一、背景
阿里云日志服务作为云原生可观测与分析平台。提供了一站式的数据采集、加工、查询分析、可视化、告警、消费与投递等功能。全面提升用户的研发、运维、运营、安全场景的数字化能力。
日志服务平台作为可观测性平台提供了数据导入、数据加工、聚集加工、告警、智能巡检、导出等功能,这些功能在日志服务被称为任务,并且具有大规模的应用,接下来主要介绍下这些任务的调度框架的设计与实践。

本次介绍主要分为四个部分:
- 任务调度背景
- 可观测性平台的亿级任务调度框架设计
- 任务调度框架在日志服务的大规模应用
- 展望
任务调度背景
通用调度
调度在计算机里面是一个非常常见的技术,从单机到分布式再到大数据系统,调度的身影无处不在。这里尝试总结出调度的一些共同特征。
- 操作系统:从单机操作系统Linux来看,内核通过时间片的方式来控制进程在处理器上的执行时间,进程的优先级与时间片挂钩,简单来说,进程的在单CPU或者某个CPU的执行由调度器来掌握;K8s被称为分布式时代的操作系统,在Pod创建后,K8s的控制面调度器通过对节点进行打分排序,最终选出适合的Node来运行Pod。
- 大数据分析系统:从最早的MapReduce使用公平调度器支持作业的优先级和抢占,到SQL计算引擎Presto通过Coordinator的调度器将执行计划中的任务分配到适合的worker上来执行,Spark通过DAGScheduler拆分成Stage,TaskScheduler将Stage对应的TaskSet最终调度到适合的Worker上来执行。
- 任务调度框架:在数据处理中常见的ETL处理任务、定时任务,这些任务具有多模的特点:定时执行、持续运行、一次性执行等。在任务执行过程中需要考虑任务的编排和状态一致性问题。

这里简单的对调度做一个抽象,如上图所示,调度负责将不同的Task分配到不同的Resource上执行,Task可以是进程、Pod、子任务;Resource为具体执行Task任务的资源,可以是处理器、线程池、节点、机器。通过这个抽象,可以看出调度在系统中的位置。
调度的覆盖面很广,本文主要集中在任务调度框架的设计与实践,这里先通过一些例子来看下任务调度的一些特点,以下主要讲任务分为定时类的任务和依赖类的任务两种来展开。
任务调度
定时类任务

定时执行可以理解为每个任务之间有时间先后顺序,并且要在特定的时间点执行,比如每隔1小时对日志进行监控,00点的监控任务需要首先执行,01点的监控任务需要在01点准时执行;同样,类似的定时场景,还有仪表盘订阅、定时计算等。
依赖类任务

除了定时执行,还有另外一种编排形式,比如顺序依赖,各个任务之间有先后执行的依赖,也叫Pipeline方式,还有一种比较常见的编排形式,拓扑依赖,也称为DAG,比如Task2/Task3需要等到Task1执行完成才可以执行,Task5需要等到Task3/Task4执行完才可以执行。
任务调度特点
任务调度在执行的过程中需要尽可能均衡的将任务分派到合适的机器或者执行器上去执行,比如要根据执行器的当前负载情况,要根据任务自身的特征进行分派执行;在执行器执行的过程中也可能会崩溃,退出,这时候需要将任务迁移到其他的执行器中。整个调度过程需要考虑到调度策略、FailOver、任务迁移等。接下来来看下任务调度的一个简单应用。
任务调度应用:一条日志的历险

上图中原始日志为一条Nginx访问日志,其中包括IP、时间、Method、URL、UserAgent等信息,这样一些原始日志并不利于我们进行分析,比如我们想统计访问最高的Top 10 URL,通过命令处理是这样的:
cat nginx_access.log |awk '{print $7}'| sort|uniq -c| sort -rn| head -10 | more- 1.
抛开命令的复杂性和原始日志的数据量不谈,即使需求稍微变化,命令就需要大量的改动,非常不利于维护,对日志进行分析的正确方式必然是使用分布式日志平台进行日志分析,原始日志蕴含着大量“信息”,但是这些信息的提取是需要一系列的流程。
首先是数据采集、需要通过Agent对分布在各个机器上的数据进行集中采集到日志平台,日志采集上来后需要进行清洗,比如对于Nginx访问日志使用正则提取,将时间、Method、URL等重要信息提取出来作为字段进行存储并进行索引构建,通过索引,我们可以使用类SQL的分析语法对日志进行分析、例如查看访问的Top 10 URL,用SQL来表达就会非常简洁清晰:
select url, count(1) as cnt from log group by url order by cnt desc limit 10- 1.
业务系统只要在服务,日志就会不断产生,可以通过对流式的日志进行巡检,来达到系统异常的检测目的,当异常发生时,我们可以通过告警通知到系统运维人员。
通用流程提取
从这样一个日志分析系统可以提取出一些通用的流程,这些通用的流程可以概括为数据摄入、数据处理、数据监测、数据导出。
除了日志,系统还有Trace数据、Metric数据,它们是可观测性系统的三大支柱。这个流程也适用于可观测性服务平台,接下来来看下一个典型的可观测服务平台的流程构成。
典型可观测服务平台数据流程

- 数据摄入:在可观测服务平台首先需要扩展数据来源,数据源可能包括各类日志、消息队列Kafka、存储OSS、云监控数据等,也可以包括各类数据库数据,通过丰富数据源的摄入,可以对系统有全方位的观测。
- 数据处理:在数据摄入到平台后,需要对数据进行清洗、加工,这个过程我们把他统称数据处理,数据加工可以理解为数据的各种变换和富华等,聚集加工支持对数据进行定时rolling up操作,比如每天计算过去一天汇总数据,提供信息密度更高的数据。
- 数据监测:可观测性数据本身反应了系统的运行状态,系统通过对每个组件暴露特定的指标来暴露组件的健康程度,可以通过智能巡检算法对异常的指标进行监控,比如QPS或者Latency的陡增或陡降,当出现异常时可以通过告警通知给相关运维人员,在指标的基础上可以做出各种运维或者运营的大盘,在每天定时发送大盘到群里也是一种场景的需求。
- 数据导出:可观测性数据的价值往往随着时间产生衰减,那么对于长时间的日志类数据出于留档的目的可以进行导出到其他平台。
从以上四个过程我们可以抽象出各类任务,分别负责摄入、处理、检测等,比如数据加工是一种常驻任务,需要持续对数据流进行处理,仪表盘订阅是一种定时任务,需要定时发出仪表盘到邮件或者工作群中。接下来将要介绍对各类任务的调度框架。
可观测性平台的亿级任务调度框架设计可观测平台任务特点
根据上面对可观测平台任务的介绍,可以总结一个典型的可观测平台的任务的特点:
- 业务复杂,任务类型多:数据摄入,仅数据摄入单个流程涉及数据源可能有几十上百个之多。
- 用户量大,任务数数量多:由于是云上业务,每个客户都有大量的任务创建需求。
- SLA要求高:服务可用性要求高,后台服务是升级、迁移不能影响用户已有任务的运行。
- 多租户:云上业务客户相互直接不能有影响。
可观测平台任务调度设计目标

根据平台任务的特点,对于其调度框架,我们需要达到上图中的目标
- 支持异构任务:告警、仪表盘订阅、数据加工、聚集加工每种任务的特点不一样,比如告警是定时类任务、数据加工是常驻类任务,仪表盘订阅预览是一次性任务。
- 海量任务调度:对于单个告警任务,假如每分钟执行一次,一天就会有1440次调度,这个数量乘以用户数再乘以任务数,将是海量的任务调度;我们需要达到的目标是任务数的增加不会对打爆机器的性能,特别是要做到水平扩缩容,任务数或者调度次数增加只需要线性增加机器即可。
- 高可用:作为云上业务,需要达到后台服务升级或者重启、甚至宕机对用户任务运行无影响的目的,在用户层面和后台服务层面都需要具有任务运行的监控能力。
- 简单高效的运维:对于后台服务需要提供可视化的运维大盘,可以直观的展示服务的问题;同时也要对服务进行告警配置,在服务升级、发布过程中可以尽量无人值守。
- 多租户:云上环境是天然有多租户场景,各个租户之间资源要做到严格隔离,相互之间不能有资源依赖、性能依赖。
- 可扩展性:面对客户的新增需求,未来需要支持更多的任务类型,比如已经有了MySQL、SqlServer的导入任务,在未来需要更多其他的数据库导入,这种情况下,我们需要做到不修改任务调度框架,只需要修改插件即可完成。
- API化:除了以上的需求,我们还需要做到任务的API化管控,对于云上用户,很多海外客户是使用API、Terraform来对云上资源做管控,所以要做到任务管理的API化。
可观测平台任务调度框架总体概览

基于上述的调度设计目标,我们设计了可观测性任务调度框架,如上图所示,下面从下到上来介绍。
- 存储层:主要包括任务的元数据存储和任务运行时的状态和快照存储。任务的元数据主要包括任务类型,任务配置、任务调度信息,都存储在了关系型数据库;任务的运行状态、快照存储在了分布式文件系统中。
- 服务层:提供了任务调度的核心功能,主要包括任务调度和任务执行两部分,分别对应前面讲的任务编排和任务执行模块。任务调度主要针对三种任务类型进行调度,包括常驻任务、定时任务、按需任务。任务执行支持多种执行引擎,包括presto、restful接口、K8s引擎和内部自研的ETL 2.0系统。
- 业务层:业务层包括用户直接在控制台可以使用到的功能,包括告警监控、数据加工、重建索引、仪表盘订阅、聚集加工、各类数据源导入、智能巡检任务、和日志投递等。
- 接入层:接入层使用Nginx和CGI对外提供服务,具有高可用,地域化部署等特性。
- API/SDK/Terraform/控制台:在用户侧,可以使用控制台对各类任务进行管理,对于不同的任务提供了定制化的界面和监控,同时也可以使用API、SDK、Terraform对任务进行增删改查。
- 任务可视化:在控制台我们提供了任务执行的可视化和任务监控的可视化,通过控制台用户可以看出看到任务的执行状态、执行历史等,还可以开启内置告警对任务进行监控。
任务调度框架设计要点
接下来从几方面对任务调度框的设计要点进行介绍,主要包括以下几方面来介绍:
- 异构任务模型抽象
- 调度服务框架
- 大规模任务支持
- 服务高可用设计
- 稳定性建设
任务模型抽象

接下来看下任务模型的抽象:
- 对于告警监控、仪表盘订阅、聚集加工等需要定时执行的任务,抽象为定时任务,支持定时和Cron表达式设置。
- 对于数据加工、索引重建、数据导入等需要持续运行的任务,抽象为常驻任务,这类任务往往只需要运行一次,可以有也可以没有结束状态。
- 对于数据加工的预览、仪表盘订阅的预览等功能,是在用户点击时才会需要创建一个任务来执行,执行完成即可退出,不需要保存任务状态,这类任务抽象为DryRun类型,或者按需任务。
调度服务框架

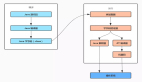
服务基础框架使用了Master-Worker架构,Master负责任务的分派和Worker的管控,Master将数据抽象为若干Partitions,然后将这些Partitions分派给不同的Worker,实现了对任务的分而治之,在Worker执行的过程中Master还也可以根据Worker的负载进行Partitions的动态迁移,同时在Worker重启升级过程中,Master也会对Partition进行移出和移入;
任务的调度主要在Worker层来实现,每个Worker负责拉取对应Partitions的任务,然后通过JobLoader对任务进行加载,注意:这里只会加载当前Worker对应Partitions的任务列表,然后Scheduler对任务进行调度的编排,这里会涉及常驻任务、定时任务、按需任务的调度,Scheduler将编排好的任务发送到JobExecutor进行执行,JobExecutor在执行的过程中需要实时对任务的状态进行持久化保存到RedoLog中,在下次Worker升级重新启动的过程中,需要从RedoLog中加载任务的状态,从而保证任务状态的准确性。
大规模任务支持

通过任务服务框架的介绍,我们知道Partitions是Master与Worker沟通的桥梁,也是对大规模任务进行分而治之的介质。如上图所示,假设有N个任务,按照一定的哈希算法将N个任务映射到对应的Partition,因为Worker关联特定的Partition,这样Worker就可以跟任务关联起来,比如任务j1、j2对应的partition是p1,而p1对应的Worker是worker1,这样j1、j2就可以在worker1上执行。需要说明的如下:
- Worker与Partition的对应关系并非一成不变,是一个动态的映射,在Worker重启或者负载较高时,其对应的Partition会迁移到其他的Worker上,所以Worker需要实现Partition的移入和移出操作。
- 任务数量增加的时候,因为有Partition这个中间层,只需要增加Worker的数量就可以满足任务增长时的需求,达到水平扩展的目的。增加新Worker后,可以分担更多的Partition
服务高可用设计
服务的高可用主要是服务的可用性时间,作为后台服务肯定有重启、升级的需求,高可用场景主要涉及到Partition迁移的处理,在Worker重启、Worker负载较高时、Worker异常时,都会有Partition迁移的需求,在Partition迁移的过程中,任务也需要进行迁移,任务的迁移就涉及到状态的保留,类似CPU上进程的航线文切换。

对于任务的切换,我们使用了RedoLog的方式来保存任务的状态,一个任务可以被分为多个阶段,对应任务执行的状态机,在每个阶段执行时都对其进行内存Checkpoint的更新和RedoLog的更新,RedoLog是持久化到之前提到的分布式文件系统中,使用高性能的Append的方式进行顺序写入,在Partition迁移到新的Worker后,新的Worker在对RedoLog进行加载,就可以完成任务状态的恢复。
这里涉及一个优化,RedoLog如果一直使用Append的方式进行写入,势必会造成RedoLog越来越膨胀,也会造成Worker加载Partition时速度变慢,对于这种情况,我们使用了Snapshot的方式,将过去一段时间的RedoLog进行合并,这样只需要在加载Partition时,加载Snapshot和Snaphost之后的RedoLog就可以减少文件读取的次数和开销,提高加载速度。
稳定性建设
稳定性建设主要涉及以下几方面内容:
- 发布流程:
- 从编译到发布全Web端白屏化操作,模板化发布,每个版本都可跟踪、回退。
- 支持集群粒度、任务类型粒度的灰度控制,在发布时可以进行小范围验证,然后全量发布。
- 运维流程:
- 提供内部运维API、Web端操作,对于异常Job进行修复、处理。减少人工介入运维。
- On-Call:
- 在服务内部,我们开发了内部巡检功能,查找异常任务,例如某些任务启动时间过长、停止时间过长都会打印异常日志,可以对异常日志进行跟踪和监控。
- 通过异常日志,使用日志服务告警进行监控,出现问题可以及时通知运维人员。
- 任务监控:
- 用户侧:在控制台我们针对各类任务提供了监控仪表盘和内置告警配置。
- 服务侧:在后台,可以看到集群粒度任务的运行状态,便于后台运维人员进行服务的监控。
- 同时,对于任务的执行状态和历史都会存入特定的日志库中,以便出现问题时进行追溯和诊断。
下面是一些服务侧的部分大盘示例,展示的是告警的一些执行状态。

下面是用户侧的任务监控状态和告警的展示。


大规模应用
在日志服务,任务的调度已经有了大规模的应用,下面是某地域单集群的任务的运行状态,因为告警是定时执行且使用场景广泛,其单日调度次数达到了千万级别,聚集加工在Rolling up场景中有很高场景的应用,也达到了百万级别;对于数据加工任务因为是常驻任务,调度频率低于类似告警类的定时任务。
接下来以一个聚集加工为例来看下任务的调度场景。
典型任务:聚集加工

聚集加工是通过定时对一段时间的数据进行聚集查询,然后将结果存入到另一个库中,从而将高信息密度的信息进行提取,相对于原始数据具有降维、低存储、高信息密度的特点。适合于定时分析、全局聚合的场景。

这里是一个聚集加工的执行状态示例,可以看到每个时间区间的执行情况,包括处理行数、处理数据量、处理结果情况,对于执行失败的任务,还可以进行手动重试。
对于聚集加工并非定时执行这么简单的逻辑,在过程中需要处理超时、失败、延迟等场景,接下来对每种场景进行一个简单介绍。
调度场景一:实例延迟执行
无论实例是否延迟执行,实例的调度时间都是根据调度规则预先生成的。虽然前面的实例发生延迟时,可能导致后面的实例也延迟执行,但通过追赶执行进度,可逐渐减少延迟,直到恢复准时运行。

调度场景二:从某个历史时间点开始执行聚集加工作业
在当前时间点创建聚集加工作业后,按照调度规则对历史数据进行处理,从调度的开始时间创建补运行的实例,补运行的实例依次执行直到追上数据处理进度后,再按照预定计划执行新实例。 
调度场景三:固定时间内执行聚集加工作业
如果需要对指定时间段的日志做调度,则可设置调度的时间范围。如果设置了调度的结束时间,则最后一个实例(调度时间小于调度结束时间)执行完成后,不再产生新的实例。

调度场景四:修改调度配置对生成实例的影响
修改调度配置后,下一个实例按照新配置生成。一般建议同步修改SQL时间窗口、调度频率等配置,使得实例之间的SQL时间范围可以连续。

调度场景五:重试失败的实例
- 自动重试
- 如果实例执行失败(例如权限不足、源库不存在、目标库不存在、SQL语法不合法),系统支持自动重试
- 手动重试
- 当重试次数超过您配置的最大重试次数或重试时间超过您配置的最大运行时间时,重试结束,该实例状态被置为失败,然后系统继续执行下一个实例。
展望
- 动态任务类型:增加对于动态任务类型的支持,例如更复杂的具有任务间依赖关系的任务调度。
- 多租户优化:目前对于任务使用简单的Quota限制,未来对多租户的QoS进行的进一步细化,以支持更大的Quota设置。
- API优化、完善:目前的任务类型也在快速更新中,任务API的迭代速度还有些差距,需要增强任务API的优化,达到增加一种任务类型,不需要修改或者少量更新API的目的。