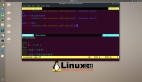
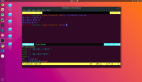
将 PDF 转换为 CSV

在机器学习中,我们应该少一些“数据清理”,多一些“数据准备”。当我们需要从白皮书、电子书或其他PDF文档中抓取数据时,这个脚本为我节省了很多时间。
import tabula
#获取文件
pdf_filename = input ("Enter the full path and filename: ")
# 提取PDF的内容
frame = tabula.read_pdf(pdf_filename, encoding = 'utf-8', pages='all')
#根据内容创建CSV文件
frame.to_csv('pdf_conversion.csv')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
这是一种相对简单的快速提取数据的方法,可以在将数据导入机器学习数据库、Tableau或Count等工具。
合并 CSV 文件
许多系统会提供导出到CSV选项,但是没有办法在导出数据之前首先合并数据。这可能导致5个以上的文件导出到一个文件夹,这些文件包含相同的数据类型。该Python脚本通过获取这些文件)并将它们合并到一个文件中来解决这个问题。
from time import strftime
import pandas as pd
import glob
# 定义包含CSV文件的文件夹的路径
path = input('Please enter the full folder path: ')
#确保后面有一个斜杠
if path[:-1] != "/":
path = path + "/"
#以列表形式获取CSV文件
csv_files = glob.glob(path + '*.csv')
#打开每个CSV文件并合并为一个文件
merged_file = pd.concat( [ pd.read_csv(c) for c in csv_files ] )
#创建新文件
merged_file.to_csv(path + 'merged_{}.csv'.format(strftime("%m-%d-%yT%H:%M:%S")), index=False)
print('Merge complete.')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
最终输出将为您提供一个 CSV 文件,其中包含您从源系统导出的 CSV 列表中的所有数据。
从 CSV 文件中删除重复的行
如果您需要从CSV文件中删除重复的数据行,这可以帮助您快速执行清理操作。当机器学习数据集中拥有重复数据时,这会直接影响可视化工具或机器学习项目中的结果。
import pandas as pd
# 获取文件名
filename = input('filename: ')
#定义要检查是否重复的CSV列名
duplicate_header = input('header name: ')
#获取文件的内容
file_contents = pd.read_csv(filename)
# 删除重复的行
deduplicated_data = file_contents.drop_duplicates(subset=[duplicate_header], keep="last", inplace=True)
#创建新文件
deduplicated_data.to_csv('deduplicated_data.csv')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
拆分 CSV 列
当从其他系统导出文件时,它有时会包含一列数据,而我们需要将其作为两列。
import pandas as pd
#获取文件名并定义列
filename = input('filename: ')
col_to_split = input('column name: ')
col_name_one = input('first new column: ')
col_name_two = input('second new column: ')
#将CSV数据添加到dataframe中
df = pd.read_csv(filename)
# 拆分列
df[[col_name_one,col_name_two]] = df[col_to_split].str.split(",", expand=True)
#创建新csv文件
df.to_csv('split_data.csv')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
合并不同的数据集
假设您有一个帐户列表和与其关联的订单,并希望查看订单历史以及关联的帐户详细信息。一个很好的方法就是通过合并数据到一个CSV文件。
import pandas as pd
#获取文件名并定义用户输入
left_filename = input('LEFT filename: ')
right_filename = input('RIGHT filename: ')
join_type = input('join type (outer, inner, left, right): ')
join_column_name = input('column name(i.e. Account_ID): ')
#读取文件到dataframes
df_left = pd.read_csv(left_filename)
df_right = pd.read_csv(right_filename)
#加入dataframes
joined_data = pd.merge(left = df_left, right = df_right, how = join_type, on = join_column_name)
#创建新的csv文件
joined_data.to_csv('joined_data.csv')- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
最后
这些脚本可以有效帮助我们进行自动化清理数据,然后可以将清理后的数据加载到机器学习模型中进行处理。Pandas是操作数据的首选库,因为它提供了许多的选项。