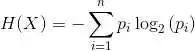在本文中,我们将详细介绍决策树和随机森林模型。此外,我们将展示决策树和随机森林的哪些超参数对它们的性能有重要影响,从而使我们能够在欠拟合和过拟合之间找到最佳方案。在了解了决策树和随机森林背后的理论之后。,我们将使用Scikit-Learn实现它们。
1. 决策树
决策树是预测建模机器学习的一种重要算法。经典的决策树算法已经存在了几十年,而像随机森林这样的现代变体是最强大的可用技术之一。
通常,这种算法被称为“决策树”,但在R等一些平台上,它们被称为CART。CART算法为bagged决策树、随机森林和boosting决策树等重要算法提供了基础。
与线性模型不同,决策树是非参数模型:它们不受数学决策函数的控制,也没有要优化的权重或截距。事实上,决策树将通过考虑特征来划分空间。
CART模型表示
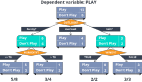
CART模型的表示是二叉树。这是来自算法和数据结构的二叉树。每个根节点表示一个输入变量(x)和该变量上的一个拆分点(假设变量是数值型的)。
树的叶节点包含一个输出变量(y),用于进行预测。给定一个新的输入,通过从树的根节点开始计算特定的输入来遍历树。
决策树的一些优点是:
- 易于理解和解释。树可以可视化。
- 需要很少的数据准备。
- 能够处理数字和分类数据。
- 可以使用统计测试来验证模型。
- 即使生成数据的真实模型在某种程度上违反了它的假设,也表现良好。
决策树的缺点包括:
- 过度拟合。诸如剪枝、设置叶节点所需的最小样本数或设置树的最大深度等机制是避免此问题所必需的。
- 决策树可能不稳定。可以在集成中使用决策树。
- 不能保证返回全局最优决策树。可以在一个集成学习器中训练多棵树
- 如果某些类别占主导地位,决策树学习器会创建有偏树。建议:在拟合之前平衡数据集
2. 随机森林
随机森林是最流行和最强大的机器学习算法之一。它是一种集成机器学习算法,称为Bootstrap Aggregation或bagging。
为了提高决策树的性能,我们可以使用许多具有随机特征样本的树。
3.python中的决策树和随机森林实现
我们将使用决策树和随机森林来预测您有价值的员工的流失。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_style("whitegrid")
plt.style.use("fivethirtyeight")
df = pd.read_csv("WA_Fn-UseC_-HR-Employee-Attrition.csv")
4. 数据处理
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
df.drop(['EmployeeCount', 'EmployeeNumber', 'Over18', 'StandardHours'], axis="columns", inplace=True)
categorical_col = []
for column in df.columns:
if df[column].dtype == object and len(df[column].unique()) <= 50:
categorical_col.append(column)
df['Attrition'] = df.Attrition.astype("category").cat.codes
categorical_col.remove('Attrition')
label = LabelEncoder()
for column in categorical_col:
df[column] = label.fit_transform(df[column])
X = df.drop('Attrition', axis=1)
y = df.Attrition
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
5. 应用树和随机森林算法
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
def print_score(clf, X_train, y_train, X_test, y_test, train=True):
if train:
pred = clf.predict(X_train)
print("Train Result:\n================================================")
print(f"Accuracy Score: {accuracy_score(y_train, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: \n {confusion_matrix(y_train, pred)}\n")
elif train==False:
pred = clf.predict(X_test)
print("Test Result:\n================================================")
print(f"Accuracy Score: {accuracy_score(y_test, pred) * 100:.2f}%")
print("_______________________________________________")
print(f"Confusion Matrix: \n {confusion_matrix(y_test, pred)}\n")
5.1 决策树分类器
决策树参数:
- criterion: 衡量拆分质量。支持的标准是基尼杂质的“基尼”和信息增益的“熵”。
- splitter:用于在每个节点处选择拆分的策略。支持的策略是“best”选择最佳拆分和“random”选择随机拆分。
- max_depth:树的最大深度。如果为None,则展开节点,直到所有叶节点,或者直到所有叶包含的样本小于min_samples_split。
- min_samples_split:拆分内部节点所需的最小样本数。
- min_samples_leaf:叶节点上所需的最小样本数。
- min_weight_fraction_leaf:叶节点上所需的总权重的最小加权分数。当没有提供sample_weight时,样本具有相等的权值。
- max_features:寻找最佳拆分时要考虑的特征数量。
- max_leaf_nodesmax_leaf_nodes:以最佳优先的方式使用max_leaf_nodes形成树。最佳节点定义为杂质的相对减少。如果为None,则有无限数量的叶节点。
- min_impurity_decrease:如果该拆分导致杂质减少大于或等于该值,则该节点将被拆分。
- min_impurity_split: 提前停止的阈值。如果一个节点的杂质高于阈值,则该节点将拆分,否则,它是一个叶子。
from sklearn.tree import DecisionTreeClassifier
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
5.2决策树分类器超参数调优
超参数max_depth控制决策树的总体复杂性。这个超参数允许在欠拟合和过拟合决策树之间进行权衡。让我们为分类和回归构建一棵浅树,然后再构建一棵更深的树,以了解参数的影响。
超参数min_samples_leaf、min_samples_split、max_leaf_nodes或min_implitity_reduce允许在叶级或节点级应用约束。超参数min_samples_leaf是叶子允许有最少样本数,否则将不会搜索进一步的拆分。这些超参数可以作为max_depth超参数的补充方案。
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
params = {
"criterion":("gini", "entropy"),
"splitter":("best", "random"),
"max_depth":(list(range(1, 20))),
"min_samples_split":[2, 3, 4],
"min_samples_leaf":list(range(1, 20)),
}
tree_clf = DecisionTreeClassifier(random_state=42)
tree_cv = GridSearchCV(tree_clf, params, scoring="accuracy", n_jobs=-1, verbose=1, cv=3)
tree_cv.fit(X_train, y_train)
best_params = tree_cv.best_params_
print(f"Best paramters: {best_params})")
tree_clf = DecisionTreeClassifier(**best_params)
tree_clf.fit(X_train, y_train)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=True)
print_score(tree_clf, X_train, y_train, X_test, y_test, train=False)
5.3树的可视化
from IPython.display import Image
from six import StringIO
from sklearn.tree import export_graphviz
import pydot
features = list(df.columns)
features.remove("Attrition")
dot_data = StringIO()
export_graphviz(tree_clf, out_file=dot_data, feature_names=features, filled=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
Image(graph[0].create_png())

5.4随机森林
随机森林是一种元估计器,它将多个决策树分类器对数据集的不同子样本进行拟合,并使用均值来提高预测准确度和控制过拟合。
随机森林算法参数:
- n_estimators: 树的数量。
- criterion: 衡量拆分质量的函数。支持的标准是gini和信息增益的“熵”。
- max_depth:树的最大深度。如果为None,则展开节点,直到所有叶子都是纯的,或者直到所有叶子包含的样本少于min_samples_split。
- min_samples_split:拆分内部节点所需的最小样本数。
- min_samples_leaf:叶节点所需的最小样本数。min_samples_leaf只有在左右分支中的每个分支中至少留下训练样本时,才会考虑任何深度的分割点。这可能具有平滑模型的效果,尤其是在回归中。
- min_weight_fraction_leaf:需要在叶节点处的总权重(所有输入样本的)的最小加权分数。当未提供 sample_weight 时,样本具有相同的权重。
- max_features:寻找最佳分割时要考虑的特征数量。
- max_leaf_nodesmax_leaf_nodes:以最佳优先方式种植一棵树。最佳节点定义为杂质的相对减少。如果 None 则无限数量的叶节点。
- min_impurity_decrease:如果该分裂导致杂质减少大于或等于该值,则该节点将被分裂。
- min_impurity_split: 树提前停止的阈值。如果一个节点的杂质高于阈值,则该节点将分裂,否则,它是一个叶子。
- bootstrap:构建树时是否使用bootstrap样本。如果为 False,则使用整个数据集来构建每棵树。
- oob_score:是否使用out-of-bag样本来估计泛化准确度。
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=100)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
5.5随机森林超参数调优
调优随机森林的主要参数是n_estimators参数。一般来说,森林中的树越多,泛化性能越好,但它会减慢拟合和预测的时间。
我们还可以调优控制森林中每棵树深度的参数。有两个参数非常重要:max_depth和max_leaf_nodes。实际上,max_depth将强制具有更对称的树,而max_leaf_nodes会限制最大叶节点数量。
n_estimators = [100, 500, 1000, 1500]
max_features = ['auto', 'sqrt']
max_depth = [2, 3, 5]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4, 10]
bootstrap = [True, False]
params_grid = {'n_estimators': n_estimators, 'max_features': max_features,
'max_depth': max_depth, 'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf, 'bootstrap': bootstrap}
rf_clf = RandomForestClassifier(random_state=42)
rf_cv = GridSearchCV(rf_clf, params_grid, scoring="f1", cv=3, verbose=2, n_jobs=-1)
rf_cv.fit(X_train, y_train)
best_params = rf_cv.best_params_
print(f"Best parameters: {best_params}")
rf_clf = RandomForestClassifier(**best_params)
rf_clf.fit(X_train, y_train)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=True)
print_score(rf_clf, X_train, y_train, X_test, y_test, train=False)
最后
本文主要讲解了以下内容:
- 决策树和随机森林算法以及每种算法的参数。
- 如何调整决策树和随机森林的超参数。
- 在训练之前需要平衡你的数据集。
- 从每个类中抽取相同数量的样本。
- 通过将每个类的样本权重(sample_weight)的和归一化为相同的值。