译者 | 布加迪
审校 | 孙淑娟
如果您熟悉Kafka和RocketMQ等消息系统,可能知道服务通常与其架构中的存储密切相关。与它们不同的是,Apache Pulsar在设计时采用了将存储与计算分开的两层架构,这实际上在其无状态代理上进行。Pulsar依赖Apache BookKeeper服务器(又叫bookies)进行持久存储。本文侧重介绍BookKeeper基础知识,表明它如何为所处理的数据实现高可用性。
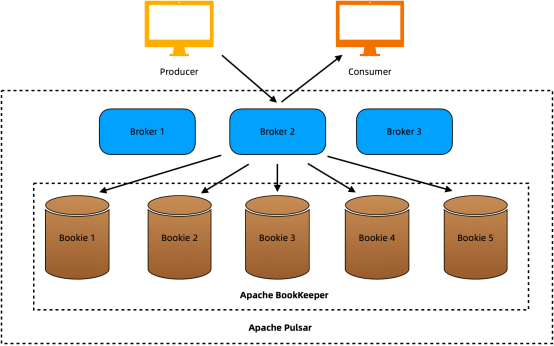
图1
Apache BookKeeper简介
BookKeeper最初在雅虎开发,代表了一种可靠的高性能存储系统。它提供分布式可扩展的存储服务,具有低延迟和强容错性的优点。这些充分说明了为什么它能够充当Pulsar的存储层。BookKeeper将数据存储在分类帐(ledger)中,分类帐只能追加且不可变。借助特殊的复制协议,BookKeeper以并发方式在多个节点上安全地存储日志条目,因而具有高可用性。
顾名思义,BookKeeper和分类帐在云原生环境中大有用途。不妨设想一下簿记员使用分类帐记录所有相关账户信息,以跟踪企业的财务状况。
Apache BookKeeper中的关键概念
为了更好地了解BookKeeper如何存储数据,不妨先看一下几个基本概念。
- Bookie
Bookie是BookKeeper中的存储服务器或节点,彼此同等。BookKeeper强大的动态扩展功能(尤其是在容器化环境中)归功于无主节点(leaderless)设计。
- Ensemble
用于存储分类帐条目的可用bookie的集合,即写入条目的节点。当一个bookie失效时,处理写入它的客户端将换成一个新的bookie,这名为“ensemble change”。在Pulsar的计算存储分离架构中,客户端应用程序不需要关心存储层中实际发生的事情。
- 分类帐
分类帐是BookKeeper中的基本存储单元,在Pulsar中又叫Segment。BookKeeper客户端负责创建和删除分类帐,并从分类帐中读取条目。满足某些条件时(比如条目数或寿命达到预设阈值),分类帐将被关闭,之后再无法向其写入数据,只允许读取。任何客户端都可以创建分类帐。理想情况下,创建分类帐的所有者客户端应该是关闭它的客户端。一旦关闭,分类帐不可变。分类帐是最小的删除单位,这意味着您只能删除整个分类帐,而不能删除分类帐中的单个条目。
除了用于存储普通消息的分类帐外,BookKeeper还有一种特殊的分类帐,即游标分类帐。游标为Pulsar中的消息消费和确认提供跟踪机制。每个订阅都有一个与之关联的游标,游标存储消息消费和确认的位置信息。消费者可能根据订阅类型来共享同样的游标。我们在这里不详细介绍这个话题。我们只需知道Pulsar在BookKeeper中为每个订阅维护一个分类帐。在消费者处理消息(向代理发送确认)、代理收到确认之后,代理随后相应地更新游标分类帐。更具体地说,Pulsar定期汇总绑定到同一订阅的所有消费者的所有确认信息作为条目,并将其写入bookie。这个过程与编写普通消息基本相同。
- 片段
片段在bookie的分类帐中存储连续序列的条目。分类帐可能含有一个或多个片段。作为BookKeeper中最小的分布单元,单个分类帐的片段可以分散在不同的bookie中。这意味着严格来讲,存储在单个bookie的数据是分类帐的片段。对于单个片段而言,如果写入 bookie失败,会选择新的bookie进行写入(即上面提到的“ensemble change”)。结果,将在bookie上创建新片段。请注意,这两个片段属于同一个分类帐,但属于不同的ensemble。
- 条目
条目含有写入分类帐的实际数据。每个分类帐可能含有不同数量的条目。每个条目都有条目ID作为其在分类帐中的唯一标识符。
- 消息
消息是存储在条目中的特定信息。消息可以分为两种:单条消息和批量消息。
批量消息本质上是一系列单条消息。在客户端启用消息批处理后,消息将在从生产者发送到代理之前作为一个整体进行分组。Brokers然后调用BookKeeper客户端,将批量消息写入bookie。当消费者从代理读取消息时,代理将批量消息分发给它们。请注意,批量消息在客户端合并和拆分。您可以使用batchingMaxPublishDelay(批量处理待发送消息的时间段)和batchingMaxMessages(批量消息中的最大消息数)等参数,为生产者定制批量消息配置。
注意:每个条目可能包含一条或多条消息。如果禁用消息批量处理,一个条目仅存储一条消息。
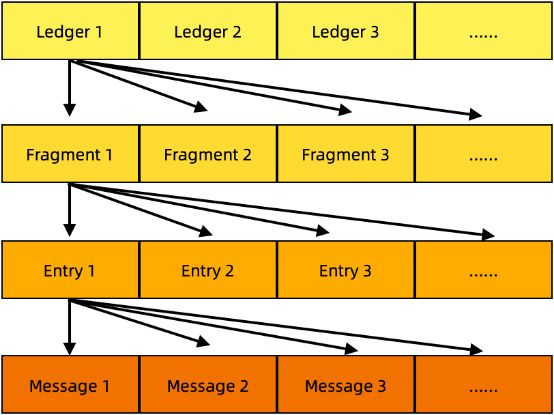
图2
视用例而定,您可以选择启用或禁用消息批量处理。与大多数分布式消息系统不同,Pulsar支持消息队列和流传输。在消息队列场景中,高吞吐量通常不是必须的,因此很少在客户端启用消息批量处理。相比之下,在流传输情形下,消息的生成速度要快得多,这需要批量处理,以便生产者可以将消息作为更大的包来发送。
数据高可用性
为了保证数据的高可用性,BookKeeper采用了一种仲裁机制向bookie并行写入数据。具体来说,我们可以为要创建的新分类帐定义以下三个关键整数:
- Ensemble Size(E):写入存储在分类帐中的消息的可用bookie的数量。
- Write Quorum(WQ):要写入的消息的副本,或同时保存条目(或其所属片段)的bookie的数量。WQ可以等于或小于E,但不能小于1或AQ。
- Ack Quorum(AQ):在写入成功之前,代理需要接收的确认数量。如果达到这个值,代理将向客户端发回确认信息。否则,写入失败。
这三个参数可以分别在代理、命名空间和主题级别进行配置。比如在代理级别,编辑Pulsar包的conf目录中的broker.conf文件,并设置所需的值:
属性文件 # Number of bookies to use when creating a ledger managedLedgerDefaultEnsembleSize=2 # Number of copies to store for each message managedLedgerDefaultWriteQuorum=2 # Number of guaranteed copies (acks to wait before a write is complete) managedLedgerDefaultAckQuorum=2 |
注意:我们可以根据对一致性的需求来配置以上参数。比如说,WQ=AQ表示最高级别的一致性。在这种情况下,消息只有在收到所有副本的确认后才能成功持久化。当AQ比较小(比如AQ = 1)时,延迟会较低,但是数据丢失风险较大。一般来说,最好设置AQ ≥ (WQ + 1)/2。
比如在下图中,我们设置E = 5、WQ = 3和AQ = 2。这意味着:
- 5个bookie可用于将数据存储在分类帐中。
- 一个条目的3个副本存储在3个不同的bookie上。
- 收到来自2个bookie的确认时,表示条目写入成功。
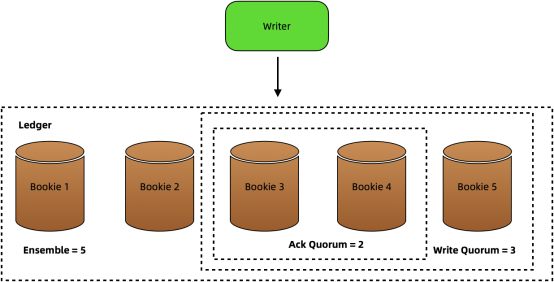
图3
数据使用循环分布写入bookie。这么设计是由于,它可以充分利用池中所有bookie的处理能力。如下所示,Entry 1写入Bookie 1、Bookie 2和Bookie 3,Entry 2写入Bookie 2、Bookie 3和Bookie 4,以此类推。
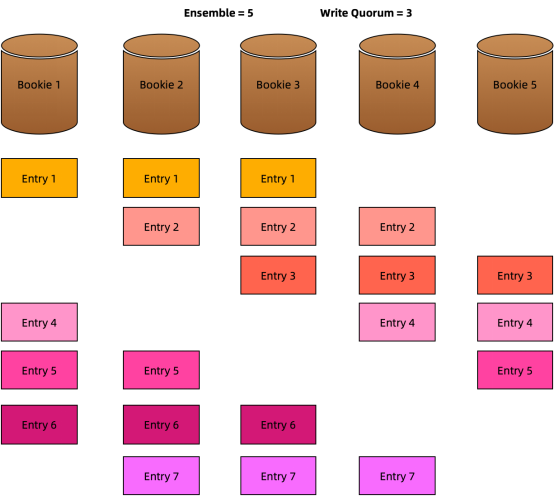
图4
循环方法提供了一种简单的方法来快速找出通过条目ID来存储特定条目副本的bookie。比如说,我们知道条目2在Bookie 2、Bookie 3和Bookie 4上复制。2 mod 5等于 2,这意味着对于特定的条目X而言,如果X mod 5等于2,条目X就存储在Bookie 2上、Bookie 3和Bookie 4上,比如条目 7 (X=7)。
使用Apache BookKeeper
当您安装Pulsar集群时,BookKeeper将一同部署。如果您想运行BookKeeper,不需要单独下载其代码。相反,下载Pulsar并在bin目录中运行./pulsar-daemon start bookie命令。如果您使用Pulsar社区提供的Helm chart将其安装在Kubernetes集群上,bookie Pods则部署在StatefulSet 中。
结语
本文介绍了BookKeeper的基础知识,分析了如何将数据写入bookie以实现高可用性。我们可以将BookKeeper简单地视为一个数据库,因为它不包含任何业务逻辑。该开源工具具有出色的可扩展性、强大的容错性和低延迟,具备成为合格的云原生存储系统所需的特性,为Pulsar的独特架构提供了坚实的支持。
原文标题:Apache BookKeeper: What Makes A Qualified Storage System for Apache Pulsar,作者:Sherlock Xu