这篇文章,给大家聊一个消息中间件相关的技术话题,对于一个优秀的消息中间件而言,客户端与服务端通信的时候,对于这个网络通信的机制应该如何设计,才能保证性能最优呢?甚至通过优秀的设计,让性能提升10倍以上。
我们本文就以Kafka为例来给大家分析一下,Kafka在客户端与服务端通信的时候,底层的一些网络通信相关的机制如何设计以及如何进行优化的。
1、客户端与服务端的交互
假如我们用kafka作为消息中间件,势必会有客户端作为生产者向他发送消息,这个大家应该都可以理解。

对于Kafka来说,他本身是支持分布式的消息存储的,什么意思呢?
比如说现在你有一个“Topic”,一个“Topic”你就可以理解为一个消息数据的逻辑上的集合。
比如现在你要把所有的订单数据都发送到一个“Topic”里去,那么这个“Topic”就叫做“OrderTopic”,里面都放的是订单数据。
接着这个“Topic”的数据可能量很大很大,不可能放在一台机器上吧?
所以呢,我们就可以分散存储在多台Kafka的机器上,每台机器存储一部分的数据即可。
这就是Kafka的分布式消息存储的机制,每个Kafka服务端叫做一个Broker,负责管理一台机器上的数据。
一起来看看下面的图:

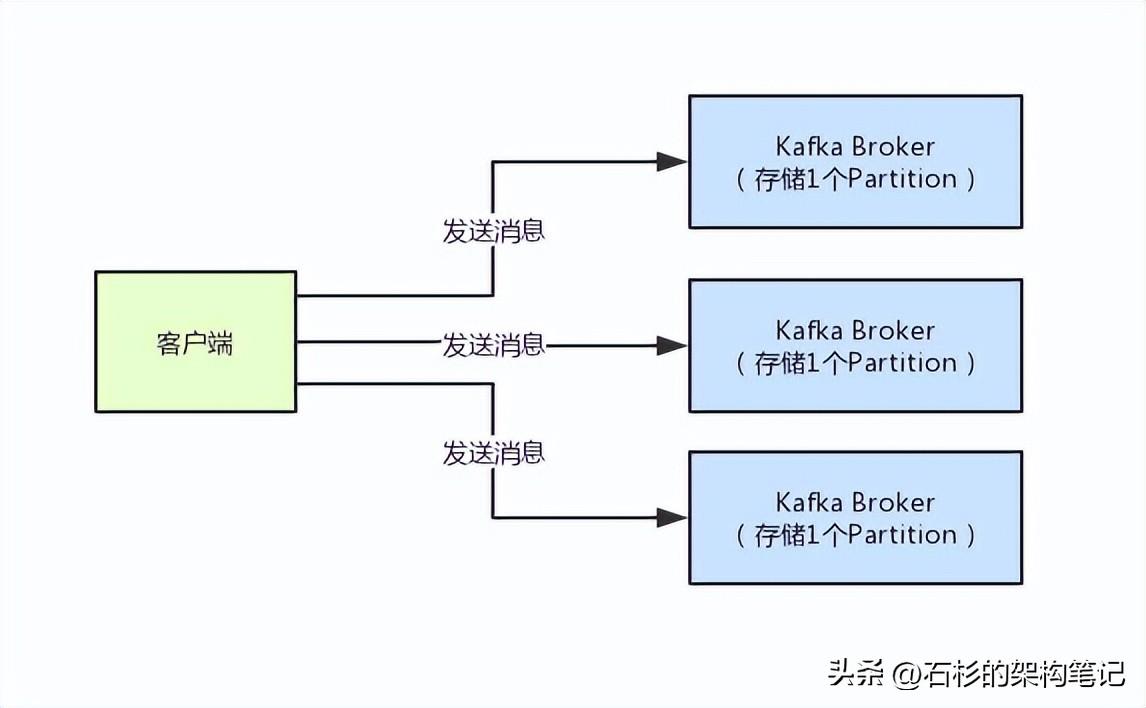
一个“Topic”可以拆分为多个“Partition”,每个“Partition”存储一部分数据,每个Partition都可以放在不同的Kafka Broker机器上,这样就实现了数据分散存储在多台机器上的效果了。
然后客户端在发送消息到Kafka Broker的时候,比如说你限定了“OrderTopic”的订单数据拆分为3个“Partition”,那么3个“Partition”分别放在一个Kafka Broker上,那么也就是要把所有的订单数据分发到三个Kafka Broker上去。
此时就会默认情况下走一个负载均衡的策略,举个例子,假设订单数据一共有3万条,就会给每个Partition分发1万条订单消息,这样订单数据均匀分散在了3台Broker机器上。
整个过程,如下图所示:
2、频繁网络通信带来的性能低下问题
好了,现在问题来了,客户端在发送消息给Kafka Broker的时候,比如说现在要发送一个订单到Kafka上去,此时他是怎么发送过去呢?
是直接一条订单消息就对应一个网络请求,发送到一台Broker上去吗?
如果是这样做的话,那势必会导致频繁的跟一台broker进行网络通信,频繁的网络通信,每次都涉及到复杂的网络连接、传输的流程,那么进而会导致客户端性能的低下。
给大家举个例子,比如说每次通过一个网络通信发送一条订单到broker,需要耗时10ms。
那么如果一个订单就一次网络通信发送到broker,每秒最多就是发送100个订单了,大家想想,是不是这个道理?
但是假如说你每秒有10000个订单要发送,此时就会造成你的发送性能远远跟不上你的需求,也就是性能的低下,看起来你的系统发送订单到kafka的速度就是特别的慢。

3、batch机制:多条消息打包成一个batch
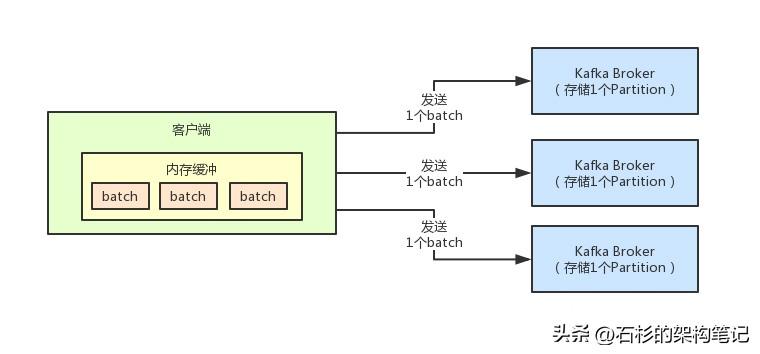
所以首先针对这个问题,kafka做的第一个优化,就是实现了batch机制。
这个意思就是说,他会在客户端放一个内存缓冲区,每次你写一条订单先放到内存缓冲区里去,然后在内存缓冲区里,会把多个订单给打包起来成为一个batch。
比如说默认kafka规定的batch的大小是16kb,那么意思就是,你默认就是多条订单凑满16kb的大小,就会成为一个batch,然后他就会把这个batch通过网络通信发送到broker上去。
假如说一个batch发送到broker,同样也是耗费10ms而已,但是一个batch里可以放入100条订单,那么1秒是不是可以发送100个batch?
此时,1秒是不是就可以发送10000条订单出去了?
而且在打包消息形成batch的时候,是有讲究的,你必须是发送到同一个Topic的同一个Partition的消息,才会进入一个batch。
这个batch里就代表要发送到同一个Partition的多条消息,这样后续才能通过一个网络请求,就把这个batch发送到broker,对应写入一个Parititon中。
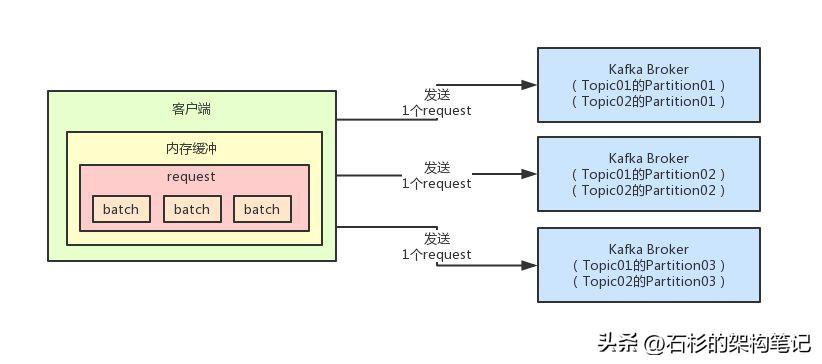
4、request机制:多个batch打包成一个request
事情到这里就结束了吗?还没有!
比如现在我们要是手头有两个Topic,每个Topic都有3个Partition,那么每个Broker是不是就会存放2个Partition?其中1个Partition是Topic01的,1个Partition是Topic02的。
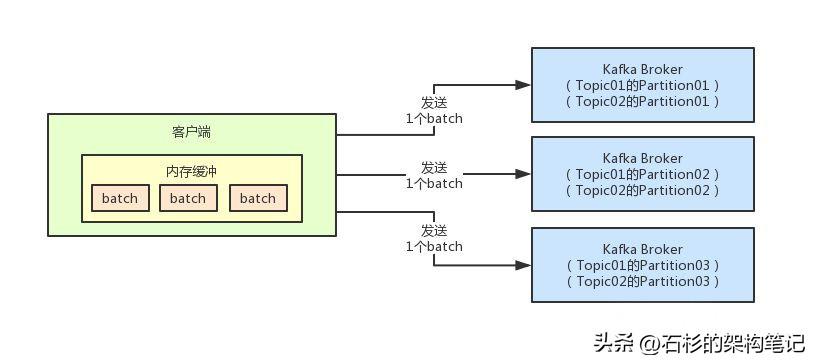
现在假如说针对Topic01的Partition02形成了一个batch,针对Topic02的Partition02也形成了一个batch,但是这两个batch其实都是发往同一个Broker的,如上图的第二个Broker。
此时,还是一个网络请求发送一个batch过去吗?
其实就完全没必要了,完全此时可以把多个发往同一个Broker的batch打包成一个request,然后一个request通过一次网络通信发送到 那个Broker上去。
假设一次网络通信还是10ms,那么这一次网络通信就发送了2个batch过去。
通过这种多个batch打包成一个request一次性发往Broker的方式,又进一步提升了网络通信的效率和性能。
其实 batch机制 + request 机制,都是想办法把很多数据打包起来,然后一次网络通信尽量多发送一些数据出去,这样可以提升单位时间内发送数据的数量。
这个单位时间内发送数据的数量,也就是所谓的“吞吐量”,也就是单位时间内可以发送多少数据到broker上去。
比如说每秒钟可以发送3万条消息过去,这就是代表了客户端的“吞吐量”有多大。
因此,通过搞清楚这个原理,就可以学习到这种非常优秀的设计思想。而且在面试的时候,如果跟面试官聊到kafka,也可以跟面试官侃侃kafka底层,是如何有效的提升网络通信性能的。
最后再来一张图,作为全文总结。