Amazon S3 全称Amazon Simple Storage Service,旨在通过web服务接口提供业界领先的性能、速度、安全性、可伸缩性和数据可用性。该平台由亚马逊网络服务(AWS)开发,并于2006年3月14日首次推出,后续S3逐渐演变为对象存储的标准。
随着公司的快速发展,公司内对各种图片、视频、文件等这类对象的存储需求越来越强烈。
目前公司内的接入场景包括,二维码,景区推荐视频,图片,css,js,ML训练素材等资源,大约10亿+文件数。都是核心的业务场景,如果存储服务故障,影响的范围会比较大,比如扫不了入园二维码,访问不了图片等。
由于历史原因,现在公司内提供类似存储的服务有好几套,包括Ceph s3,FastDfs+Redis(做元数据存储),公有云 s3代理等,几套服务都有比较明显的问题。比如公有云 s3,使用成本相对比较高,而且走外网交互性能得不到保障;比如Ceph,想完全维护好需要投入大量的成本,性价比不是很高;再比如fastdfs+redis,接入不太友好,支持不了主流的S3。所以我们提供了一套新的对象存储服务来解决以上问题,本文会详细介绍,我们新的对象存储服务(OSS)是怎么做的。
01 设计目标
整体的设计目标如下:
可扩展: 至少需要支持到10亿+的对象数,并且需要有水平扩展的能力;
高可用: 要做到高可用,至少要有隔离,多租户,限流,灾备/双活等能力,最核心业务甚至可以做到不同存储产品的灾备;
高性能: 需要足够快,类似ceph rados,后续需要可以作为分布式文件存储的存储底座;
低成本: 可以用远低于ceph的成本支撑所有的业务;
接入简单: 能够支持主流对象存储S3协议的接入;
无缝升级: 可以在业务无感知的情况下,稳定的、无缝将业务从ceph s3,公有云 s3迁到新oss。
02 系统设计
简单来说,设计目标可以拆分成2个点:
- 需要一个非常强大的对象存储oss服务
- 如何在架构层面解决业务无缝切换,存储无缝升级从而保障业务的稳定性
下面我将从这2点来介绍下我们是怎么做的。
oss技术选型
近些年越来越火的开源+商业化的模式让每个方向都或多或少出现了一些比较好的开源产品,比如时序存储方向的TDengine,OLAP方向的ClickHouse等等,在对象存储选型的时候,我们也优先考虑开源产品,通过开源共建的方式来完成我们的产品,尽量不从0开始造轮子。整个社区看下来,相对比较热门的有minio,SeaweedFS,fastdfs,ceph。其中ceph跟fastdfs不在考虑范围内,所以精力就放在minio跟SeaweedFS上,看是否能满足要求。
minio
minio应该是目前最火的开源对象存储,github 3w4的star数。
minio的优点包括:
- 友好的UI
- 部署比较简单,很容易上手
- 支持文件级别的自愈,在节点故障时无需人工干预
- 全EC存储,成本相对比较低
- 中大文件性能比较好
- 基于文件系统设计,无需额外的存储来存储元数据
同样minio的缺点也相对明显:
- 仅支持EC,会存在io放大的问题,特别是在大量小文件的场景下
- 扩容不太友好,对等扩容时需要全集群停止服务
- 支持的文件数量有限,基于本地文件系统设计,在对象数变多以后,inode的查找都会变得很耗时
minio是一款有明显优缺点的产品,在我们的需求背景下,minio不能够很好的满足,特别是不能够支持我们10亿+对象存储需求,而且在现有的架构设计下,也不太好改造,然后通过与社区共建的方式来满足我们海量小文件的需求。
SeaweedFS
越来越火的对象存储开源方案,github star数1w5+,且增长速度比较喜人,社区也比较活跃。
SeaweedFS官方介绍的核心点有2个:
- to store billions of files!
- to serve the files fast!
跟我们的部分核心目标比较贴近。
核心优点包括:
- 性能比较强大: 核心理论依据是基于 Facebook's Haystack design paper ,该paper的目标也是解决facebook内部图片视频等数据的存储查询问题
- 架构设计比较灵活: 系统设计参照了Facebook’s Tectonic Filesystem ,特别是几个核心组件的设计,抽象的比较好,非常方便扩展不同的实现,并且整体架构上可以水平扩容,没有明显的瓶颈点
- 功能齐全: 存储比较关心的冷热分离,EC存储,TTL等功能都有支持
- 部署简单: 部署非常简单,很容易上手
相比于优点,也会有些不足
- S3的适配不完全: 实现了大部分的常用接口,部分非常用接口未实现,比如Canned ACL等。
- 项目背景: 相比于minio等开源产品后面都是强大的商业化公司,该项目核心的作者只有 chrislusf 大神
从各个维度来看,基于SeaweedFS开源共建的方式来打造我们的对象存储服务是目前比较合理的方案。
系统架构
架构介绍
确定选型SeaweedFS后,下一步就是怎么来设计整体服务来满足我们的需求,简易架构如下:
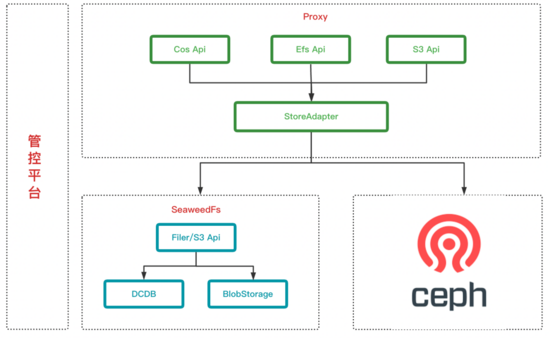
整体架构其实是一个比较常见的架构,非常简单
- Proxy层: 来适配不同的Api以及对业务做存储适配
- 存储层: 包括SeaweedFS,Ceph s3,公有云 s3. 公有云 s3的操作跟Ceph s3类似,本文就不展开了
- 管控平台: 可视化UI,做权限配置,配额配置,数据列表等
名词解释:
- 公有云 s3 Api: 公司内部之前封装的公有云 s3对外的Api
- Efs Api: 公司内部之前封装的对外的静态资源相关的Api
- S3 Api: 适配了S3的所有Api
- StoreAdapter: 来根据配置来处理业务的请求,选择存储适配
- Filer/s3 Api: SeaweedFS用来对外暴露s3等相关Api的服务
- DCDB: 公司基于BaiKalDB共建的分布式数据库,下文会详细介绍
- BlobStorage: SeaweedFS中用来实际做对象存储的模块
设计目标详解
可扩展
目标: 至少需要支持到10亿+的对象数,并且需要有水平扩展的能力。
proxy是无状态的,可以做到水平扩展,所以只需要SeaweedFS做到可以水平扩展就可以满足我们的需求了。
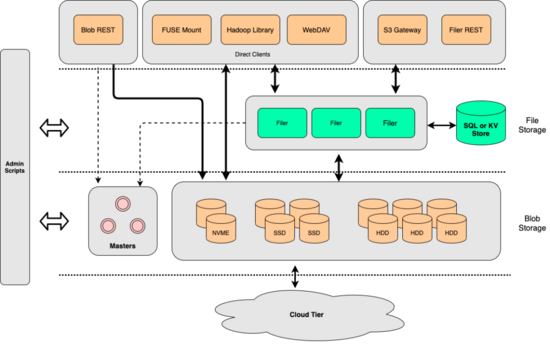
从整体架构上来看,SeaweedFS核心的有2层(S3存储最核心的基本都是这2块)
- File Storage: 用来做metadata元信息的存储以及做api的适配
- Blob Storage: 对象存储的底座
metadata的能力是比较核心的一个环节,他至少需要做到:水平扩展能力,不丢数据,读写性能比较好,高可用。类似的服务有:Cassandra,Tidb,YDB,toctonics用的ZippyDB等等。基于我们公司现状,我们选择了跟BaiKalDB共建的分布式数据库DCDB。
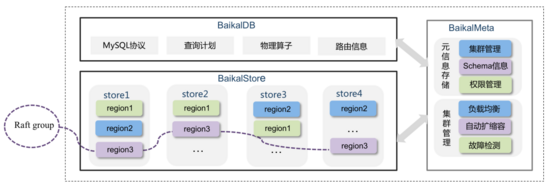
DCDB在我们公司使用的比较多,性能得到了很好的验证,并且能够很 好的匹配 我们的诉求。 在引入DCDB做元数据服务后,测试下来读写请求的平均耗时在1ms内,能够满足我们的需求。
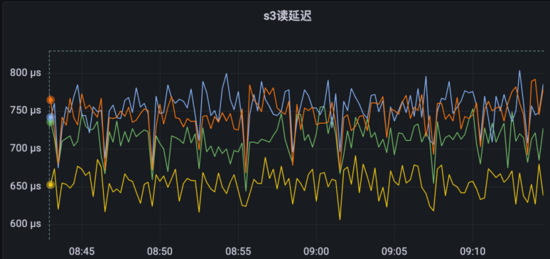
以上是dcdb真实使用下来的监控数据,因为可以水平扩容,我 们压测 结果为即使数据量级到了几十亿,也没有出现性能瓶颈。
有了DCDB的加持,比如整个读流程就会非常的简单,从DCDB获取元信息,返回数据对应的存储节点,直接跟存储节点交互获取数据,存储节点之间是没有直接关系的,可以做到水平扩展。
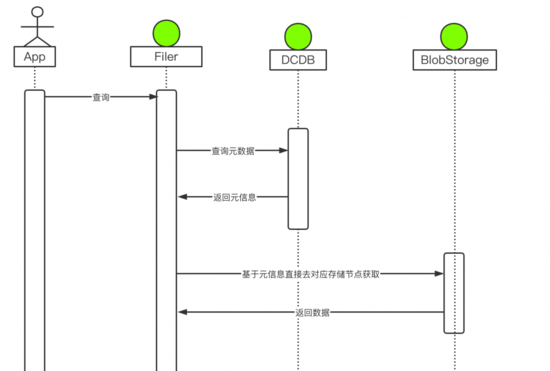
整体看下来,现在整个集群内没有明显的瓶颈点,所有的组件都可以做到水平扩容,可以很好 的满 足我们对规模的要求。
高可用
需要做到高可用至少需要保障在单点故障(物理机故障等),预期外流量冲击,甚至单idc故障时服务要可用,以及要做到多租户之间相互隔离。下面分别介绍下这几种场景是怎么做的:
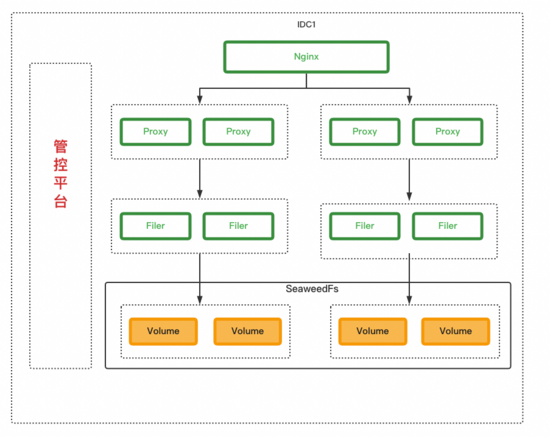
(1)隔离
业务隔离,我们做到了在nginx上做分流,不同的业务(bucket)使用不同的proxy,filer,volumeServer。 做到了业务与业务之间物理隔离,相互不影响。
(2)租户与限流
除了物理隔离外,还需要至少做到业务级别的限流熔断功能。对象存储跟其它的大数据服务有个比较大的区别是流量特别大,比如并发上传1M的文件,很轻松就可以将流量打到几十上百GB,会造成网络上面的瓶颈,所以我们要做到可以给业务配置阈值,做到当某个业务有预期外的流量时,可以单独限制不能影响到整体服务,甚至造成网络故障。
关于租户的限流我们pr了2个策略,一个是基于bucket级别的全局流量限制,一种是可以基于 count+单文件下载限速的流量控制可以比较好的使得整个集群可控。
(3)高可用
proxy,filer,dcdb上文都介绍了,可以做到高可用,现在介绍一下数据是怎么做高可用的。数据高可用正常会有2种方式:多副本与EC纠删码
SeaweedFS支持实时写数据使用副本方式,后期可以转换为EC. 都是可以做到数据高可用的。
高性能
SeaweedFS官方介绍的其中一个特点是:to serve the files fast!
核心实现思路是参照Facebook's Haystack design paper,论文里面介绍的比较详细。
工程实践后最终效果做到了,小文件合并后的顺序写以及O(1)的硬盘读. 下图是我们6台256G,12*8TB SATA盘,压测的是1M的写,io优先到了瓶颈点。写入3000 TPS
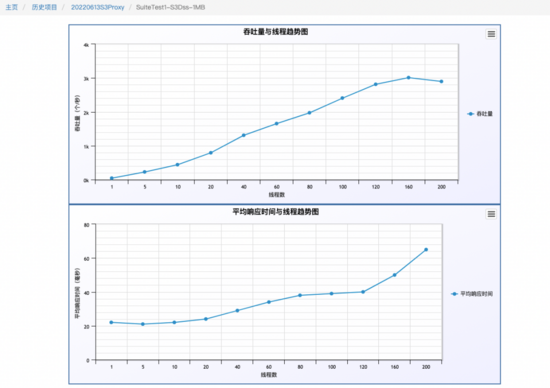
下图是我们6台256G,10TB SSD盘,压测的是1M的 写,因 为带宽限制,没有继续压,各个指标远没有到达瓶颈。 写入4000 TPS
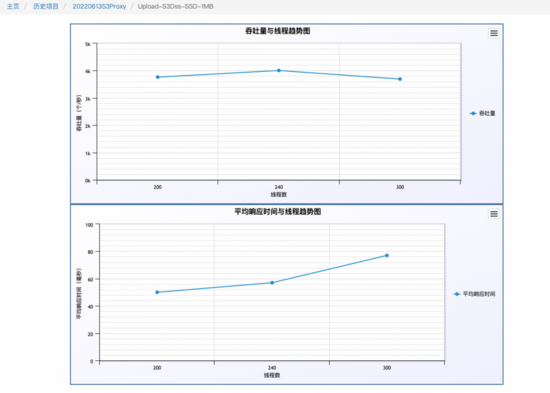
在写入,查询,删除混合场景(6:3:1)压测下,1M的文件 3500+ QPS
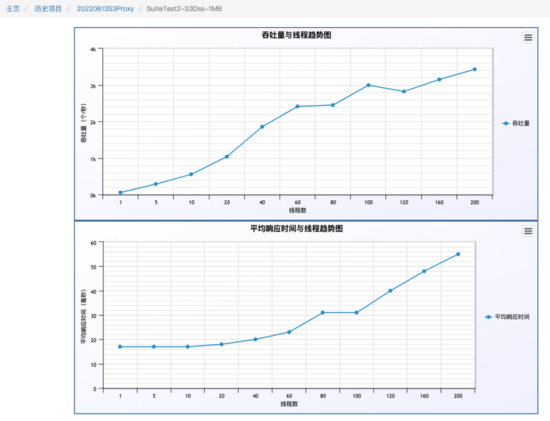
以上结果仅用了6台机器测试,性能结果达到我们的需求,后期如果有更高的需求,可以做水平扩展。
低成本
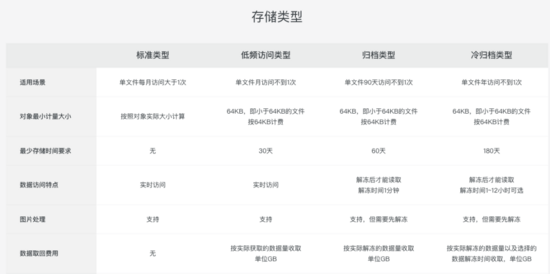
对象存储最大的成本会是在存储上,数据量会非常大,几百TB,PB甚至EB都是可能的。 如上图,各种云厂商也提供了不同存储的不同的计费,简单来说,就是冷的数据可以牺牲一部分性能来降低存储的成本。 同样SeaweedFS也做了类似的功能。
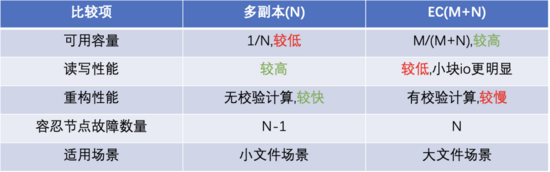
补充个小知识点: 多备份与EC的差异,可以清楚的看到成本角度,EC比多副本更有优势。
现在我们可选的存储介质包括NVME SSD,SATA SSD,HDD。可选的数据存储方式有多副本,EC。
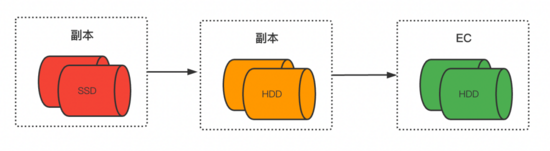
如图,随着数据越来越冷,我们会慢慢从SSD迁移到HDD,以及从副本方式改为EC存储。 做了性能与成本的取舍。
无缝升级
上面介绍了SeaweedFS的一些功能,下面介绍一下我们是如何让业务无缝从ceph s3,公有云 s3,efs api等存储切到新的平台来。目前场景以ceph为例:
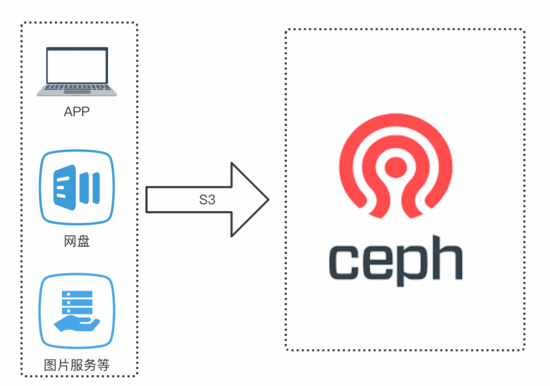
(1)流程适配
业务直接通过S3对ceph进行操作。我们要做的就是偷梁换柱,在业务无感知的情况下,将ceph s3替换为更高可用的SeaweedFS。大概需要做几个事情
- 全api的适配
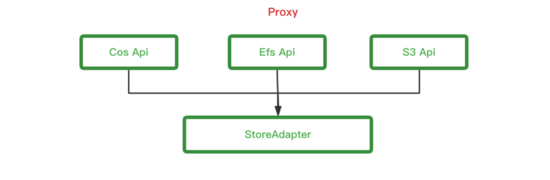
proxy适配了我们原先所有对外的api,包括s3 api,公有云 s3 api,efs api,所有api解析完内部操作完全一致了,这样可以做到只需要域名解析调整到proxy就可以了。
- 读流程的适配
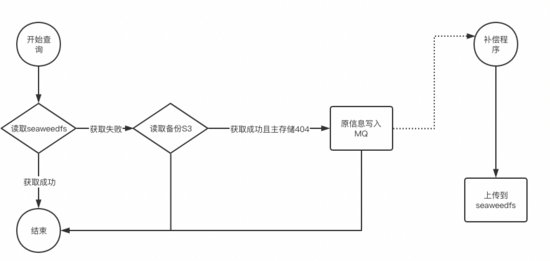
因为历史的原因,现在ceph s3以及公有云 s3里面存在了大量的不再使用的数据几百TB,这些数据是不需要导入到新存储的,如上图,我们proxy支持了一种策略s3 -> S3的策略。 主要特点有2个:
①存储级别的高可用:新存储故障自动切到备存储,做到存储级别的高可用
②自动数据补齐:新存储无数据,备存储有数据,自动将该数据的元信息写入MQ
同时我们还有一个补偿的程序来读取MQ中的数据,自动将被存储的数据补偿到新存储,这样可以做到一段时间后,所有热数据(有访问的数据)自动备份到新存储了,ceph s3/公有云 s3可以下线。
注: 写MQ的时候需要注意,需要按照文件级别做顺序写入,防止数据有问题
- 写流程的适配
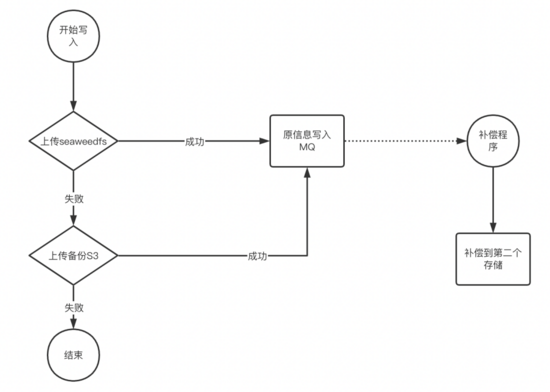
写入做了取舍,为了提升性能,写入只需要一个存储写成功就响应给业务,第二个存储的数据由补偿程序来完成。 该流程可以做到任意存储故障时,业务都无感知。
proxy中所有操作都是S3的标准接口操作,所以可以轻易做到SeaweedFS与ceph s3,SeaweedFS与公有云 s3,SeaweedFS与SeaweedFS的多种灾备方案。比如最核心的业务场景二维码,景区图片等,我们会先运行一阵SeaweedFS与公有云 s3的自动灾备,防止某种场景 下触发了某个存储的bug,而造成大面积的影响。
写入MQ的数据还有一个用途,用来做双存储的数据校验,保障2个集群的数据最终一致性。
注:
- 图中默认写入MQ是成功的,实际proxy中有兜底策略,写MQ失败有另外的兜底策略,比较复杂,这里不做阐述。
- 以上介绍了2个核心场景流程,还有部分场景稍有区别,如list api等 。
(2)升级步骤
除了理论上的无缝外,为了稳定的运行上线,上线流程也比较讲究,我们大概会分几步:
- 数据比对: 拿s3 api为例,切换之前我们会有个比对程序,订阅nginx的访问日志,来做2个存储的结果比对,核心比对结果主要包括文件的MD5,以及响应的header头。
- 策略调整: 因为业务比较核心,为了稳定的推进,每次只做最小化变更,推进过程分了3步: 1: 引入代理,保障代理功能正常 2: 引入SeaweedFS为主,做成SeaweedFS与ceph的
集群备份,这样可以做到即使SeaweedFS有问题,我们也可以快速的将流量回滚到ceph 3:下线ceph,最终形态,做成SeaweedFS的双集群备份。
03 落地收益
得益于开源的好处,我们仅仅投入了2个人力,整个迭代从选型到源码、原理研究到开始落地大概持续了3个月,该项目上线已经运行了接近3个月,运行良好,达到了预期的期望效果。目前已接入 接近2000w对象,60TB的数据量,还在快速流量切换中。
以核心业务efs为例,之前存储使用的是公有云 s3,现在切换到了第二步(SeaweedFS为主集群,公有云 s3为备用集群)。 切换后的收益:
- 性能: 响应耗时有了质的提升,从150ms下降到3ms。
- 稳定性: 之前访问公有云 s3走的是公网,性能波动比较大,切换后耗时变得非常平稳。
- 成本: 目前到了第二步,公有云 s3还剩下了写入的流量,读的流量基本清0了,成本也下降了很多。
04 使用tips
- volumeGrowthCount: 这个需要调整,要做到尽量所有volumeServer都有writeable的volume,否则写入,查询性能会有影响。
- fs.configure: SeaweedFS的设计是每个bucket都对应一个collection,这样可以方便的做生命周期管理,需要控制bucket数量,否则性能会影响比较大。我们内部先改版了取消这个绑定,做到性能最优,不过牺牲了一些bucket的统计功能,完整功能还在优化中。
- filer.sync: 没有proxy的情况下,可以使用filer.sync的同步工作来做双集群灾备。
05 未来展望
- 定期备份: 核心bucket的增量、全量定期备份,做到跟db类似的效果,可以做到万一误删等问题也可以回滚。
- 开源共建: 到目前为止,我们也陆陆续续大大小小提交了20+pr,包括bug fix,性能功能优化,后续会持续的关注社区,跟社区一起成长。
- 基于S3的存计分离方案: 现在很多主流的存储产品都适配了S3,比如prometheus,clickhouse等等。因为新oss的强大的性能,我们会在这些适配S3的存储上面试点存储与计算分离。
- 分布式文件存储: 类似ceph,可以基于对象存储rados打造分布式文件存储,以及现在比较火的juicefs或curvefs也是基于s3构建的。后期也计划基于该oss实现分布式文件存储,一期目标在除了对io latency要求非常高(mysql)的场景外落地,为业务赋能。