神经网络是一组应用于输入对象的输出的操作(层)。在计算机视觉中,输入对象是一张图片:一个大小为 [通道数X高度X宽度] 的张量,其中通道数通常为 3 (RGB)。中中间输出称为特征映射(feature map)。特征映射在某种意义上是相同的图片,只是通道数是任意的,张量的每个单元称为特征。为了能够在一次传递中同时运行多个图像,所有这些张量都有一个额外的维度,大小等于批处理中的对象数量。
互相关操作可以表示为沿着输入特征映射从核上滑动,就像在gif上一样。每次我们将一个核应用于一个输入,我们将相应的核权重与特征相乘并将它们相加,从而在输出通道中获得一个新特征。
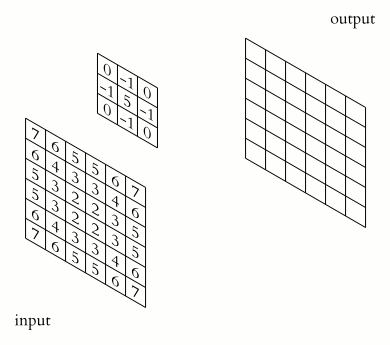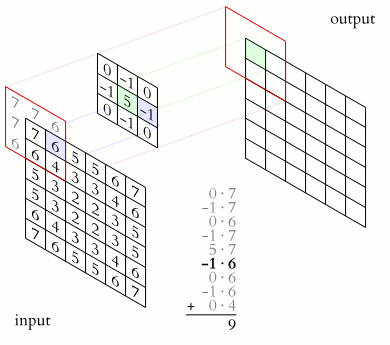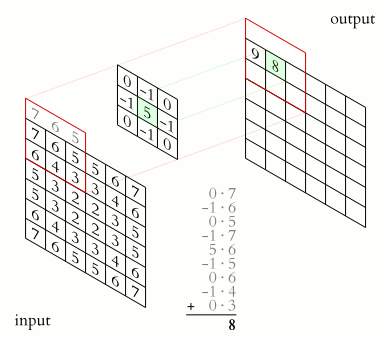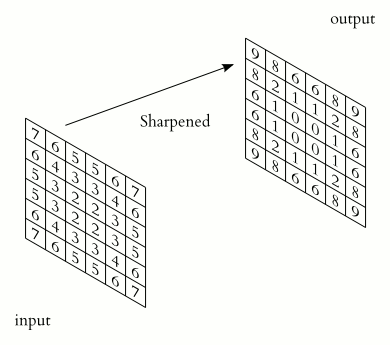
卷积几乎是一个互相关,在神经网络中,卷积从一组通道创建另一组通道。也就是说:上面描述的几个核一次存储在卷积层中,每个核生成一个通道,然后它们被连接起来。这种卷积的核的最终维度为:[每输出通道数X每输入通道数X核高X核宽]。
在PyTorch和许多其他机器学习框架中,卷积层的下一个部分是bias。偏差是每个输出通道的附加项。因此,偏差是一组参数,其大小等于输出通道的数量。
我们的任务是将两个卷积合并为一个卷积。简而言之,卷积和偏差加法都是线性运算,线性运算的组合也是一个线性运算。
让我们从最简单的情况开始。一个是任意大小的卷积,第二个是1x1的卷积。他们都没有bias。实际上,这意味着将特征映射乘以一个常数。你可以简单地把第一次卷积的权重值乘以这个常数。Python代码如下:
import torch
import numpy as np
conv1 = torch.nn.Conv2d(1, 1, (3, 3), bias=False) # [input channels X output channels X kernel shape]
conv2 = torch.nn.Conv2d(1, 1, (1, 1), bias=False) # 1х1 convolution. There will be only one weight in it's weights.
new_conv = torch.nn.Conv2d(1, 1, 3, bias=False) # This convolution will merge two
new_conv.weight.data = conv1.weight.data * conv2.weight.data
# Let's check
x = torch.randn([1, 1, 6, 6]) # [batch size X input channels X vertical size X horisontal size]
out = conv2(conv1(x))
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min()
现在让第一个卷积将任意数量的通道转换成另一个任意数量的通道。在这种情况下,我们的1x1卷积将是中间特征映射通道的加权和。这意味着你可以对产生这些通道的权重进行加权和。
conv1 = torch.nn.Conv2d(2, 3, (3, 3), bias=False) # [input channels X output channels X kernel shape]
conv2 = torch.nn.Conv2d(3, 1, (1, 1), bias=False) # 1х1 convolution. There will be only one weight in it's weights.
new_conv = torch.nn.Conv2d(2, 1, 3, bias=False) # As a result we want to get 1 channel
# The convolution weights: [output channels X input channels X kernel shape 1 X kernel shape 2]
# In order to multiply by the first dimension the weights responsible for creating each intermediate channel with their weight
# we will have to permute the dimensions of the second second convolution.
# Then we sum up the weighted weights and finish the measurement in order to successfully replace the weights.
new_conv.weight.data = (conv1.weight.data * conv2.weight.data.permute(1, 0, 2, 3)).sum(0)[None, ]
x = torch.randn([1, 2, 6, 6])
out = conv2(conv1(x))
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min()
现在让我们的两个卷积将任意数量的通道转换为另一个任意数量的通道。在本例中,我们的1x1卷积将是一组中间特征映射通道的加权和。这里的逻辑是一样的。需要将生成中间特征的权重与第二次卷积得到的权重相加。
conv1 = torch.nn.Conv2d(2, 3, 3, bias=False)
conv2 = torch.nn.Conv2d(3, 5, 1, bias=False)
new_conv = torch.nn.Conv2d(1, 5, 3, bias=False) # Curios face:
# It doesn't matter what sizes to pass during initialization.
# Replacing the weights will fix everything.
# The magic of the broadcast in action. It was possible to do this in the previous example, but something should change.
new_conv.weight.data = (conv2.weight.data[…, None] * conv1.weight.data[None]).sum(1)
x = torch.randn([1, 2, 6, 6])
out = conv2(conv1(x))
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min()
现在,是时候放弃对第二个卷积大小的限制了。为简化起见,让我们看一下一维卷积。核2中的“k”操作会是什么样子呢?
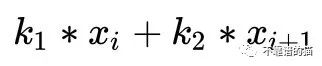
让我们添加额外的卷积v,核大小为2:
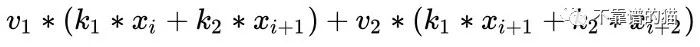
改写方程:
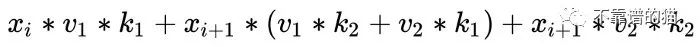
最后:
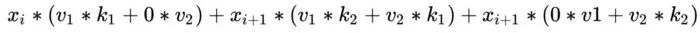
结果是与核3的卷积。这个卷积中的核是应用于第一个卷积的填充权重与第二个卷积的权重创建的核的互相关的结果。
对于其他大小的核、二维情况和多通道情况,相同的逻辑也适用。Python示例代码如下:
kernel_size_1 = np.array([3, 3])
kernel_size_2 = np.array([3, 5])
kernel_size_merged = kernel_size_1 + kernel_size_2–1
conv1 = torch.nn.Conv2d(2, 3, kernel_size_1, bias=False)
conv2 = torch.nn.Conv2d(3, 5, kernel_size_2, bias=False)
new_conv = torch.nn.Conv2d(2, 5, kernel_size_merged, bias=False)
# Calculation how many zeros we need to pad after first convolution
# Padding meand how many zeros we need to add by verical and horizontal
padding = [kernel_size_2[0]-1, kernel_size_2[1]-1]
new_conv.weight.data = torch.conv2d(conv1.weight.data.permute(1, 0, 2, 3), # We allready saw this.
conv2.weight.data.flip(-1, -2), # This is done to make a cross-correlation from convolution.
padding=padding).permute(1, 0, 2, 3)
x = torch.randn([1, 2, 9, 9])
out = conv2(conv1(x))
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min()
现在让我们添加偏差。我们将从第二个卷积中的偏差开始。偏差是一个与输出通道数大小相同的向量,然后将其添加到卷积的输出中。这意味着我们只需要将第二个卷积的偏差放入结果中。
kernel_size_1 = np.array([3, 3])
kernel_size_2 = np.array([3, 5])
kernel_size_merged = kernel_size_1 + kernel_size_2–1
conv1 = torch.nn.Conv2d(2, 3, kernel_size_1, bias=False)
conv2 = torch.nn.Conv2d(3, 5, kernel_size_2, bias=True)
x = torch.randn([1, 2, 9, 9])
out = conv2(conv1(x))
new_conv = torch.nn.Conv2d(2, 5, kernel_size_merged, bias=True)
padding = [kernel_size_2[0]-1, kernel_size_2[1]-1]
new_conv.weight.data = torch.conv2d(conv1.weight.data.permute(1, 0, 2, 3),
conv2.weight.data.flip(-1, -2),
padding=padding).permute(1, 0, 2, 3)
new_conv.bias.data = conv2.bias.data # here is the new part
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min(
在第一个卷积中添加偏差会稍微复杂一些。我们将分两个阶段进行,首先,我们注意到在卷积中使用偏差等同于创建一个额外的特征映射,其中每个通道的特征都是常数,等于偏差参数。然后将这个特征添加到卷积的输出中。
kernel_size_1 = np.array([3, 3])
kernel_size_2 = np.array([3, 5])
kernel_size_merged = kernel_size_1 + kernel_size_2–1
conv1 = torch.nn.Conv2d(2, 3, kernel_size_1, bias=True)
conv2 = torch.nn.Conv2d(3, 5, kernel_size_2, bias=False)
x = torch.randn([1, 2, 9, 9])
out = conv2(conv1(x))
new_conv = torch.nn.Conv2d(2, 5, kernel_size_merged, bias=False)
padding = [kernel_size_2[0]-1, kernel_size_2[1]-1]
new_conv.weight.data = torch.conv2d(conv1.weight.data.permute(1, 0, 2, 3),
conv2.weight.data.flip(-1, -2),
padding=padding).permute(1, 0, 2, 3)
new_out = new_conv(x)
add_x = torch.ones(1, 3, 7, 7) * conv1.bias.data[None, :, None, None] # New featuremap
new_out += conv2(add_x)
assert (torch.abs(out - new_out) < 1e-6).min()
但是我们不想每次都创建这个额外的特征,我们想以某种方式改变卷积参数,我们是可以做到。我们知道,在对一个常量特征图应用卷积之后,将获得另一个常量特征图。所以,我们只需对这个特征图进行一次卷积就足够了。
kernel_size_1 = np.array([3, 3])
kernel_size_2 = np.array([3, 5])
kernel_size_merged = kernel_size_1 + kernel_size_2–1
conv1 = torch.nn.Conv2d(2, 3, kernel_size_1, bias=True)
conv2 = torch.nn.Conv2d(3, 5, kernel_size_2, bias=True)
x = torch.randn([1, 2, 9, 9])
out = conv2(conv1(x))
new_conv = torch.nn.Conv2d(2, 5, kernel_size_merged)
padding = [kernel_size_2[0]-1, kernel_size_2[1]-1]
new_conv.weight.data = torch.conv2d(conv1.weight.data.permute(1, 0, 2, 3),
conv2.weight.data.flip(-1, -2),
padding=padding).permute(1, 0, 2, 3)
add_x = torch.ones(1, 3, *kernel_size_2) * conv1.bias.data[None, :, None, None]
# This operation simultaneously transfers the bias from the first convolution and adds the bias from the second.
new_conv.bias.data = conv2(add_x).flatten()
new_out = new_conv(x)
assert (torch.abs(out - new_out) < 1e-6).min()
在文章的最后,我想说我们的函数并不适用于所有的卷积。在这个Pyhon实现中,我们没有考虑填充、步长等参数,本文仅仅是用来进行演示。