












一位7年工作经验的小伙伴,面试被问到这样一道题,说:”谈谈你对Kafka副本Leader选举原理的理解“。当时,他想,这Kafka用的不就是Zookeeper 的选举吗?难道Kafka又自己搞了一套。没错,这回Kafka自己造了一个轮子。
那么今天,我给大家来聊一聊我对Kafka副本Leader选举原理的理解。
1、选举原理
确实Kafka早期的版本就是直接用Zookeeper来完成选举的。利用了Zookeeper的Watch机制;节点不允许重复写入以及临时节点这些特性。这样实现比较简单,省事。但是也会存在一定的弊端。比如分区和副本数量过多,所有的副本都直接参与选举的话,一旦某个出现节点的增减,就会造成大量的Watch事件被触发,ZooKeeper的就会负载过重,不堪重负。
新版本的Kafka中换了一种实现方式。不是所有的Repalica都参与Leader选举,而是由其中的一个Broker统一来指挥,这个Broker的角色就叫做Controller控制器。
Kafka要先从所有Broker中选出唯一的一个Controller。
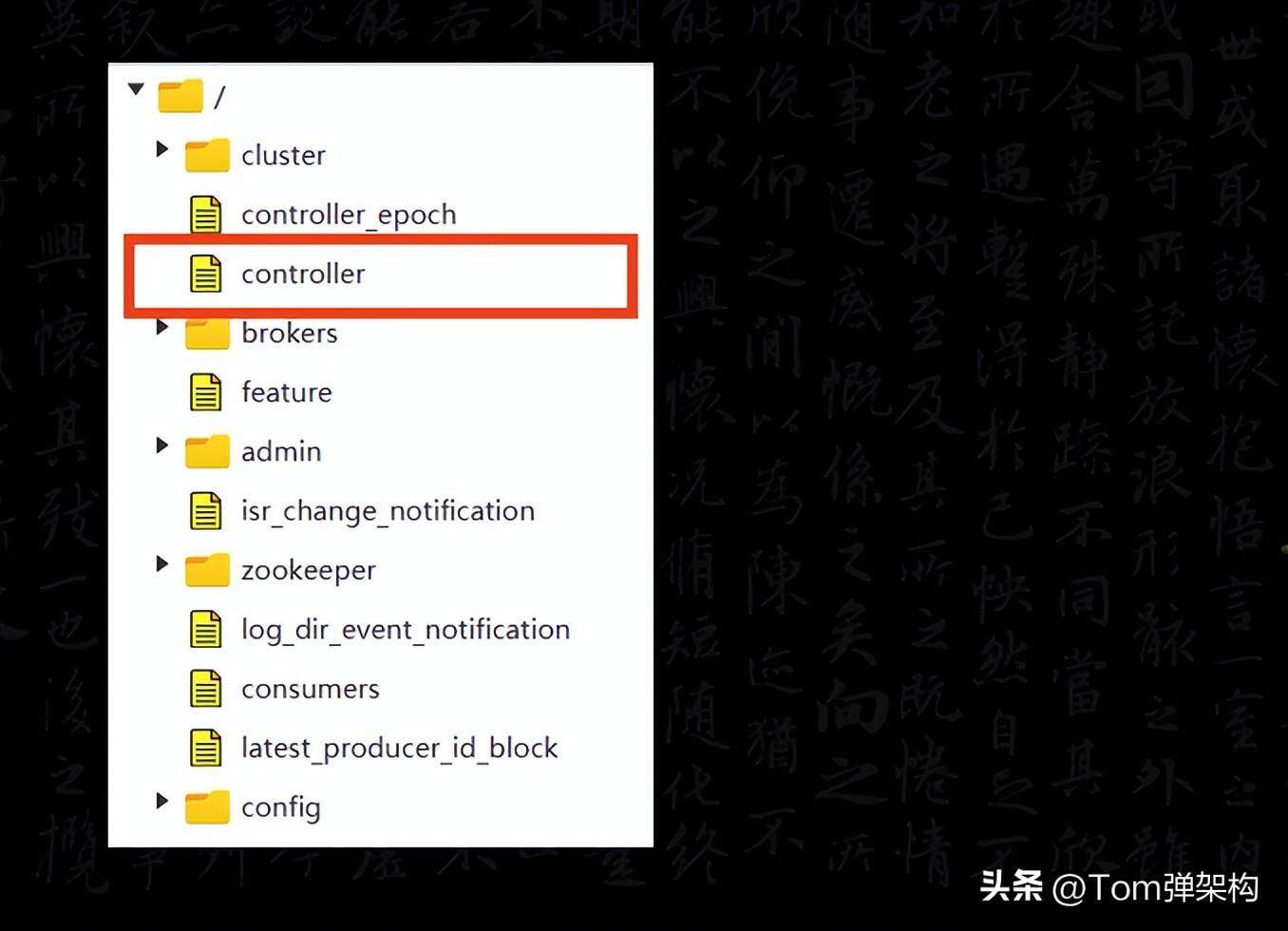
所有的Broker会尝试在Zookeeper中创建临时节点/controller,谁先创建成功,谁就是Controller。那如果Controller挂掉或者网络出现问题,ZooKeeper上的临时节点就会消失。其他的Broker通过Watch监听到Controller下线的消息后,继续按照先到先得的原则竞选Controller。这个Controller就相当于选举委员会的主席。
当一个节点成为Controller之后,他就会承担以下职责:
监听Broker变化、监听Topic变化、监听Partition变化、获取和管理Broker、Topic、Partition的信息、管理Partiontion的主从信息。
2、选举规则
Controller确定以后,就可以开始做分区选主的事情。接下来就是找候选人。显然,每个Replica都想推荐自己,但不是所有的Replica都有竞选资格。只有在ISR(In-Sync Replicas)保持心跳同步的副本才有资格参与竞选。就好比是皇帝每天着急皇子们开早会,只有每天来打卡的皇子才能加入ISR。那些请假的、迟到的没有资格参与选举。
接下来,就是Leader选举,就相当于要在众多皇子中选出太子。在分布式选举中,有非常多的选举协议比如ZAB、Raft等等,他们的思想归纳起来都是:先到先得,少数服从多数。但是Kafka没有用这些方法,而是用了一种自己实现的算法。
提到Kafka官方的解释是,它的选举算法和微软的PacificA算法最相近。大致意思就是,默认是让ISR中第一个Replica变成Leader。比如ISR是1、5、9,优先让1成为Leader。这个跟中国古代皇帝传位是一样的,优先传给皇长子。
假设,我们创建一个4个分区2个副本的Topic,它的Leader分布是这样的,如图所示:
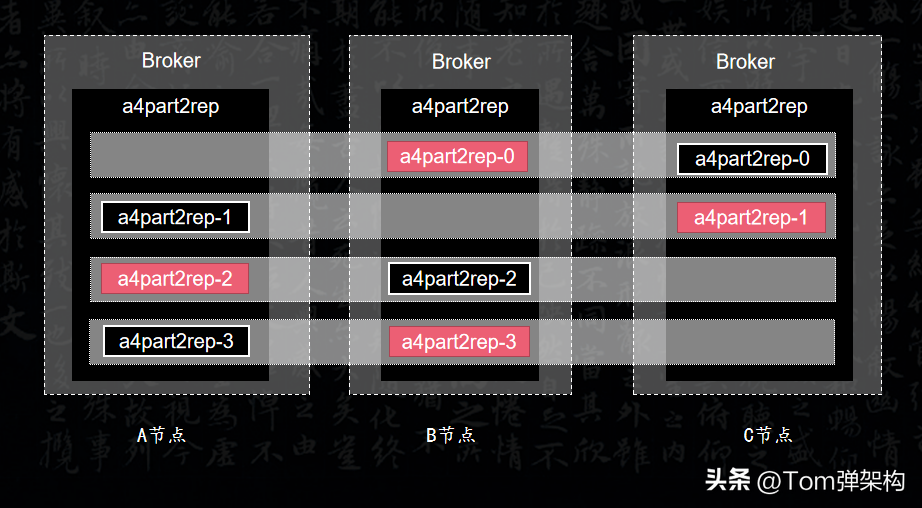
第1个分区的副本Leader,落在B节点上。第2个分区的副本Leader落在C节点上,第3个分区的副本Leader落在A节点上,第4个分区的副本Leader落在B节点上。如果有更多副本,就以此类推。我们发现Leader的选举的规则相当于蛇形走位。
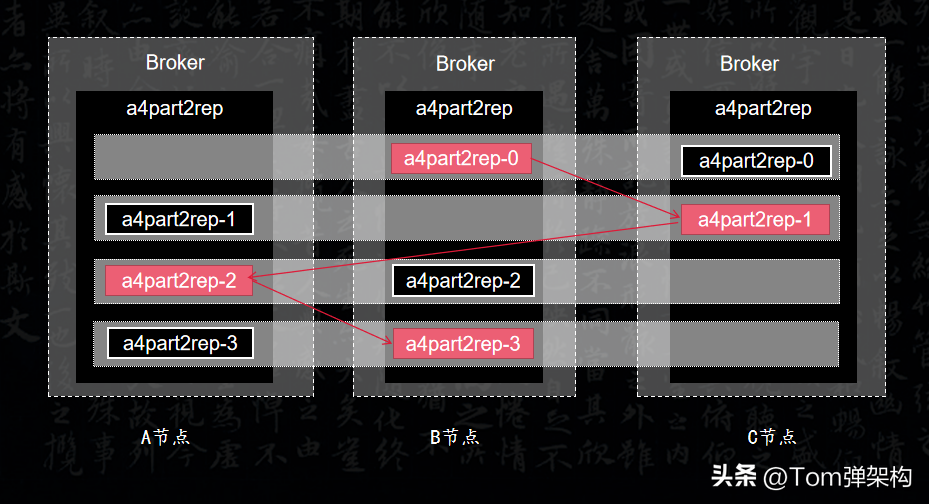
这样设计的好处是可以提高数据副本的容灾能力。将Leader和副本完全错开,从而不至于一挂全挂。
以上就是我对Kafka副本Leader选举原理的理解!





























