味着这里存在着训练目标和解码目标的不一致。
02 如何解决问题
1. 我们的改进

我们提出了一种新的对比学习的框架——CoNT,只做了三件事,就可以使之前的对比学习框架性能取得非常显著的提升。
上图是我们的模型概述。左边的部分就是经典的生成框架,把原语句输入给编码器,目标语句输入给解码器进行训练。Zx 和 Zy 分别是编码器和解码器输出的向量表示。
- 第一个改进是使用模型预测的样例,作为对比学习的样例
如图中的这个句子,首先让模型自己进行推理,会生成一个句子,其概率约为0.48。同时,由于beam search算法,可以解码出多个输出,会产生另一个句子,其概率约为0.53。一般来说,只要返回这两个输出的句子就已经足够了,但是在对比学习的场景下,还需要得到他们的表示。
- 第二个改进是使用三元组的对比损失函数
在这里,不同于NCE损失,只考虑一个正例样本,其他的都是负样本,而我们的做法是做一个相对的损失函数。比如,当前有一个结果是模型推理生成的,这个结果和人翻译的结果相比就是负例,但相对于同batch的句子来说,这个结果就是正例。
- 为对比学习的目标所设计的解码目标
通过损失函数就可以看出,如果模型推理的结果和gold reference的结果比较接近,那么它和原始输入的锚点是越相似的。从图中可以看出,如果只考虑最大似然分数,那么概率为0.53的句子将作为最后的结果,但如果多做一个相似度打分,那么概率为0.48的句子会是最后的输出,以人为判断来看,这个结果明显是更准确的。
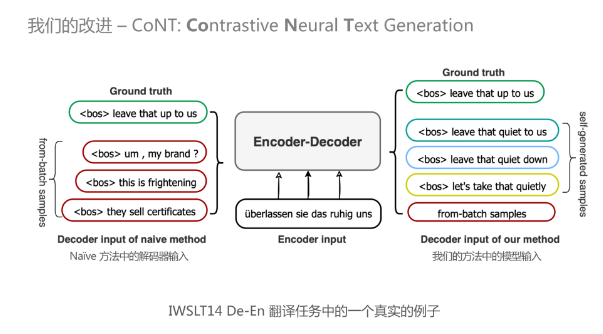
这是一个直观的例子,来自于IWSLT14德英翻译的一个句子。主要是为了向大家展示来自于同一batch中句子的质量和自生成的样本的质量的对比。

这是对刚才模型的数学表示。
首先,y+ 和 y- 是正负样本,都是来自于模型的分布。接下来,是三元组的对比损失函数。把所有的pair都加起来,对于每一pair,它的损失函数是MarginRankingLoss。其中,𝒫是包含𝒌个对比学习样本的pair集合,大小为k(k-1)/2。对于每个(yi,yj) + 和 - 是由他们各自的 bleu score 决定的。分数高的在这个pair中就为正例,另外一个就为负例。最后,解码目标是由一个序列相似度的损失加上一个语言模型的损失。在解码的时候,为了统一性,引入平衡因子进行加权和。平衡因子一般设为0.5即可。

CoNT模型并不是一个完全割裂的设计,而是相互帮助,相互运作的框架。
首先,三元组对比损失函数可以建模样本差异性,序列相似度可以在解码时做全局打分,自生成的正负样本可以反映模型当前的错误,都可以提升模型的性能。模型性能提高了以后,就会意味着正负样本会更加的challenging,随着模型性能越来越好,正负样本也越来越来越难以区分,直到最后收敛。对于解码的目标,在实验中也证明了,三元组的对比损失函数,以及自生成的正负样本,对于序列相似度的计算都是有帮助的。
03 实验
1. 机器翻译

首先看一下机器翻译的实验结果,使用的数据集是IWSLT14德英翻译、WMT16俄英翻译和WMT14英德翻译数据集。第一个block是用纯粹的MLE损失训练的结果,第二个block是用NCE损失训练的结果,第三个block就用构造的模型训练的结果。Block2主要比较了不同的那个正负样本构建方法所带来差异性。Block2和block3反映的是用不同的损失建模对于学习所带来的收益,可以看到我们的正负样本的构建得到的效果显著提高。橙色的框表示的是单看训练所带来的提升。
2. 文本摘要

这是摘要生成的实验,使用的数据集是XSum和Multi-News。第一个block仍然是比较了不同的对比学习方法,可以看出CoNT的方法比MLE的方法高了三个多点,比之前最好的方法(CLAPS)也高了两个点。同样,在PEGASUS上面做了实验,可以看到,也是取得了目前最好的结果。
3. 代码注释

这两个实验是在代码注释生成以及结构化的文本生成的上面做的实验。
左面这个block表示对于python和java这两个数据集的结果。在不引入外部数据的前提下,最好结果是CodeT5+Dual-Gen,可以看到在加上CoNT之后的方法也是取得了一个新的SOTA。当然,在引入外部数据的情况下,可以取得更好结果。右面是比较经典的数据到文本生成的基准,叫WiKiBio,R2D2是之前的SOTA结果,在使用CoNT后,取得了最新的SOTA。
4. 数据到文本的生成—TOTTO

这是数据到文本生成的另一个比较有名的数据集TOTTO,相比较WiKiBio,它的数据更加干净。上面给的就是一个例子。在测试集上,利用CoNT方法,使用T5-base模型是可以取得和T5-3B模型相近的结果。也就是说,使用CoNT方法,可以在保证模型的性能的情况下,用非常节能的方式和3B模型取得相近的结果,甚至在BLEURT和PARENT两个指标上还可以取得小幅度的领先。
5. 常识生成—CommonGen

最后一个任务常识生成,即给定几个关键词,生成一句逻辑连贯且通顺的句子。从表中可以看出,使用CoNT方法,比较之前的base的结果,取得了非常大的领先。和large相比也是取得了相近的结果,甚至在某些指标上还要高。
04 讨论
1. 可视化表示

这是模型学习的表示的可视化结果。
蓝色的点代表同一个batch中的样例,橘色代表是从模型分布中采样出来的,绿色表示ground truth,颜色越深代表和ground truth越相似。图a是MLE模型的结果。围绕绿点旁边的,大多数都是模型自己推理出来的东西,但是它没有一个很明显的角色边界。当用Naïve CL的框架后,能够学习到很明显的决策边界,但是对于比较细的粒度,如这个绿点旁边围绕的其实并不是一些高质量结果,还是比较错乱的情况。但对于CoNT来说,也有一个明显的角色决策边界,而且在绿色的旁边围绕的大多数都是一些深色的橙点,即模型推理出的一些质量比较好的结果。
2. 序列相似度的权重

这里探究在解码时引入相似度计算的影响。这里主要做两个study,一个是使用不同的损失函数,另外一个是采用不同的正负样例构建方法。当α等于零的时候,就意味着完全使用似然函数。α等于1的时候,就意味着完全依赖相似度分数。可以看到,对于Pair-wise模型,在0-0.5时,分数是不断上升的。但是当完全忽略掉似然函数时,性能也会有下降的趋势。右边这个图主要反映了使用不同正负样本构造方式对序列相似度打分的影响,可以看到,使用CoNT的方式对reanking的目标有比较大的帮助。
3. 如何在你的代码中使用对比学习

这里讲一些比较工程化的东西,即假设现有一个基于MLE训练的模型,如何引入CoNT。由于我们的方法是不需要改变模型结构的,因此只需要把模型的checkpoint加载进来,然后调用你模型的推理阶段的代码,利用pair-wise计算损失函数,直到模型收敛。在推理部分,在beam search时返回每个beam对应的隐层的pooling操作后的向量表示,最后在预测结果的选择时,利用平衡因子结合cosine距离和似然函数概率,选出最好的结果。
4. CoNT的优缺点
在实际推理中,引入Contrastive learning几乎不会带来明显的浮点数运算操作(FLOPs),因此不会造成更多能量的消耗(不费电),并且和MLE框架下训练的模型推理时长几乎是一模一样的(不影响速度)。因此在实际部署中基于Contrastive learning训练的模型可以容易地替换现有的使用MLE 训练的模型,但是CoNT 的一个明显的缺点是:牺牲了训练的速度。CoNT的训练速度慢主要有三个方面:

第一点,为了获取足够有效或者说足够有意义的样本,需要先对模型进行一次warmup,即先使用NLL损失微调模型,直到模型微调完成,才可以足够合格的去产生所需要的正负样本。

第二点,在训练时候,要引入解码,使用beam search。在自回归场景下,这是不可并行的,也会增加模型的一个训练时长。

第三点,在决定正负样本时,需要计算和ground truth的相似度。这个过程其实是非常慢的,尤其是使用cpu来算,就会更慢,最后我们选择利用矩阵乘法来近似的计算相似度,极大地降低了时间开销。
5. 一些trade-off的方法

这里提供两个trade-off思路:
- 减小样本中来自模型分布的样本数量,增大来自batch中的样本数量。
- 在验证集中对比学习的下降曲线在前1w步比较陡,可以考虑early stop。
6. 利用序列的相似度进行协助解码

目前,对于对比学习目标的使用仍然不是最优的。目前的生成过程是在beam search完成后加入的,相当于是reranking的作用。当然,这方面也是考虑到代码的实现的难易度,包括和训练一致性的问题。当然,使用这套方法非常有潜力去做一套协助解码的工作。在beam search过程中,似然函数的打分可能是不可靠的。如图中的例子,可以发现,在beam search过程中,由于贪心策略的存在,不可能遍历所有的结果。一个解决方案是,能否考虑每多少步,引入一个序列相似度的计算。
05 问答环节
Q1:序列相似度是如何计算的?
A1:锚点的选择是编码器的输出,该输出是一个sequence * h的矩阵,沿着sequence纬度进行pooling就可以得到一个维度为h的向量,这就是一个编码器输出的源语句的表示。在beam search过程中我们可以得到那些不同的hypothesis的表示也是sequence * h的矩阵,这些序列长度是不同的,我们也沿着长度的维度进行pooling获得编码器输出的hypothesis向量,然后通过这些输出和源输入的相似度就可以计算出序列相似度的得分。
Q2:CoNT有运用到对话任务上吗?
A2:我们在实验中没有做对话任务,因为考虑到单轮的对话可能研究价值没有那么大,但是多轮对话和我们整个框架在训练和解码过程中都稍微有一点不一致,所以说没有去做对话的工作。所以可能也不能给你一个非常绝对的一个回答,欢迎后面进行实验和讨论。
Q3:请问Warmup是训练到收敛还是训练到一定效果就可以?
A3:我们在进行实验时都是训练到收敛的,当然,训练到一定效果其实也是可以的。但是,由于CoNT在训练的时候是需要进行推理的也就导致整个训练速度会比只做MLE的速度慢很多,所以尽量是劝大家先把warmup训收敛,因为如果先没有收敛的话,虽然在后面的训练过程中NLL依然会接着训练,但是可能会为后续的带对比损失的训练造成更多的训练时常开销,当然,最终效果其实应该是不影响的。
Q4:可以把blue分数直接分类成soft label一样的东西,放到对比学习的损失函数里面吗?
A4:可以的。可以通过blue分数控制两个样本之间的margin,比如说一个blue分数比较高,一个blue分数比较低,那他们之间的margin就比较大,如果这两个blue分数差不多,那他们的margin就比较小。当然,我不建议直接去对blue分数进行优化,因为在生成上的RL确实在训练中比较不稳定。
Q5:有哪些数据集是验证生成语言的常识准确性?
A5:我只做了刚刚我们做的常识生成的这个数据集CommonGen,也有一些其他数据集如CommonSense QA。把这个准确性理解成事实一致性的话,在我们的这个任务中其中评测准确性的指标是CIDER和SPICE。如果要自动评价一个常识的准确性,可能是需要人工评价,或者是用模型评价。用模型评价的话目前来说工作还不是很多,在摘要上有一个比较有名的FACTCC,翻译上好像没看到。
DataFunSummit













