背景
闲鱼某关键应用A依赖类目系统富客户端(下文简称类目客户端),旨在为闲鱼商品域其他应用提供各类商品类目及属性数据(下文简称CPV数据)查询服务。
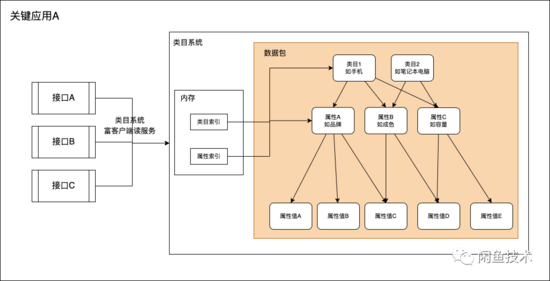
每天凌晨,该应用所依赖的类目富客户端执行新老版本数据包切换时,应用提供的服务抖动非常明显,表现为大量接口超时(耗时100ms -> 3-5s),服务成功率明显下降(100% -> ~92%),RPC线程池活跃线程数上涨(50 -> ~100),抖动最长可持续20s,影响到商品发布、商品详情页等依赖CPV数据的关键业务场景;且夜间发生抖动,时间点不固定,抖动发生时开发同学也难以关注到,影响面较为不可控,因此需要排查并彻底解决此问题。
排查过程
其实这是一个表象很简单,但是根因藏得比较深的问题,笔者在排查过程中也走了一些弯路,也一并写出来供读者作为前车之鉴的参考。
堆空间不够?
结构化应用线上原先使用的是4C8G的标准规格容器,分配4G内存作为堆内存,截取部分JVM启动参数如下:
-Xms4g -Xmx4g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+UnlockExperimentalVMOptions -XX:G1MaxNewSizePercent=65 -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=55 -XX:G1HeapRegionSize=16m -XX:G1NewSizePercent=25 -XX:MaxGCPauseMillis=120 -XX:+ParallelRefProcEnabled -XX:MaxDirectMemorySize=1g -XX:+TraceG1HObjAllocation -XX:ReservedCodeCacheSize=512m -XX:+UseCodeCacheFlushing
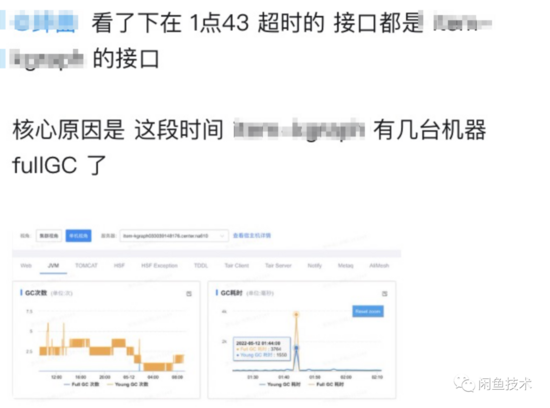
据反馈接口抖动的同学描述,在接口抖动的时间点,请求失败的机器发生了FGC。
undefined
由于本人先前在排查类似的FGC问题时,经常能在Heap Dump的支配树中看到类目客户端相关对象长期占据高位,是内存占用大户。所以难免主观印象先入为主,初步以为是切换版本的过程中,在老版本数据包卸载之前,可能会存在短暂的堆内空间占用double的情况。
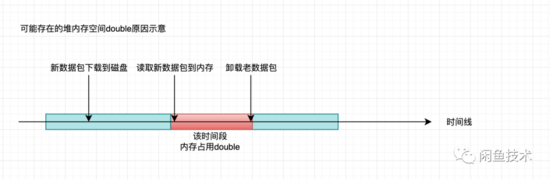
而启动参数配置Eden区下限为25%。可能存在 老年代常驻占用 + 新数据包 > 4G 的情况引发FGC。
因此觉得 既然空间占用double不可避免,老年代常驻的堆空间短时间内又不可能显著下降,Eden区为了解决之前该应用发生Mixed GC时Eden区反常缩小导致YGC异常,又必须固定一个下限值,那只能是把容器内存规格扩大看看能否缓解 。
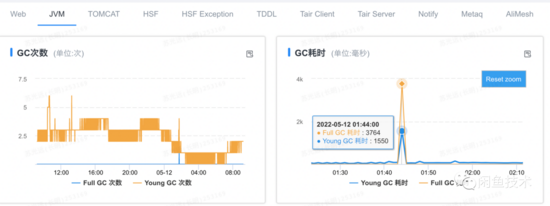
于是将应用容器基线升级到4C16G,设置在16G容器环境下,分配10G内存给堆空间,并逐步升级线上服务的容器规格。
结果花了两天时间,升级了线上大部分的容器后,查看监控,发现大规格的容器确实没有FGC了,且得益于超大的堆内存(10G),从GC监控上看甚至看不出有切包的动作。但是,RPC成功率还是会下跌(100% -> 97%),且RPC线程池线程数还是有少量上涨(50 -> ~71)。
由此可见,FGC并不是切包抖动的核心成因,背后还有更加深层次的原因需要挖掘。
容器CPU高触发自适应限流?
再次询问受影响的业务方,通过下游应用的日志发现推包抖动的时间点,发生了不少sentinel限流日志。而结构化应用里面并没有针对接口主动配置限流,只有集团内的sentinel中间件,可能因为检测到某一时间点CPU利用率过高(超过80%),自动执行限流策略。
sentinel为集团内的流控中间件,能够以流量为切入点,从限流、流量整形、熔断降级、系统自适应保护、热点防护等多个维度来帮助业务保障微服务的稳定性。
登陆发生限流的服务Provider对应机器,确实看到了限流日志。
$cat cpu-sampling.log.1 | grep "2022-05-19 03:57" | grep -v "0.0"
2022-05-19 03:57:12.435|||应用名|CpuSampling|0||4.151785714285714|1.0|6
可以看到在当前时刻,CPU利用率来到了 415%,可见确实在该时间点存在CPU四核全打满的现象。
但是从应用监控来看,该时刻机器CPU利用率只有20%多(100%为单位)。且sentinel的cpu-sampling日志只grep出来一条CPU打满的日志。按照限流中间件20ms采样一次CPU的频率,说明这只是一个CPU尖刺,不应该有大面积的影响。笔者对限流导致RPC成功率下跌其实是抱有些许怀疑态度的,觉得应该不是这样的问题。
不管怎么说,最简单的验证方法,就是线上找一台 已经换了16G内存的机器 ,把sentinel中间件设置为:只记录日志,不执行实际限流动作的dry run模式。看接口成功率是否会跌。按照上面的推理,CPU尖刺最长不会超过40ms,就算CPU打满40ms,也不至于导致接口有几秒钟的超时。
结果到了当天晚上,接口成功率还是掉下来,存在接口几秒钟的超时。
源码窥密,探究类目客户端切包过程中具体动作
发现单纯的提升容器规格并不能解决切包抖动的问题后,笔者复盘了一下手头上已经掌握的线索:
1. FGC不是引起切包抖动的核心原因,这是升级容器,花了钱之后得到的结论。那么,如果不花这个钱,我们能不能单纯从监控上得出结论?其实是可以的。如果目前线上容器规格完全不能满足切包所需的内存消耗,理论上集群每台机器切包的时候都会FGC,但是实际上切包过程中全集群产生的FGC量并不算多,最多在20次左右,且只有1/6的机器发生FGC,剩下的机器也只是YGC略微上涨,然后很快恢复到正常水位。而即使是YGC量上涨,也只是分钟YGC耗时从70ms涨到200ms,根本不至于把大量接口打到超时的。
2. sentinel检测到CPU尖刺,自动执行了限流,确实会拉低服务成功率。但即使把限流关闭,接口还会存在几秒钟超时,说明限流不是造成接口成功率下跌的主要原因。
3. 类目客户端到底把类目数据存在磁盘,还是存在堆里面,亦或者是在堆外内存,四处问了一圈,各有各的说法。 然而,不同的存储方式可能最终会导向完全不同的结论。为了搞清楚这个问题,最精确的方法就是去把类目客户端切包的源码读一遍。于是笔者花了点时间,
类目服务切包流程
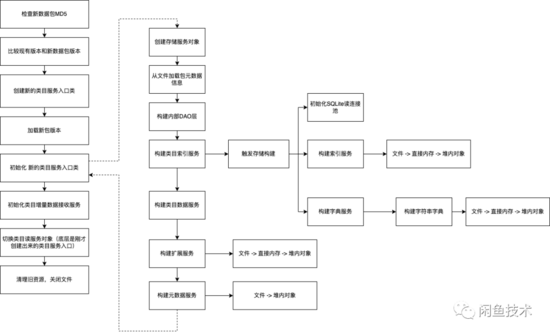
纵观整个切包过程,都是在类目客户端自带的netty ChannelHandler回调线程中 单线程执行 完成的,没有任何多线程并行加载的动作。在初始化类目服务入口的时候,虽然有不少构建索引之类的看起来重计算的动作,但是由于底层是单线程执行,理论上CPU最多打到100%(一个核心),不会有打到400%的情况出现。凌晨结构化应用的业务CPU占用率很低,不到10%,理论上切包+业务不至于导致CPU打满。更不太可能引起长达几秒钟的服务不响应现象。
随着进一步梳理切包和错误发生的时间点、日志信息,一个更奇怪的现象浮出水面。
反常现象:切包完毕后接口开始超时
观察以下全链路日志:
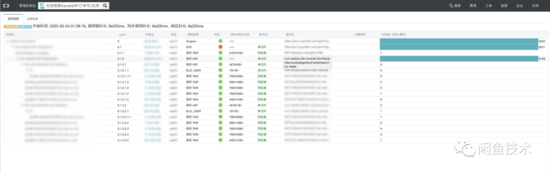
com.taobao.idle.modulet.ItemKgraphServiceApi@getSpuPublishSearchV3~SMM 接口有长达8s的超时。注意这个错误的发生时间 2022-05-24 01:38:19.523 。
平时这个接口RT在400m左右,底层是 使用线程池并行转调各种搜索服务 ,设置了1s的总体超时时间,大量try catch包裹,基本不会报错。
再看这个时间点附近的类目树日志:
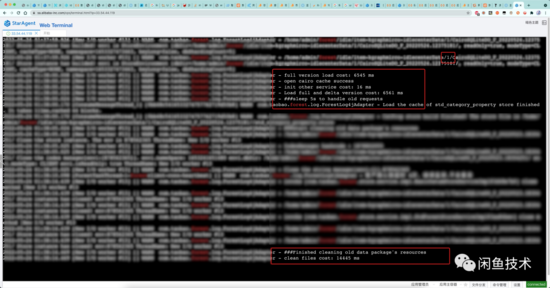
可以看到, 01:38:00 的时候,类目数据就已经切换完了。01:38:14的时候,更是连旧文件都删完了。切包已经结束了。
然而,到了 01:38:27 的时候,类目服务的其中一个Logger, 从 kGraphCommonFixedThreadFactory-10-thread-95 线程打印出两行日志:
2022-05-24 01:38:27.715 [kGraphCommonFixedThreadFactory-10-thread-95] [] WARN 类目服务Logger - Load the cache of std_category_property_value store finished. It takes 7820ms,cached 278 blocks.
2022-05-24 01:38:31.236 [kGraphCommonFixedThreadFactory-10-thread-95] [] WARN 类目服务Logger - Load the cache of std_category_property_value store finished. It takes 11341ms,cached 109 blocks.
而这个线程池,正是运行 getSpuPublishSearchV3 接口底层转调各种搜索的执行线程,且代码为异步执行的Future设置了1s超时,如果执行超过一秒,接口服务的代码也不会继续等待,而是直接往下执行了。
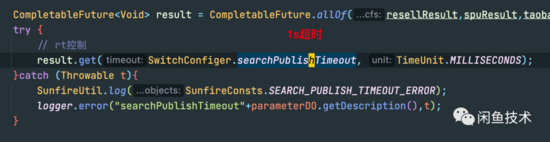
更巧的是:从01:38:19到01:38:27,整整8秒,恰好和上面监控的超时对的上。看到这里,问题似乎变得更加复杂。
- 1. 刚刚我们才提到,切包是在类目客户端的netty ChannelHandler线程里进行,怎么现在又跑到了业务线程池上,甚至能Hang住了接口?
- 2. 为什么类目服务都都跑在别的线程池上面了,且线程池超时设置1s了,为什么接口还会有8s的超时?
拨云见雾,逐个击破
其实回答问题1不难。因为日志已经打出来了,只需要全局搜 Load the cache of ,就能找到唯一一个类目树打日志的地方,再往上倒着找调用栈。会发现 类目属性 和 类目属性值 这两个存储是懒加载的。只有切完包之后,第一次请求读取类目的属性及属性值,才会触发 通过mmap的方式将store文件映射到Java进程的一段连续虚拟地址,并把数据从磁盘读上内存的动作。
核心代码:
MappedByteBuffer mappedBuffer = storeFile.getFileChannel().map(MapMode.READ_ONLY, segmentPosition, segmentSize); // 创建mmap映射
mappedBuffer.load(); // 把数据读上内存
Buffer buffer = FixedByteBuffer.wrap(mappedBuffer);
this.bufferCacheArray[t] = new BufferCache(buffer, ((t == 0) ? meta.getHeaderSize() : 0), blockCountThisSegment, meta.getBlockSize());
for (int i = ((t == 0) ? 0 : blockIdFlags[t - 1]); i < blockIdFlags[t]; i++) {
getReadBlock(i); // 提前创建 blockId -> block buffer的映射
}
因此,加载完成后的日志自然是在业务线程池打的。
Page Fault的“威力”
问题2就不好回答了。因为有一个十分明显的矛盾点: 本次Store加载是在业务线程池加载,对所有Future都只等待1s,1s加载不完立刻就返回了,不可能有8s的耗时。而且机器已经是16G容器,又没有FGC导致的STW。 那就只有进程级别的hang会影响到多个线程了。
为了确认是否存在进程hang,笔者再次去看自适应的cpu-sampling日志。不看不知道,一看吓一跳:

20ms采样一次CPU并打日志的线程也被hang住了!整整到了01:38:27才恢复日志打印。而这段时间正好是store在load的时间,也和接口超时时间吻合
那基本只有一种可能,那就是 第一次读取mmap映射虚拟地址段的数据时,因为数据在硬盘里,还没在内存上,会触发page fault,使得JVM进程陷入内核态,执行从磁盘加载数据到内存的page fault handler,导致进程挂起直到回到用户态 。
参考 《Understanding the Linux kernel》一书 9.4.2 节 Handling a Faulty Address Inside the Address Space。其中有一段话是这么写的:
The handle_mm_fault( ) function returns VM_FAULT_MINOR or VM_FAULT_MAJOR if it succeeded in allocating a new page frame for the process. The value VM_FAULT_MINOR indicates that the Page Fault has been handled without blocking the current process; this kind of Page Fault is called minor fault.
The value VM_FAULT_MAJOR indicates that the Page Fault forced the current process to sleep (most likely because time was spent while filling the page frame assigned to the process with data read from disk); a Page Fault of the current process is called a major fault.
The function can also return VM_FAULT_OOM (for not enough memory) or VM_FAULT_SIGBUS (for every other error).
关注加粗的部分,在处理内存page fault事件时,如果出现了Major Page fault,那么这种Page fault会强制使得当前进程休眠(基本上发生在在需要把数据从磁盘读到进程地址空间内的页块这种耗时场景下)。
再看 MappedByteBuffer#load() 方法Javadoc:
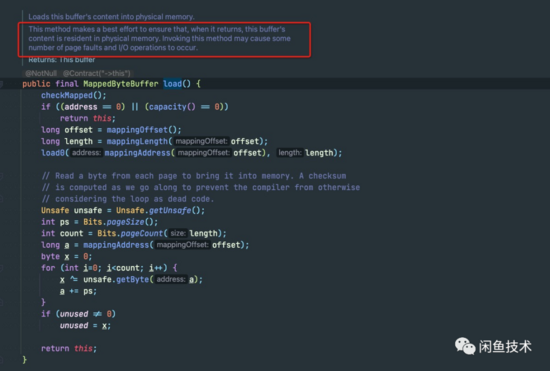
可以看到,Javadoc上写明:Invoking this method may cause some number of page faults and I/O operations to occur.调用这个方法很可能会产生一些page fault。
那么,只要确认在load store的过程中,JVM进程产生了大量的Major Page Fault, 就能解释清楚为什么会出现跨多线程Hang的的情况了。
这里笔者主要使用两个命令: pmap 和 sar 。
pmap能够展示进程的所有连续地址空间,通过查看地址空间的文件引用情况,以及RSS列的值,可以表明当前连续内存空间中有多少个页面被进程引用。
在日常机器上复现场景,可以看到,在执行load store方法之前,当前进程没有引用到任何有关类目文件的虚拟地址空间。

调用查询属性及属性值的方法后,可以看到
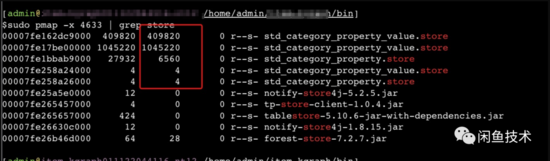
类目树的属性、属性值store被加载上来,且RSS值 == KBytes,说明整个文件都被读到了内存里。
还有一个重要的抓手是 sar 命令。 sar 命令可以以指定的采样率去采样当前整个操作系统的Page Fault发生指标。
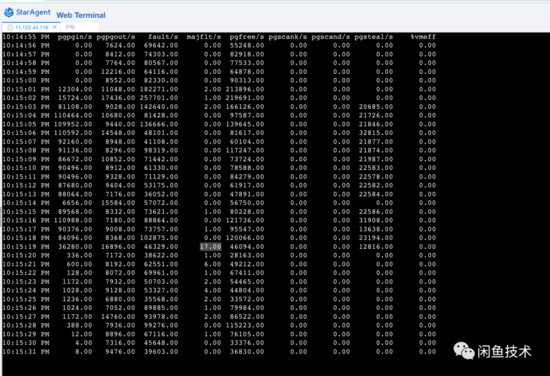
可以看到,initCache过程中,触发了大量的major page fault,同时笔者连接到服务器上的Arthas命令行也hang死无任何反应。进一步验证了上述情况。
Arthas的命令行底层是termd库,纯Java实现。而Arthas又是以java agent的形式附加到目标JVM上的,如果连Arthas的控制台输入命令都没有回显了,基本上只有JVM进程整体Hang死一种可能,该现象也进一步验证了上文提及的进程陷入内核态Hang死的假设。
那为什么会hang住好几秒的时间?通过测量线上容器的IO速度,发现容器的磁盘读写速度在100MB左右,而类目属性值的store文件非常大,达到1.7G。加载一遍这个文件非常耗时。
至此,我们终于可以给出结论。
结论
结构化应用夜间类目客户端推包完成新老数据包版本切换后,存储类目属性及属性值的数据不会立即加载到内存。会等到第一个查询类目属性、属性值的请求到来才会懒加载数据到内存。由于类目属性值store非常大,达到1.7个G。在把1.7G数据整体加载到内存的过程中触发大量Major Page Fault,导致进程进入内核态处理缺页异常。而由于业务容器IO性能较差,完整读取文件十分耗时,最终导致Java进程hang住十几秒的现象。
最终解法
带着问题去咨询类目服务相关同学,他们给出的建议是升级到最新版本的客户端。笔者对比了新老版本客户端的代码,主要有两处改进。
1. 在切包之前,会去load一把store,而不是等到请求进来再懒加载。
2. load store的时候,不是一口气load整个文件,而是把文件切分为64M的小块,每次load 64M,然后sleep一会。再继续load下一块,避免一次性load超大文件块导致进程长时间处于内核态无法对外提供服务。
回过头来思考一些前文提出的问题。既然接口超时是主要是加载大文件引起的,那升16G容器还有必要吗?
笔者认为还是有必要的。原因有两点
1. 现在新版的类目客户端会在切版本、释放老包资源(包括虚拟地址空间)之前先load一把store,虽然store在堆外内存,但是仍然需要占用进程的地址空间,而且实际上还是需要把数据读上内存。因此在切包过程中,从整个Java进程视角来看,确实是会产生double的store空间占用。而目前一个类目store就要1.7G了,两份就是3.4G。还有4G的空间划分给了JVM的堆。剩下不到1G的内存空间,8G容器内存非常吃紧,很容易在切包过程中,load新store的时候产生容器OOM导致容器被杀。
2. 虽然store数据都是存在堆外的,但是store的一些索引对象和元数据还是存在堆里面的,大约占用堆6-700M空间。而无论是新版还是旧版的类目客户端,索引都是在切包之前build的。因此在构建新包索引的时候,峰值也会产生2倍的 堆内空间占用 ,很容易堆内存不足产生YGC甚至FGC。
总结
一个看上去表象非常像GC引起的接口超时,底层却隐藏着更深层次的原因。通过这个案例,也提醒我们,作为技术人,遇到问题,无论表象多么明显,和之前遇到过的场景多么相似,都需要避免被所谓经验蒙蔽双眼、先入为主的坏习惯。大胆推断,小心论证。多问一些为什么,才能一步一步的接近真相。