













1、写在前面
面试大厂时,一旦简历上写了Kafka,几乎必然会被问到一个问题:说说acks参数对消息持久化的影响?
这个acks参数在kafka的使用中,是非常核心以及关键的一个参数,决定了很多东西。
所以无论是为了面试还是实际项目使用,大家都值得看一下这篇文章对Kafka的acks参数的分析,以及背后的原理。
2、如何保证宕机的时候数据不丢失?
如果要想理解这个acks参数的含义,首先就得搞明白kafka的高可用架构原理。
比如下面的图里就是表明了对于每一个Topic,我们都可以设置他包含几个Partition,每个Partition负责存储这个Topic一部分的数据。
然后Kafka的Broker集群中,每台机器上都存储了一些Partition,也就存放了Topic的一部分数据,这样就实现了Topic的数据分布式存储在一个Broker集群上。
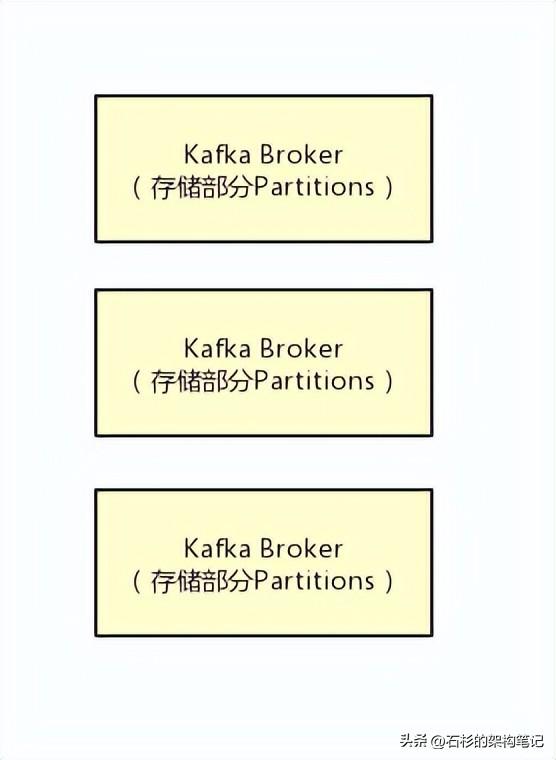
但是有一个问题,万一 一个Kafka Broker宕机了,此时上面存储的数据不就丢失了吗?
没错,这就是一个比较大的问题了,分布式系统的数据丢失问题,是他首先必须要解决的,一旦说任何一台机器宕机,此时就会导致数据的丢失。
3、多副本冗余的高可用机制
所以如果大家去分析任何一个分布式系统的原理,比如说zookeeper、kafka、redis cluster、elasticsearch、hdfs,等等,其实他都有自己内部的一套多副本冗余的机制,多副本冗余几乎是现在任何一个优秀的分布式系统都一般要具备的功能。
在kafka集群中,每个Partition都有多个副本,其中一个副本叫做leader,其他的副本叫做follower,如下图。
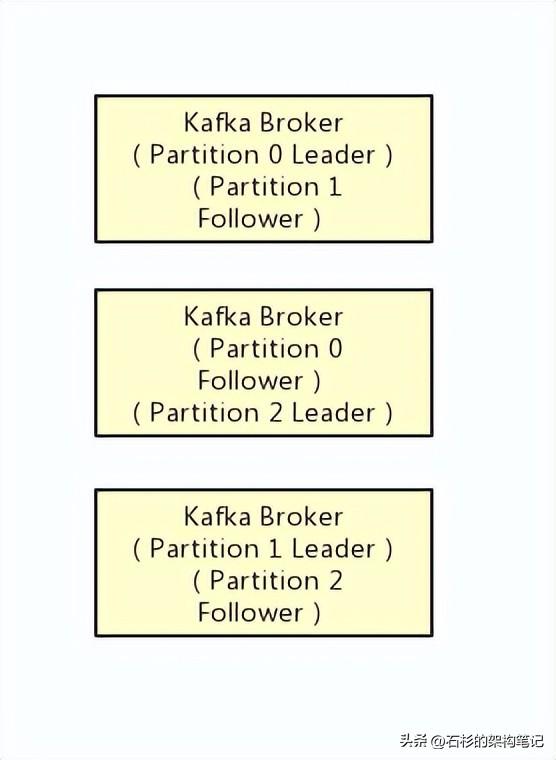
如上图所示,假设一个Topic拆分为了3个Partition,分别是Partition0,Partiton1,Partition2,此时每个Partition都有2个副本。
比如Partition0有一个副本是Leader,另外一个副本是Follower,Leader和Follower两个副本是分布在不同机器上的。
这样的多副本冗余机制,可以保证任何一台机器挂掉,都不会导致数据彻底丢失,因为起码还是有副本在别的机器上的。
4、多副本之间数据如何同步?
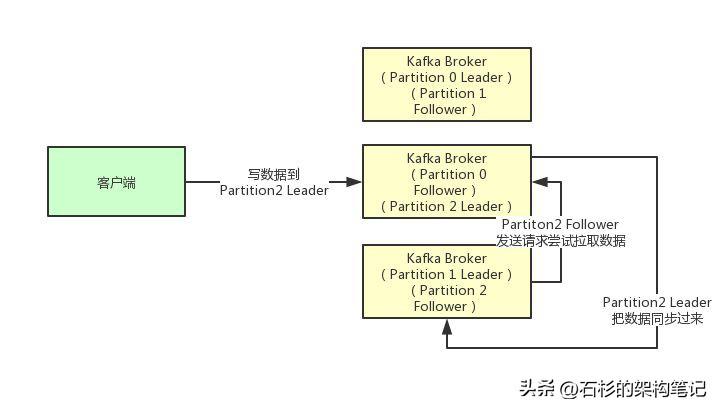
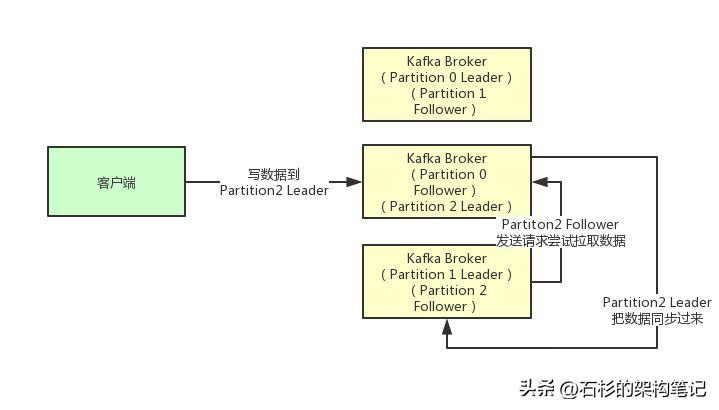
接着我们就来看看多个副本之间数据是如何同步的?其实任何一个Partition,只有Leader是对外提供读写服务的
也就是说,如果有一个客户端往一个Partition写入数据,此时一般就是写入这个Partition的Leader副本。
然后Leader副本接收到数据之后,Follower副本会不停的给他发送请求尝试去拉取最新的数据,拉取到自己本地后,写入磁盘中。如下图所示:
5、ISR到底指的是什么东西?
既然大家已经知道了Partiton的多副本同步数据的机制了,那么就可以来看看ISR是什么了。
ISR全称是“In-Sync Replicas”,也就是保持同步的副本,他的含义就是,跟Leader始终保持同步的Follower有哪些。
大家可以想一下 ,如果说某个Follower所在的Broker因为JVM FullGC之类的问题,导致自己卡顿了,无法及时从Leader拉取同步数据,那么是不是会导致Follower的数据比Leader要落后很多?
所以这个时候,就意味着Follower已经跟Leader不再处于同步的关系了。但是只要Follower一直及时从Leader同步数据,就可以保证他们是处于同步的关系的。
所以每个Partition都有一个ISR,这个ISR里一定会有Leader自己,因为Leader肯定数据是最新的,然后就是那些跟Leader保持同步的Follower,也会在ISR里。
6、acks参数的含义
铺垫了那么多的东西,最后终于可以进入主题来聊一下acks参数的含义了。
如果大家没看明白前面的那些副本机制、同步机制、ISR机制,那么就无法充分的理解acks参数的含义,这个参数实际上决定了很多重要的东西。
首先这个acks参数,是在KafkaProducer,也就是生产者客户端里设置的
也就是说,你往kafka写数据的时候,就可以来设置这个acks参数。然后这个参数实际上有三种常见的值可以设置,分别是:0、1 和 all。
第一种选择是把acks参数设置为0,意思就是我的KafkaProducer在客户端,只要把消息发送出去,不管那条数据有没有在哪怕Partition Leader上落到磁盘,我就不管他了,直接就认为这个消息发送成功了。
如果你采用这种设置的话,那么你必须注意的一点是,可能你发送出去的消息还在半路。结果呢,Partition Leader所在Broker就直接挂了,然后结果你的客户端还认为消息发送成功了,此时就会导致这条消息就丢失了。
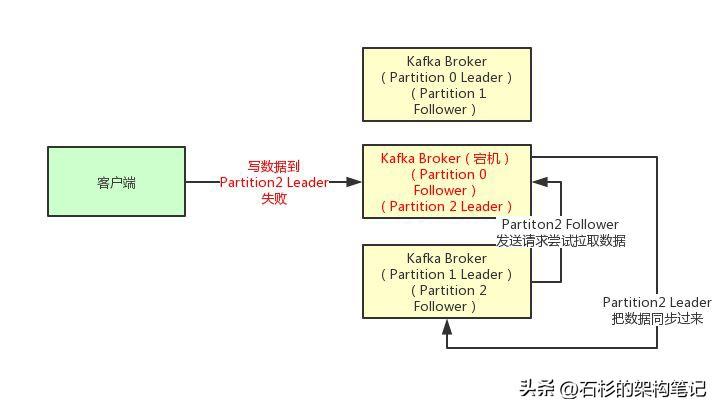
第二种选择是设置 acks = 1,意思就是说只要Partition Leader接收到消息而且写入本地磁盘了,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。
这种设置其实是kafka默认的设置,大家请注意,划重点!这是默认的设置
也就是说,默认情况下,你要是不管acks这个参数,只要Partition Leader写成功就算成功。
但是这里有一个问题,万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了,此时也会导致这条消息丢失,因为人家客户端已经认为发送成功了。
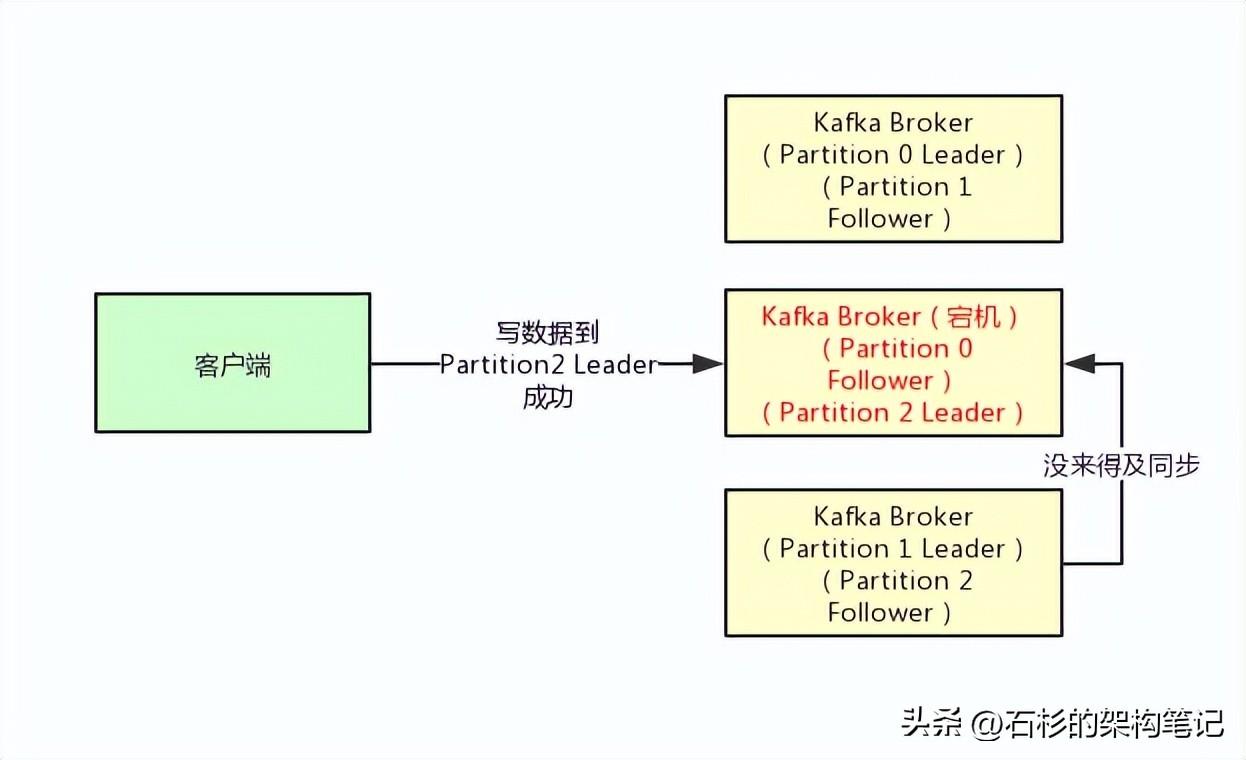
最后一种情况,就是设置acks=all,这个意思就是说,Partition Leader接收到消息之后,还必须要求ISR列表里跟Leader保持同步的那些Follower都要把消息同步过去,才能认为这条消息是写入成功了。
如果说Partition Leader刚接收到了消息,但是结果Follower没有收到消息,此时Leader宕机了,那么客户端会感知到这个消息没发送成功,他会重试再次发送消息过去。
此时可能Partition 2的Follower变成Leader了,此时ISR列表里只有最新的这个Follower转变成的Leader了,那么只要这个新的Leader接收消息就算成功了。
7、最后的思考
acks=all 就可以代表数据一定不会丢失了吗?
当然不是,如果你的Partition只有一个副本,也就是一个Leader,任何Follower都没有,你认为acks=all有用吗?
当然没用了,因为ISR里就一个Leader,他接收完消息后宕机,也会导致数据丢失。
所以说,这个acks=all,必须跟ISR列表里至少有2个以上的副本配合使用,起码是有一个Leader和一个Follower才可以。
这样才能保证说写一条数据过去,一定是2个以上的副本都收到了才算是成功,此时任何一个副本宕机,不会导致数据丢失。
所以希望大家把这篇文章好好理解一下,对大家出去面试,或者工作中用kafka都是很好的一个帮助。

















