本文转自雷锋网,如需转载请至雷锋网官网申请授权。
自从 DALL-E 2 问世以来,很多人都认为,能够绘制逼真图像的 AI 是迈向通用人工智能(AGI)的一大步。OpenAI 的 CEO Sam Altman 曾在 DALL-E 2 发布的时候宣称“AGI is going to be wild”,媒体也都在渲染这些系统对于通用智能进展的重大意义。
但真的是如此吗?知名 AI 学者(给 AI 泼冷水爱好者) Gary Marcus 表示“持保留意见”。
最近,他提出,在评估 AGI 的进展时,关键要看像 Dall-E、Imagen、Midjourney 和 Stable Diffusion 这样的系统是否真正理解世界,从而能够根据这些知识进行推理并进行决策。
在判断这些系统之于 AI (包括狭义和广义的 AI)的意义时,我们可以提出以下三个问题:
图像合成系统能否生成高质量的图像?
它们能否将语言输入与它们产生的图像关联起来?
它们了解它们所呈现出的图像背后的世界吗?
1 AI 不懂语言与图像的关联
在第一个问题上,答案是肯定的。区别只在于,在用 AI 生成图像这件事儿上,经过训练的人类艺术家能做得更好。
在第二个问题上,答案就不一定了。在某些语言输入上,这些系统能表现良好,比如下图是 DALL-E 2 生成的“骑着马的宇航员”:

但在其他一些语言输入上,这些 AI 就表现欠佳、很容易被愚弄了。比如前段时间 Marcus 在推特上指出,这些系统在面对“骑着宇航员的马”时,难以生成对应的准确图像:

尽管深度学习的拥护者对此进行了激烈的反击,比如 AI 研究员 Joscha Bach 认为“Imagen 可能只是使用了错误的训练集”,机器学习教授 Luca Ambrogioni 反驳说,这正表明了“Imagen 已经具有一定程度的常识”,所以拒绝生成一些荒谬的东西。

还有一位谷歌的科学家 Behnam Neyshabur 提出,如果“以正确的方式提问”,Imagen 就可以画出“骑着宇航员的马”:

但是,Marcus 认为,问题的关键不在于系统能否生成图像,聪明的人总能找到办法让系统画出特定的图像,但这些系统并没有深刻理解语言与图像之间的关联,这才是关键。
2 不知道自行车轮子是啥?怎么能称是AGI?
系统对语言的理解还只是一方面,Marcus 指出,最重要的是,判断 DALL-E 等系统对 AGI 的贡献最终要取决于第三个问题:如果系统所能做的只是以一种偶然但令人惊叹的方式将许多句子转换为图像,它们可能会彻底改变人类艺术,但仍然不能真正与 AGI 相提并论,也根本代表不了 AGI。
让 Marcus 对这些系统理解世界的能力感到绝望的是最近的一些例子,比如平面设计师 Irina Blok 用 Imagen 生成的“带有很多孔的咖啡杯”图像:

正常人看了这张图都会觉得它违反常识,咖啡不可能不从孔里漏出来。类似的还有:
“带有方形轮子的自行车”

Gary Marcus:文本生成图像系统理解不了世界,离 AGI 还差得远
“布满仙人掌刺的厕纸”

Gary Marcus:文本生成图像系统理解不了世界,离 AGI 还差得远
说“有”容易说“无”难,谁能知道一个不存在的事物应当是什么样?这也是让 AI 绘制不可能事物的难题所在。
但又或许,系统只是“想”绘制一个超现实主义的图像呢,正如 DeepMind 研究教授 Michael Bronstein 所说的,他并不认为那是个糟糕的结果,换做是他,也会这样画。

那么如何最终解决这个问题呢?Gary Marcus 在最近同哲学家 Dave Chalmers 的一次交谈中获得了新的灵感。
为了了解系统对于部分和整体、以及功能的认识, Gary Marcus 提出了一项对系统性能是否正确有更清晰概念的任务,给出文本提示“Sketch a bicycle and label the parts that roll on the ground”(画出一辆自行车并标记出在地面上滚动的部分),以及“Sketch a ladder and label one of the parts you stand on”(画出一个梯子并标记出你站立的部分)。
这个测试的特别之处在于,并不直接给出“画出一辆自行车并标记出轮子”、“画出一个梯子并标记出踏板”这样的提示,而是让 AI 从“地面上滚动的部分”、“站立的部分”这样的描述中推理出对应的事物,这正是对 AI 理解世界能力的考验。
但 Marcus 的测试结果表明,Craiyon(以前称为 DALL-E mini)在这种事情上做得一塌糊涂,它并不能理解自行车的轮子和梯子的踏板是什么:


那么这是不是 DALL-E Mini 特有的问题呢?
Gary Marcus 发现并不是,在目前最火的文本生成图像系统 Stable Diffusion 中也出现了同样的结果。
比如,让 Stable Diffusion “画一个人,并把拿东西的部分变成紫色”(Sketch a person and make the parts that hold things purple),结果是:

显然,Stable Diffusion 并不理解人的双手是什么。
而在接下来的九次尝试中,只有一次成功完成(在右上角),而且准确性还不高:

下一个测试是,“画出一辆白色自行车,并将用脚推动的部分变成橙色”,得到图像结果是:

所以它也不能理解什么是自行车的脚踏板。
而在画出“自行车的草图,并标记在地面上滚动部分”的测试中,其表现得也并没有很好:

如果文本提示带有否定语,比如“画一辆没有轮子的白色自行车",其结果如下:

这表明系统并不理解否定的逻辑关系。
即便是“画一辆绿色轮子的白色自行车”这样简单的只关注部分与整体关系提示,而且也没有出现复杂的语法或功能等,其得到的结果仍存在问题:

因此,Marcus 质问道,一个并不了解轮子是什么、或是它们的用途的系统,能称得上是人工智能的重大进步么?
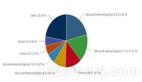
今天,Gary Marcus 还针对这个问题发出了一个投票调查,他提出的问题是,“Dall-E 和 Stable Diffusion 等系统,对它们所描绘的世界到底了解有多少?”
其中,86.1% 的人认为系统对世界的理解并不多,只有 13.9% 的人认为这些系统理解世界的程度很高。

对此,Stability.AI 的首席执行官 Emad Mostique 也回应称,我投的是“并不多”,并承认“它们只是拼图上的一小块。”

来自科学机构 New Science 的 Alexey Guzey 也有与 Marcus 类似的发现,他让 DALL-E 画出一辆自行车,但结果只是将一堆自行车的元素堆在一起。

所以他认为,并没有任何能真正理解自行车是什么以及自行车如何工作的模型,生成当前的 ML 模型几乎可以与人类媲美或取代人类是很荒谬的。
大家怎么看?