机器学习算法应该理解数据从中提取有用的特征才能够解决复杂的任务。通常训练泛化模型需要大量带注释的数据。这个是非常费时费力的,并且一般情况下都很难进行。
所以各种基于带掩码的自编码器技术就出现了,这种技术允许在未标记的数据上训练模型,并且获得的特征能够适应常见下游任务
- BERT — 最早的遮蔽模型,用于文本任务 1810.04805
- MAE — 图像,可以说它将BERT的辉煌延伸到了视觉 2111.06377
- M3MAE — 图像+文字 2205.14204
- MAE that listen — 音频 2207.06405
- VideoMAE — 视频 2203.12602
- TSFormer — 时间序列 2107.10977
- GraphMAE — 图 2205.10803
从上面我们可以看到 Masked Autoencoder几乎覆盖了大部分的主要研究领域是一种强大而简单的技术,它使用基于transformer的模型进行预训练得到高水平的数据表示,这对在任何下游任务(迁移学习,微调)上采用该模型都很有帮助。
自监督学习是一种不需要任何标签就能获得数据信息表示的方法。标准的自监督学习技术通常使用高级数据增强策略。但是对于文本、音频、大脑信号等形式来说,如何选择增强策略并且保证策略的合理性是一个非常棘手的问题
而Masked Autoencoder不使用这种策略。我们只需要有数据,并且是大量的数据还有必要的计算资源即可。它使用重建的方式根据被部分遮蔽的样本来预测完整的数据。如果遮蔽了大约70%的数据,模型还能够恢复数据的话,则说明模型学习到了数据的良好的高级表示
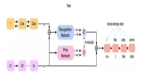
MAE是如何工作的?
MAE 的工作原理非常简单。看看下面的图片:

训练前需要屏蔽一半以上的Patch(比如75%)。编码器接收可见的Patch块。在编码器之后,引入掩码标记,用一个小(相对于编码器小)解码器对全部编码的Patch和掩码标记进行解码,重建原始图像。下游的任务中,编码器的输出作为特征,下游任务不需要进行遮蔽。
一般流程如下:
- 获取数据样本(图像)。
- 对样本进行区域划分(patches for image, word for text等)
- 应用高比率的随机遮蔽(论文中使用75%)
- 只保留可见的部分,并将它们输入编码器。
- 使用上面的掩码进行填充,将编码器的输出和遮蔽进行合并并且保留原始顺序,作为解码器的输入。
- 解码器来负责重建遮蔽。
就是这么一个简单的流程就能够从数据中提取有意义的特征😍
对于下游的任务,只使用预训练的编码器,因为它学习数据的有用表示。
这里需要说明的是,因为由transformer 不依赖于数据的长度,所以在下游使用时可以将完整的样本输入到模型中,也就是说下游的任务不需要进行掩码遮蔽了。
MAE为什么可以在不同的领域中使用?
MAEs可以很容易地适应不同的数据模式。下面图是在视频和音频领域中使用MAE的流程。如果你是这个方向的从业者,试试它吧。
音频的频谱图的MAE

下面的说明来自论文
我们探索了将MAE简单扩展到音频数据的方法。我们的audio - mae学习从音频录音中重建隐藏的声谱图Patch,并在6个音频和语音分类任务中实现了最先进的性能。得出了一些有趣的观察结果:1、一个简单的MAE方法对音频谱图的效果出奇的好。2、在解码器中学习具有局部自我注意的更强的表示是可能的。3、掩蔽可以应用于训练前和微调,提高精度和减少训练计算
视频的MAE

为了进行视频自监督学习,VideoMAE使用了一个遮蔽的自编码器和一个普通的ViT主干。与对比学习方法相比,VideoMAE有更短的训练时间(3.2倍加速)。在未来关于自监督视频训练的研究中,VideoMAE可能是一个很好的起点。
结果展示
最值得关注的结果是所有这些MAE技术都在他们相应的领域击败了SOTA。



训练的细节
这些论文中也都包含了训练的细节的信息,这对于我们进行详细研究非常有帮助。例如损失函数(MSE)仅在不可见的令牌上计算,剩下的就是一些训练的参数:
这是MAE的

这是视频的

优点和缺点
优点
可以看到,MAE这种方式几乎适用于任何形式的任务
缺点
这种方法的骨干都是transformer,(目前)没有其他的骨干,并且它需要大量的数据和计算资源。
总结
这是一个非常强大的技术,可以用于任何领域,并且还能够起到很好的效果。
TSFormer 虽然使用了这个方法但是也没有公开代码,并且效果也不太好,但是我们是否可以利用MAE,将多元时间序列表示为音频,并提供相同的预训练呢?这可能对用少量标记数据解决下游任务有很大帮助。
是否可以增加额外的损失函数和限制。这样就可以对训练模型进行重构,甚至做一些聚类的工作。
除此以外还有更多的论文我们可以参考:
- MultiMAE(2204.01678):多模态多任务MAE。
- 结合对比学习(augs)与MAE:Contrastive Masked Autoencoders are Stronger Vision Learners 2207.13532
其实MAE的出现不仅仅是将BERT在NLP中的成就扩展到了CV:
- iGPT是最早提出(目前我所知道的,欢迎指正)把图像马赛克掉,变成一个个色块,数量一下就减少了,可以像NLP一样愉快地输入到Transformer了,但是会存在训练预测不一致的问题。
- ViT的预训练方法,mask掉50%的patch,预测patch的mean color
- BEiT用了一个dVAE对patch进行离散化,mask 40%的patch
但他们其实都没有理解一个问题,就是到底是什么原因导致视觉和语言用的masked autoencoder不一样。而MAE的成功就在于这个问题想清楚,并且给出了解决方案。
所以我个人认为MAE是一个很好的开端,并且它已经证明了领域内的知识+简单的方法能够创造出很好的模型。