














什么是 celery
这次我们来介绍一下 Python 的一个第三方模块 celery,那么 celery 是什么呢?
- celery 是一个灵活且可靠的,处理大量消息的分布式系统,可以在多个节点之间处理某个任务;
- celery 是一个专注于实时处理的任务队列,支持任务调度;
- celery 是开源的,有很多的使用者;
- celery 完全基于 Python 语言编写;
所以 celery 本质上就是一个任务调度框架,类似于 Apache 的 airflow,当然 airflow 也是基于 Python 语言编写。
不过有一点需要注意,celery 是用来调度任务的,但它本身并不具备存储任务的功能,而调度任务的时候肯定是要把任务存起来的。因此要使用 celery 的话,还需要搭配一些具备存储、访问功能的工具,比如:消息队列、Redis缓存、数据库等等。官方推荐的是消息队列 RabbitMQ,个人认为有些时候使用 Redis 也是不错的选择,当然我们都会介绍。
那么 celery 都可以在哪些场景中使用呢?
- 异步任务:一些耗时的操作可以交给celery异步执行,而不用等着程序处理完才知道结果。比如:视频转码、邮件发送、消息推送等等;
- 定时任务:比如定时推送消息、定时爬取数据、定时统计数据等等;
celery 的架构
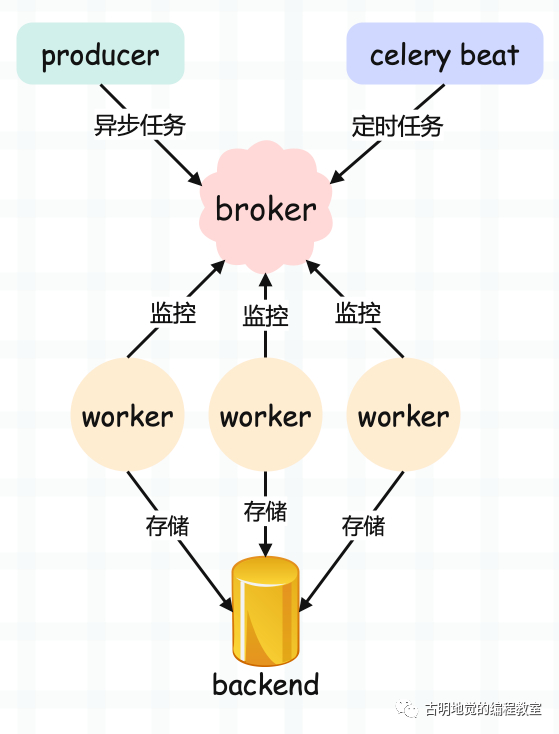
我们看一下 celery 的架构:
- producer:生产者,专门用来生产任务(task);
- celery beat:任务调度器,调度器进程会读取配置文件的内容,周期性地将配置文件里面到期需要执行的任务发送给消息队列,说白了就是生产定时任务;
- broker:任务队列,用于存放生产者和调度器生产的任务。一般使用消息队列或者 Redis 来存储,当然具有存储功能的数据库也是可以的。这一部分是 celery 所不提供的,需要依赖第三方。作用就是接收任务,存进队列;
- worker:任务的执行单元,会将任务从队列中顺序取出并执行;
- backend:用于在任务结束之后保存状态信息和结果,以便查询,一般是数据库,当然只要具备存储功能都可以作为 backend;
下面我们来安装 celery,安装比较简单,直接 pip install celery 即可。这里我本地的 celery 版本是 5.2.7,Python 版本是 3.8.10。
另外,由于 celery 本身不提供任务存储的功能,所以这里我们使用 Redis 作为消息队列,负责存储任务。因此你还要在机器上安装 Redis,我这里有一台云服务器,已经安装好了。
后续 celery 就会将任务存到 broker 里面,当然要想实现这一点,就必须还要有能够操作相应 broker 的驱动。Python 操作 Redis 的驱动也叫 redis,操作 RabbitMQ 的驱动叫 pika,直接 pip install ... 安装即可。
celery 实现异步任务
我们新建一个工程,就叫 celery_demo,然后在里面新建一个 app.py 文件。
# 文件名:app.py
import time
# 这个 Celery 就类似于 flask.Flask
# 然后实例化得到一个app
from celery import Celery
# 指定一个 name、以及 broker 的地址、backend 的地址
app = Celery(
"satori",
# 这里使用我服务器上的 Redis
# broker 用 1 号库, backend 用 2 号库
broker="redis://:maverick@82.157.146.194:6379/1",
backend="redis://:maverick@82.157.146.194:6379/2")
# 这里通过 @app.task 对函数进行装饰
# 那么之后我们便可调用 task.delay 创建一个任务
.task
def task(name, age):
print("准备执行任务啦")
time.sleep(3)
return f"name is {name}, age is {age}"- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
我们说执行任务的对象是 worker,那么我们是不是需要创建一个 worker 呢?显然是需要的,而创建 worker 可以使用如下命令创建:

注意:在 5.0 之前我们可以写成 celery worker -A app ...,也就是把所有的参数都放在子命令 celery worker 的后面。但从 5.0 开始这种做法就不允许了,必须写成 celery -A app worker ...,因为 -A 变成了一个全局参数,所以它不应该放在 worker 的后面,而是要放在 worker 的前面。
下面执行该命令:
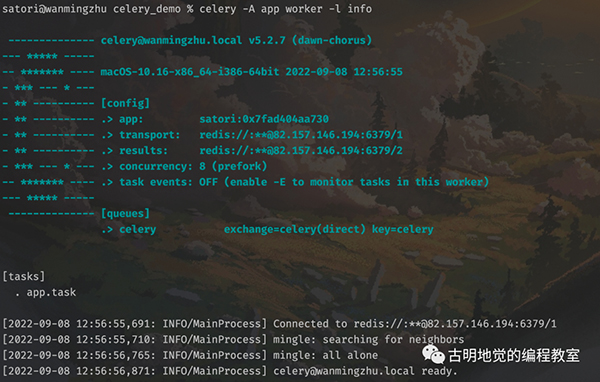
以上就前台启动了一个 worker,正在等待从队列中获取任务,图中也显示了相应的信息。然而此时队列中并没有任务,所以我们需要在另一个文件中创建任务并发送到队列里面去。
import time
from app import task
# 从 app 导入 task, 创建任务, 但是注意: 不要直接调用 task
# 因为那样的话就在本地执行了, 我们的目的是将任务发送到队列里面去
# 然后让监听队列的 worker 从队列里面取任务并执行
# 而 task 被 @app.task 装饰, 所以它不再是原来的 task 了
# 我们需要调用它的 delay 方法
# 调用 delay 之后, 就会创建一个任务
# 然后发送到队列里面去, 也就是我们这里的 Redis
# 至于参数, 普通调用的时候怎么传, 在 delay 里面依旧怎么传
start = time.perf_counter()
task.delay("古明地觉", 17)
print(
time.perf_counter() - start
) # 0.11716766700000003- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
然后执行该文件,发现只用了 0.12 秒,而 task 里面明明 sleep 了 3 秒。所以说明这一步是不会阻塞的,调用 task.delay 只是创建一个任务并发送至队列。我们再看一下 worker 的输出信息:

可以看到任务已经被消费者接收并且消费了,而且调用 delay 方法是不会阻塞的,花费的那 0.12 秒是用在了其它地方,比如连接 Redis 发送任务等等。
另外需要注意,函数被 @app.task 装饰之后,可以理解为它就变成了一个任务工厂,因为被装饰了嘛,然后调用任务工厂的 delay 方法即可创建任务并发送到队列里面。我们也可以创建很多个任务工厂,但是这些任务工厂必须要让 worker 知道,否则不会生效。所以如果修改了某个任务工厂、或者添加、删除了某个任务工厂,那么一定要让 worker 知道,而做法就是先停止 celery worker 进程,然后再重新启动。
如果我们新建了一个任务工厂,然后在没有重启 worker 的情况下,就用调用它的 delay 方法创建任务、并发送到队列的话,那么会抛出一个 KeyError,提示找不到相应的任务工厂。
- 其实很好理解,因为代码已经加载到内存里面了,光修改了源文件而不重启是没用的。因为加载到内存里面的还是原来的代码,不是修改过后的。
然后我们再来看看 Redis 中存储的信息,1 号库用作 broker,负责存储任务;2 号库用作 backend,负责存储执行结果。我们来看 2 号库:
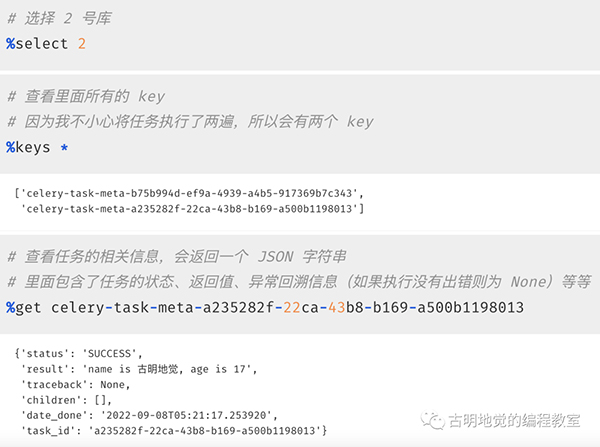
以上我们就启动了一个 worker 并成功消费了队列中的任务,并且还从 Redis 里面拿到了执行信息。当然啦,如果只能通过查询 backend 才能拿到信息的话,那 celery 就太不智能了。我们也可以直接从程序中获取。
直接查询任务执行信息
Redis(backend)里面存储了很多关于任务的信息,这些信息我们可以直接在程序中获取。
from app import task
res = task.delay("古明地觉", 17)
print(type(res))
"""
<class 'celery.result.AsyncResult'>
"""
# 直接打印,显示任务的 id
print(res)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取状态, 显然此刻没有执行完
# 因此结果是PENDING, 表示等待状态
print(res.status)
"""
PENDING
"""
# 获取 id,两种方式均可
print(res.task_id)
print(res.id)
"""
4bd48a6d-1f0e-45d6-a225-6884067253c3
4bd48a6d-1f0e-45d6-a225-6884067253c3
"""
# 获取任务执行结束时的时间
# 任务还没有结束, 所以返回None
print(res.date_done)
"""
None
"""
# 获取任务的返回值, 可以通过 result 或者 get()
# 注意: 如果是 result, 那么任务还没有执行完的话会直接返回 None
# 如果是 get(), 那么会阻塞直到任务完成
print(res.result)
print(res.get())
"""
None
name is 古明地觉, age is 17
"""
# 再次查看状态和执行结束时的时间
# 发现 status 变成SUCCESS
# date_done 变成了执行结束时的时间
print(res.status)
# 但显示的是 UTC 时间
print(res.date_done)
"""
SUCCESS
2022-09-08 06:40:34.525492
"""- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
另外我们说结果需要存储在 backend 中,如果没有配置 backend,那么获取结果的时候会报错。至于 backend,因为它是存储结果的,所以一般会保存在数据库中,因为要持久化。我这里为了方便,就还是保存在 Redis 中。
celery.result.AsyncResult 对象
调用完任务工厂的 delay 方法之后,会创建一个任务并发送至队列,同时返回一个 AsyncResult 对象,基于此对象我们可以拿到任务执行时的所有信息。但是 AsyncResult 对象我们也可以手动构造,举个例子:
import time
# 我们不光要导入 task, 还要导入里面的 app
from app import app, task
# 导入 AsyncResult 这个类
from celery.result import AsyncResult
# 发送任务到队列当中
res = task.delay("古明地觉", 17)
# 传入任务的 id 和 app, 创建 AsyncResult 对象
async_result = AsyncResult(res.id, app=app)
# 此时的这个 res 和 async_result 之间是等价的
# 两者都是 AsyncResult 对象, 它们所拥有的方法也是一样的
# 下面用谁都可以
while True:
# 等价于async_result.state == "SUCCESS"
if async_result.successful():
print(async_result.get())
break
# 等价于async_result.state == "FAILURE"
elif async_result.failed():
print("任务执行失败")
elif async_result.status == "PENDING":
print("任务正在被执行")
elif async_result.status == "RETRY":
print("任务执行异常正在重试")
elif async_result.status == "REJECTED":
print("任务被拒绝接收")
elif async_result.status == "REVOKED":
print("任务被取消")
else:
print("其它的一些状态")
time.sleep(0.8)
"""
任务正在被执行
任务正在被执行
任务正在被执行
任务正在被执行
name is 古明地觉, age is 17
"""- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
以上就是任务可能出现的一些状态,通过轮询的方式,我们也可以查看任务是否已经执行完毕。当然 AsyncResult 还有一些别的方法,我们来看一下:
from app import task
res = task.delay("古明地觉", 17)
# 1. ready():查看任务状态,返回布尔值。
# 任务执行完成返回 True,否则为 False
# 那么问题来了,它和 successful() 有什么区别呢?
# successful() 是在任务执行成功之后返回 True, 否则返回 False
# 而 ready() 只要是任务没有处于阻塞状态就会返回 True
# 比如执行成功、执行失败、被 worker 拒收都看做是已经 ready 了
print(res.ready())
"""
False
"""
# 2. wait():和之前的 get 一样, 因为在源码中写了: wait = get
# 所以调用哪个都可以, 不过 wait 可能会被移除,建议直接用 get 就行
print(res.wait())
print(res.get())
"""
name is 古明地觉, age is 17
name is 古明地觉, age is 17
"""
# 3. trackback:如果任务抛出了一个异常,可以获取原始的回溯信息
# 执行成功就是 None
print(res.traceback)
"""
None
"""- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
以上就是获取任务执行结果相关的部分。
celery 的配置
celery 的配置不同,所表现出来的性能也不同,比如序列化的方式、连接队列的方式,单线程、多线程、多进程等等。那么 celery 都有那些配置呢?
- broker_url:broker 的地址,就是类 Celery 里面传入的 broker 参数。
- result_backend:存储结果地址,就是类 Celery 里面传入的 backend 参数。
- task_serializer:任务序列化方式,支持以下几种:
- binary:二进制序列化方式,pickle 模块默认的序列化方法;
- json:支持多种语言,可解决多语言的问题,但通用性不高;
- xml:标签语言,和 json 定位相似;
- msgpack:二进制的类 json 序列化,但比 json 更小、更快;
- yaml:表达能力更强、支持的类型更多,但是在 Python里面的性能不如 json;
- 根据情况,选择合适的类型。如果不是跨语言的话,直接选择 binary 即可,默认是 json。
- result_serializer:任务执行结果序列化方式,支持的方式和任务序列化方式一致。
- result_expires:任务结果的过期时间,单位是秒。
- accept_content:指定任务接受的内容序列化类型(序列化),一个列表,比如:["msgpack", "binary", "json"]。
- timezone:时区,默认是 UTC 时区。
- enable_utc:是否开启 UTC 时区,默认为 True;如果为 False,则使用本地时区。
- task_publish_retry:发送消息失败时是否重试,默认为 True。
- worker_concurrency:并发的 worker 数量。
- worker_prefetch_multiplier:每次 worker 从任务队列中获取的任务数量。
- worker_max_tasks_per_child:每个 worker 执行多少次就会被杀掉,默认是无限的。
- task_time_limit:单个任务执行的最大时间,单位是秒。
- task_default_queue :设置默认的队列名称,如果一个消息不符合其它的队列规则,就会放在默认队列里面。如果什么都不设置的话,数据都会发送到默认的队列中。
- task_queues :设置详细的队列
# 将 RabbitMQ 作为 broker 时需要使用
task_queues = {
# 这是指定的默认队列
"default": {
"exchange": "default",
"exchange_type": "direct",
"routing_key": "default"
},
# 凡是 topic 开头的 routing key
# 都会被放到这个队列
"topicqueue": {
"routing_key": "topic.#",
"exchange": "topic_exchange",
"exchange_type": "topic",
},
"task_eeg": { # 设置扇形交换机
"exchange": "tasks",
"exchange_type": "fanout",
"binding_key": "tasks",
},
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
celery 的配置非常多,不止我们上面说的那些,更多配置可以查看官网,写的比较详细。
- https://docs.celeryq.dev/en/latest/userguide/configuration.html#general-settings
值得一提的是,在 5.0 之前配置项都是大写的,而从 5.0 开始配置项改成小写了。不过老的写法目前仍然支持,只是启动的时候会抛警告,并且在 6.0 的时候不再兼容老的写法。
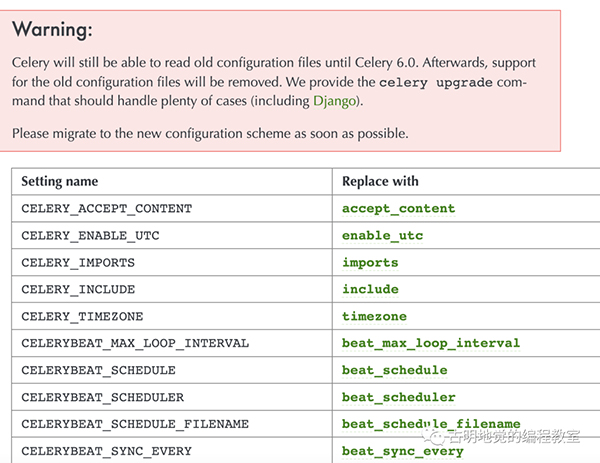
官网也很贴心地将老版本的配置和新版本的配置罗列了出来,尽管配置有很多,但并不是每一个都要用,可以根据自身的业务合理选择。
然后下面我们就根据配置文件的方式启动 celery,当前目录结构如下:
celery_demo/config.py
broker_url = "redis://:maverick@82.157.146.194:6379/1"
result_backend = "redis://:maverick@82.157.146.194:6379"
# 写俩就完事了- 1.
- 2.
- 3.
celery_demo/tasks/task1.py
celery 可以支持非常多的定时任务,而不同种类的定时任务我们一般都会写在不同的模块中(当然这里目前只有一个),然后再将这些模块组织在一个单独的目录中。
当前只有一个 task1.py,我们随便往里面写点东西,当然你也可以创建更多的文件。
def add(x, y):
return x + y
def sub(x, y):
return x - y
def mul(x, y):
return x * y
def div(x, y):
return x / y- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
celery_demo/app.py
from celery import Celery
import config
from tasks.task1 import (
add, sub, mul, div
)
# 指定一个 name 即可
app = Celery("satori")
# 其它参数通过加载配置文件的方式指定
# 和 flask 非常类似
app.config_from_object(config)
# 创建任务工厂,有了任务工厂才能创建任务
# 这种方式和装饰器的方式是等价的
add = app.task(add)
sub = app.task(sub)
mul = app.task(mul)
div = app.task(div)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
然后重新启动 worker:
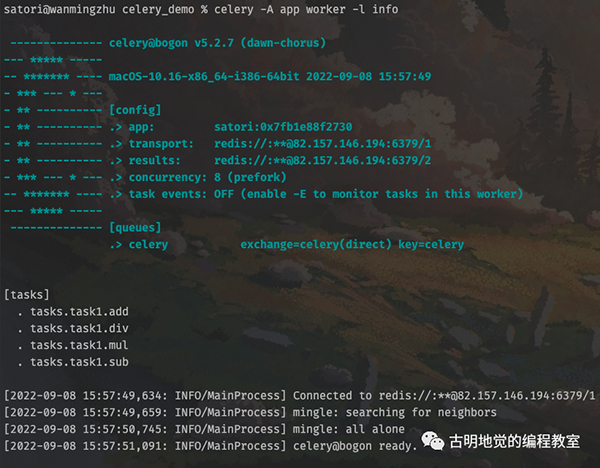
输出结果显示,任务工厂都已经被加载进来了,然后我们创建任务并发送至队列。
# 在 celery_demo 目录下
# 将 app.py 里面的任务工厂导入进来
>>> from app import add, sub, mul, div
# 然后创建任务发送至队列,并等待结果
>>> add.delay(3, 4).get()
7
>>> sub.delay(3, 4).get()
-1
>>> mul.delay(3, 4).get()
12
>>> div.delay(3, 4).get()
0.75
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
结果正常返回了,再来看看 worker 的输出,
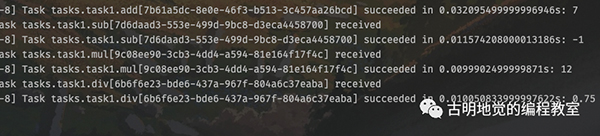
多个任务都被执行了。
发送任务时指定参数
我们在发送任务到队列的时候,使用的是 delay 方法,里面直接传递函数所需的参数即可,那么除了函数需要的参数之外,还有没有其它参数呢?
首先 delay 方法实际上是调用的 apply_async 方法,并且 delay 方法里面只接收函数的参数,但是 apply_async 接收的参数就很多了,我们先来看看它们的函数原型:

delay 方法的 *args 和 **kwargs 就是函数的参数,它会传递给 apply_async 的 args 和 kwargs。而其它的参数就是发送任务时所设置的一些参数,我们这里重点介绍一下 apply_async 的其它参数。
- countdown:倒计时,表示任务延迟多少秒之后再执行,参数为整型;
- eta:任务的开始时间,datetime 类型,如果指定了 countdown,那么这个参数就不应该再指定;
- expires:datetime 或者整型,如果到规定时间、或者未来的多少秒之内,任务还没有发送到队列被 worker 执行,那么该任务将被丢弃;
- shadow:重新指定任务的名称,覆盖 app.py 创建任务时日志上所指定的名字;
- retry:任务失败之后是否重试,bool 类型;
- retry_policy:重试所采用的策略,如果指定这个参数,那么 retry 必须要为 True。参数类型是一个字典,里面参数如下:
- max_retries : 最大重试次数,默认为 3 次;
- interval_start : 重试等待的时间间隔秒数,默认为 0,表示直接重试不等待;
- interval_step : 每次重试让重试间隔增加的秒数,可以是数字或浮点数,默认为 0.2;
- interval_max : 重试间隔最大的秒数,即通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数;
- routing_key:自定义路由键,针对 RabbitMQ;
- queue:指定发送到哪个队列,针对 RabbitMQ;
- exchange:指定发送到哪个交换机,针对 RabbitMQ;
- priority:任务队列的优先级,0-9 之间,对于 RabbitMQ 而言,0是最高级;
- serializer:任务序列化方法,通常不设置;
- compression:压缩方案,通常有zlib、bzip2;
- headers:为任务添加额外的消息头;
- link:任务成功执行后的回调方法,是一个signature对象,可以用作关联任务;
- link_error: 任务失败后的回调方法,是一个signature对象;
我们随便挑几个举例说明:
>>> from app import add
# 使用 apply_async,要注意参数的传递
# 位置参数使用元组或者列表,关键字参数使用字典
# 因为是args和kwargs, 不是 *args和 **kwargs
>>> add.apply_async([3], {"y": 4},
... task_id="恋恋",
... countdown=5).get()
7
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
查看一下 worker 的输出:

注意左边的时间,16:25:16 收到的消息,但 5 秒后才执行完毕,因为我们将 countdown 参数设置为 5。并且任务的 id 也被我们修改了。
另外还需要注意一下那些接收时间的参数,比如 eta。如果我们手动指定了eta,那么一定要注意时区的问题,要保证 celery 所使用的时区和你传递的 datetime 的时区是统一的。
其它的参数可以自己手动测试一下,这里不细说了,根据自身的业务选择合适的参数即可。
创建任务工厂的另一种方式
之前在创建任务工厂的时候,是将函数导入到 app.py 中,然后通过 add = app.task(add) 的方式手动装饰,因为有哪些任务工厂必须要让 worker 知道,所以一定要在 app.py 里面出现。但是这显然不够优雅,那么可不可以这么做呢?
# celery_demo/tasks/task1.py
from app import app
# celery_demo 所在路径位于 sys.path 中
# 因此这里可以直接 from app import app
.task
def add(x, y):
return x + y
.task
def sub(x, y):
return x - y
# celery_demo/app.py
from tasks.task1 import add, sub- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
按照上面这种做法,理想上可以,但现实不行,因为会发生循环导入。
所以 celery 提供了一个办法,我们依旧在 task1.py 中 import app,但在 app.py 中不再使用 import,而是通过 include 加载的方式,我们看一下:
# celery_demo/tasks/task1.py
from app import app
.task
def add(x, y):
return x + y
.task
def sub(x, y):
return x - y
# celery_demo/app.py
from celery import Celery
import config
# 通过 include 指定存放任务的 py 文件
# 注意它和 worker 启动路径之间的关系
# 我们是在 celery_demo 目录下启动的 worker
# 所以应该写成 "tasks.task1"
# 如果是在 celery_demo 的上一级目录启动 worker
# 那么这里就要指定为 "celery_demo.tasks.task1"
# 当然启动时的 -A app 也要换成 -A celery_demo.app
app = Celery(__name__, include=["tasks.task1"])
# 如果还有其它文件,比如 task2.py, task3.py
# 那么就把 "tasks.task2", "tasks.task3" 加进去
app.config_from_object(config)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
在 celery_demo 目录下重新启动 worker。
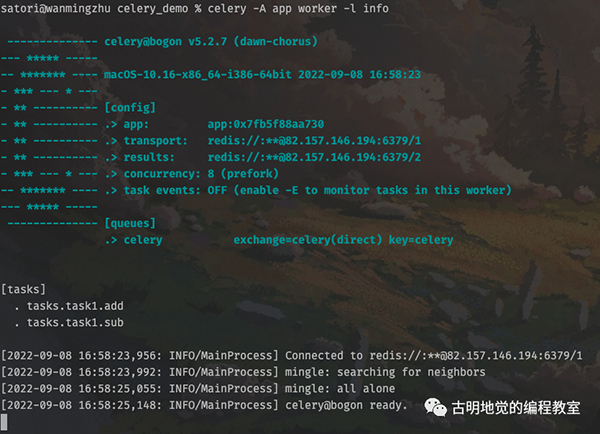
为了方便,我们只保留了两个任务工厂。可以看到此时就成功启动了,并且也更加方便和优雅一些。之前是在 task1.py 中定义函数,然后再把 task1.py 中的函数导入到 app.py 里面,然后手动进行装饰。虽然这么做是没问题的,但很明显这种做法不适合管理。
所以还是要将 app.py 中的 app 导入到 task1.py 中直接创建任务工厂,但如果再将 task1.py 中的任务工厂导入到 app.py 中就会发生循环导入。于是 celery 提供了一个 include 参数,可以在创建 app 的时候自动将里面所有的任务工厂加载进来,然后启动并告诉 worker。
我们来测试一下:
# 通过 tasks.task1 导入任务工厂
# 然后创建任务,发送至队列
>>> from tasks.task1 import add, sub
>>> add.delay(11, 22).get()
33
>>> sub.delay(11, 22).get()
-11
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
查看一下 worker 的输出:

结果一切正常。
Task 对象
我们之前通过对一个函数使用 @app.task 即可将其变成一个任务工厂,而这个任务工厂就是一个 Task 实例对象。而我们在使用 @app.task 的时候,其实是可以加上很多的参数的,常用参数如下:
name:默认的任务名是一个uuid,我们可以通过 name 参数指定任务名,当然这个 name 就是 apply_async 的参数 name。如果在 apply_async 中指定了,那么以 apply_async 指定的为准;
- bind:一个 bool 值,表示是否和任务工厂进行绑定。如果绑定,任务工厂会作为参数传递到方法中;
- base:定义任务的基类,用于定义回调函数,当任务到达某个状态时触发不同的回调函数,默认是 Task,所以我们一般会自己写一个类然后继承 Task;
- default_retry_delay:设置该任务重试的延迟机制,当任务执行失败后,会自动重试,单位是秒,默认是3分钟;
- serializer:指定序列化的方法;
当然 app.task 还有很多不常用的参数,这里就不说了,有兴趣可以去查看官网或源码,我们演示一下几个常用的参数:
# celery_demo/tasks/task1.py
from app import app
.task(name="你好")
def add(x, y):
return x + y
.task(name="我不好", bind=True)
def sub(self, x, y):
"""
如果 bind=True,则需要多指定一个 self
这个 self 就是对应的任务工厂
"""
# self.request 是一个 celery.task.Context 对象
# 获取它的属性字典,即可拿到该任务的所有属性
print(self.request.__dict__)
return x - y- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
其它代码不变,我们重新启动 worker:
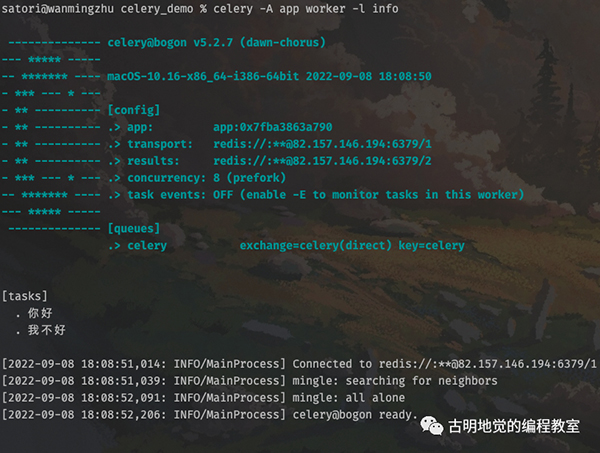
然后创建任务发送至队列,再由 worker 取出执行:
>>> from tasks.task1 import add, sub
>>> add.delay(111, 222).get()
333
>>> sub.delay(111, 222).get()
-111
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
执行没有问题,然后看看 worker 的输出:
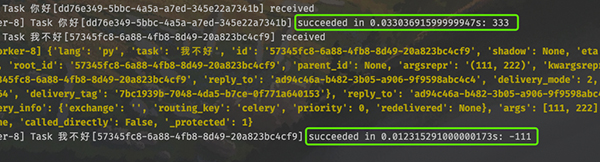
创建任务工厂时,如果指定了 bind=True,那么执行任务时会将任务工厂本身作为第一个参数传过去。任务工厂本质上就是 Task 实例对象,调用它的 delay 方法即可创建任务。
所以如果我们在 sub 内部继续调用 self.delay(11, 22),会有什么后果呢?没错,worker 会进入无限递归。因为执行任务的时候,在任务的内部又创建了任务,所以会死循环下去。
当然 self 还有很多其它属性和方法,具体有哪些可以通过 Task 这个类来查看。这里面比较重要的是 self.request,它包含了某个具体任务的相关信息,而且信息非常多。
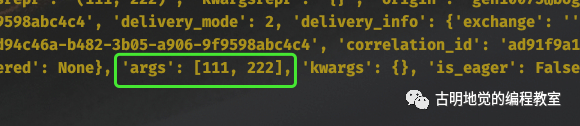
比如当前传递的参数是什么,就可以通过 self.request 拿到。当然啦,self.request 是一个 Context 对象,因为不同任务获取 self.request 的结果肯定是不同的,但 self(任务工厂)却只有一个,所以要基于 Context 进行隔离。
我们可以通过 __dict__ 拿到 Context 对象的属性字典,然后再进行操作。
最后再来说一说 @app.task 里面的 base 参数。
# celery_demo/tasks/task1.py
from celery import app
from app import Task
class MyTask(Task):
"""
自定义一个类,继承自celery.Task
exc: 失败时的错误的类型;
task_id: 任务的id;
args: 任务函数的位置参数;
kwargs: 任务函数的关键字参数;
einfo: 失败时的异常详细信息;
retval: 任务成功执行的返回值;
"""
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""任务失败时执行"""
def on_success(self, retval, task_id, args, kwargs):
"""任务成功时执行"""
print("任务执行成功")
def on_retry(self, exc, task_id, args, kwargs, einfo):
"""任务重试时执行"""
# 使用 @app.task 的时候,指定 base 即可
# 然后任务在执行的时候,会触发 MyTask 里面的回调函数
.task(name="地灵殿", base=MyTask)
def add(x, y):
print("加法计算")
return x + y- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
重新启动 worker,然后创建任务。

指定了 base,任务在执行的时候会根据执行状态的不同,触发 MyTask 里面的不同方法。
自定义任务流
有时候我们也可以将执行的多个任务,划分到一个组中。
# celery_demo/tasks/task1.py
from app import app
.task()
def add(x, y):
print("加法计算")
return x + y
.task()
def sub(x, y):
print("减法计算")
return x - y
.task()
def mul(x, y):
print("乘法计算")
return x * y
.task()
def div(x, y):
print("除法计算")
return x // y- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
老规矩,重启 worker,因为我们修改了任务工厂。
然后来导入它们,创建任务,并将这些任务划分到一个组中。
>>> from tasks.task1 import add, sub, mul, div
>>> from celery import group
# 调用 signature 方法,得到 signature 对象
# 此时 t1.delay() 和 add.delay(2, 3) 是等价的
>>> t1 = add.signature(args=(2, 3))
>>> t2 = sub.signature(args=(2, 3))
>>> t3 = mul.signature(args=(2, 3))
>>> t4 = div.signature(args=(4, 2))
# 但是变成 signature 对象之后,
# 我们可以将其放到一个组里面
>>> gp = group(t1, t2, t3, t4)
# 执行组任务
# 返回 celery.result.GroupResult 对象
>>> res = gp()
# 每个组也有一个唯一 id
>>> print("组id:", res.id)
组id: 65f32cc4-b8ce-4bf8-916b-f5cc359a901a
# 调用 get 方法也会阻塞,知道组里面任务全部完成
>>> print("组结果:", res.get())
组结果: [5, -1, 6, 2]
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
可以看到整个组也是有唯一 id 的,另外 signature 也可以写成 subtask 或者 s,在源码里面这几个是等价的。
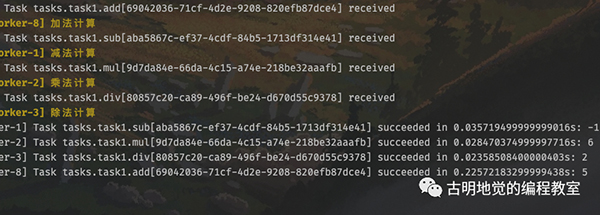
我们观察一下 worker 的输出,任务是并发执行的,所以哪个先完成不好说。但是调用组的 get 方法时,里面的返回值顺序一定和任务添加时候的顺序保持一致。
除此之外,celery 还支持将多个任务像链子一样串起来,第一个任务的输出会作为第二个任务的输入,传递给下一个任务的第一个参数。
# celery_demo/tasks/task1.py
from app import app
.task
def task1():
l = []
return l
.task
# task1 的返回值会传递给这里的 task1_return
def task2(task1_return, value):
task1_return.append(value)
return task1_return
.task
# task2 的返回值会传递给这里的 task2_return
def task3(task2_return, num):
return [i + num for i in task2_return]
.task
# task3 的返回值会传递给这里的 task3_return
def task4(task3_return):
return sum(task3_return)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
然后我们看怎么将这些任务像链子一样串起来。
>>> from tasks.task1 import *
>>> from celery import chain
# 将多个 signature 对象进行与运算
# 当然内部肯定重写了 __or__ 这个魔法方法
>>> my_chain = chain(
... task1.s() | task2.s(123) | task3.s(5) | task4.s())
>>>
# 执行任务链
>>> res = my_chain()
# 获取返回值
>>> print(res.get())
128
>>>- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
这种链式处理的场景非常常见,比如 MapReduce。
celery 实现定时任务
既然是定时任务,那么就意味着 worker 要后台启动,否则一旦远程连接断开,就停掉了。因此 celery 是支持我们后台启动的,并且可以启动多个。
# 启动 worker
celery multi start w1 -A app -l info
# 可以同时启动多个
celery multi start w2 w3 -A app -l info
# 以上我们就启动了 3 个 worker
# 如果想停止的话
celery multi stop w1 w2 w3 -A app -l info- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
但是注意,这种启动方式在 Windows 上面不支持,因为 celery 会默认创建两个目录,分别是 /var/log/celery 和 /var/run/celery,显然这是类 Unix 系统的目录结构。
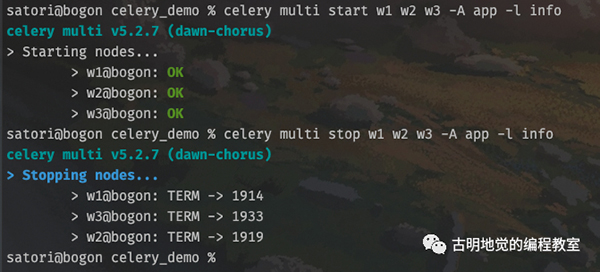
显然启动和关闭是没有问题的,不过为了更好地观察到输出,我们还是用之前的方式,选择前台启动。
然后回顾一下 celery 的架构,里面除了 producer 之外还有一个 celery beat,也就是调度器。我们调用任务工厂的 delay 方法,手动将任务发送到队列,此时就相当于 producer。如果是设置定时任务,那么会由调度器自动将任务添加到队列。
我们在 tasks 目录里面再创建一个 period_task1.py 文件。
# celery_demo/tasks/period_task1.py
from celery.schedules import crontab
from app import app
from .task1 import task1, task2, task3, task4
.on_after_configure.connect
def period_task(sender, **kwargs):
# 第一个参数为 schedule,可以是 float,或者 crontab
# crontab 后面会说,第二个参数是任务,第三个参数是名字
sender.add_periodic_task(10.0, task1.s(),
name="每10秒执行一次")
sender.add_periodic_task(15.0, task2.s("task2"),
name="每15秒执行一次")
sender.add_periodic_task(20.0, task3.s(),
name="每20秒执行一次")
sender.add_periodic_task(
crontab(hour=18, minute=5, day_of_week=0),
task4.s("task4"),
name="每个星期天的18:05运行一次"
)
# celery_demo/tasks/task1.py
from app import app
.task
def task1():
print("我是task1")
return "task1你好"
.task
def task2(name):
print(f"我是{name}")
return f"{name}你好"
.task
def task3():
print("我是task3")
return "task3你好"
.task
def task4(name):
print(f"我是{name}")
return f"{name}你好"- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
既然使用了定时任务,那么一定要设置时区。
# celery_demo/config.py
broker_url = "redis://:maverick@82.157.146.194:6379/1"
result_backend = "redis://:maverick@82.157.146.194:6379/2"
# 之前说过,celery 默认使用 utc 时间
# 其实我们是可以手动禁用的,然后手动指定时区
enable_utc = False
timezone = "Asia/Shanghai"- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
最后是修改 app.py,将定时任务加进去。
from celery import Celery
import config
app = Celery(
__name__,
include=["tasks.task1", "tasks.period_task1"])
app.config_from_object(config)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
下面就来启动任务,先来启动 worker,生产上应该后台启动,这里为了看到信息,选择前台启动。
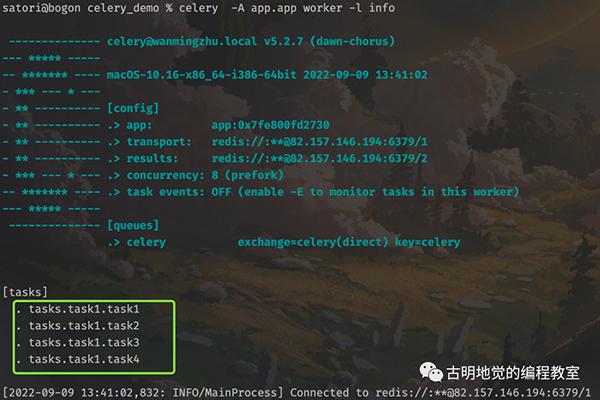
tasks.task1 里面的 4 个任务工厂都被添加进来了,然后再来启动调度器。
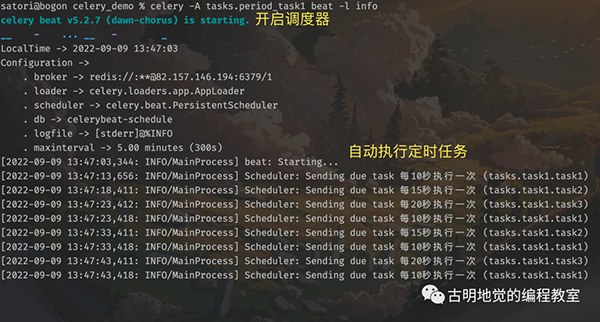
调度器启动之后会自动检测定时任务,如果到时间了,就发送到队列。而启动调度器的命令如下:

根据调度器的输出内容,我们知道定时任务执行完了,但很明显定时任务本质上也是任务,只不过有定时功能,但也要发到队列里面。然后 worker 从队列里面取出任务,并执行,那么 worker 必然会有信息输出。
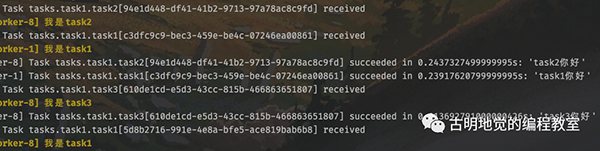
调度器启动到现在已经有一段时间了,worker 在终端中输出了非常多的信息。
此时我们就成功实现了定时任务,并且是通过定义函数、打上装饰器的方式实现的。除此之外,我们还可以通过配置的方式实现。
# celery_demo/tasks/period_task1.py
from celery.schedules import crontab
from app import app
# 此时也不需显式导入任务工厂了
# 直接以字符串的方式指定即可
app.conf.beat_schedule = {
# 参数通过 args 和 kwargs 指定
"每10秒执行一次": {"task": "tasks.task1.task1",
"schedule": 10.0},
"每15秒执行一次": {"task": "tasks.task1.task2",
"schedule": 15.0,
"args": ("task2",)},
"每20秒执行一次": {"task": "tasks.task1.task3",
"schedule": 20.0},
"每个星期天的18:05运行一次": {"task": "tasks.task1.task4",
"schedule": crontab(hour=18,
minute=5,
day_of_week=0),
"args": ("task4",)}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
需要注意:虽然我们不用显式导入任务工厂,但其实是 celery 自动帮我们导入。由于这些任务工厂都位于 celery_demo/tasks/task1.py 里面,而 worker 也是在 celery_demo 目录下启动的,所以需要指定为 tasks.task1.task{1234}。
这种启动方式也是可以成功的,貌似还更方便一些,但是会多出一个文件,用来存储配置信息。
crontab 参数
定时任务除了指定一个浮点数之外(表示每隔多少秒执行一次),还可以指定 crontab。关于 crontab 应该都知道是什么,我们在 Linux 上想启动定时任务的话,直接 crontab -e 然后添加即可。
而 celery 的 crontab 和 Linux 高度相似,我们看一下函数原型就知道了。
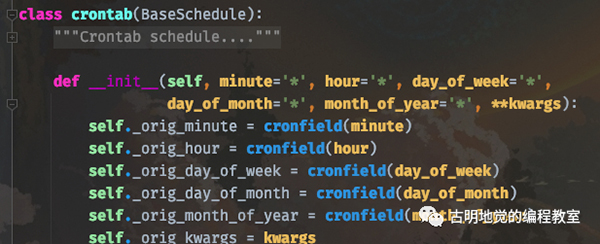
简单解释一下:
- minute:0-59,表示第几分钟触发,* 表示每分钟触发一次;
- hour:0-23,表示第几个小时触发,* 表示每小时都会触发。比如 minute=2, hour=*,表示每小时的第二分钟触发一次;
- day_of_week:0-6,表示一周的第几天触发,0 是星期天,1-6 分别是星期一到星期六,不习惯的话也可以用字符串 mon,tue,wed,thu,fri,sat,sun 表示;
- month_of_year:当前年份的第几个月;
以上就是这些参数的含义,并且参数接收的值还可以是一些特殊的通配符:
- *:所有,比如 minute=*,表示每分钟触发;
- */a:所有可被 a 整除的时候触发;
- a-b:a 到 b范围内触发;
- a-b/c:范围 a-b 且能够被 c 整除的时候触发;
- 2,10,40:比如 minute=2,10,40 表示第 2、10、40 分钟的时候触发;
通配符之间是可以自由组合的,比如 */3,8-17 就表示能被 3 整除,或范围处于 8-17 的时候触发。
除此之外,还可以根据天色来设置定时任务(有点离谱)。
from celery.schedules import solar
app.conf.beat_schedule = {
"日落": {"task": "task1",
"schedule": solar("sunset",
-37.81753,
144.96715)
},
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
solar 里面接收三个参数,分别是 event、lat、lon,后两个比较简单,表示观测者所在的纬度和经度。值大于 0,则对应东经/北纬,小于 0,则对应西经/南纬。
我们重点看第一个参数 event,可选值如下:
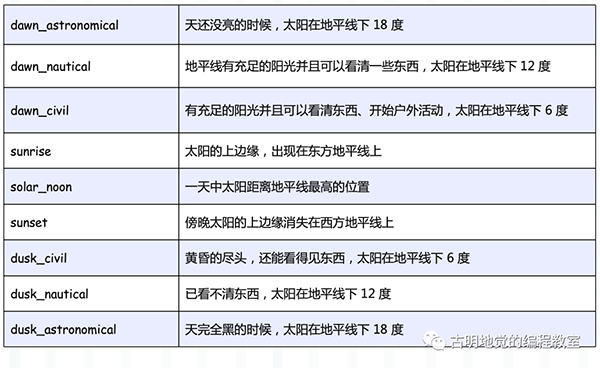
比如代码中的 "sunset", -37.81753, 144.96715 就表示,当站在南纬 37.81753、东经 144.96715 的地方观察,发现傍晚太阳的上边缘消失在西方地平线上的时候,触发任务执行。
个人觉得这个功能有点强悍,但估计绝大部分人应该都用不到,可能气象领域相关的会用的比较多。
小结
以上就是 celery 的使用,另外这里的 broker 和 backend 用的都是 Redis,其实还可以使用 RabbitMQ 和数据库。
broker_url = "amqp://admin:123456@82.157.146.194:5672//"
result_backend = "mysql+pymysql://root:123456@82.157.146.194:3306/store"- 1.
- 2.
可以自己测试一下,但不管用的是哪种存储介质,对于我们使用 celery 而言,都是没有区别的。
celery 在工作中用的还是比较多的,而且有一个调度工具 Apache airflow,它的核心调度功能也是基于 celery 实现的。



















