译者 | 陈峻
审校 | 孙淑娟
让我们试想一种场景:团队中几个说不同语言的人见面了。为了相互理解,他们需要使用一种每个人都能听得懂的语言进行交流。为此,他们都应该在自己的母语以及该通用语言之间,执行信息的转换。同理,如果我们使用协议缓存区(Protocol Buffers)消息语言,则能够让整个团队都使用自己特定的编程语言去创建消息,接着被翻译成通用语言的形式。正如Wikipedia解释的那样:“Google正广泛地使用协议缓冲区,来存储和交换各种结构化的信息。该方法作为自定义的远程过程调用(Remote procedure call,RPC)系统的基础,可用于几乎所有与Google交互的机器间通信。”

由于我经常需要通过参与各个行业的开发项目,与定制软件打交道,而且专注于在嵌入式系统中使用Modern C++、以及Qt去构建应用程序,因此下面我将与您分享自己在内存受限的嵌入式系统上,使用协议缓冲区的经验。
协议缓冲区消息语言
正如Google所言,“协议缓冲区能够让您以.proto文件的形式,定义需要的数据结构,以便您使用特定生成的源代码,从不同的数据流,使用不同的语言,去轻松地读写自己的结构化数据。”我们可以通常下图了解其基本原理:
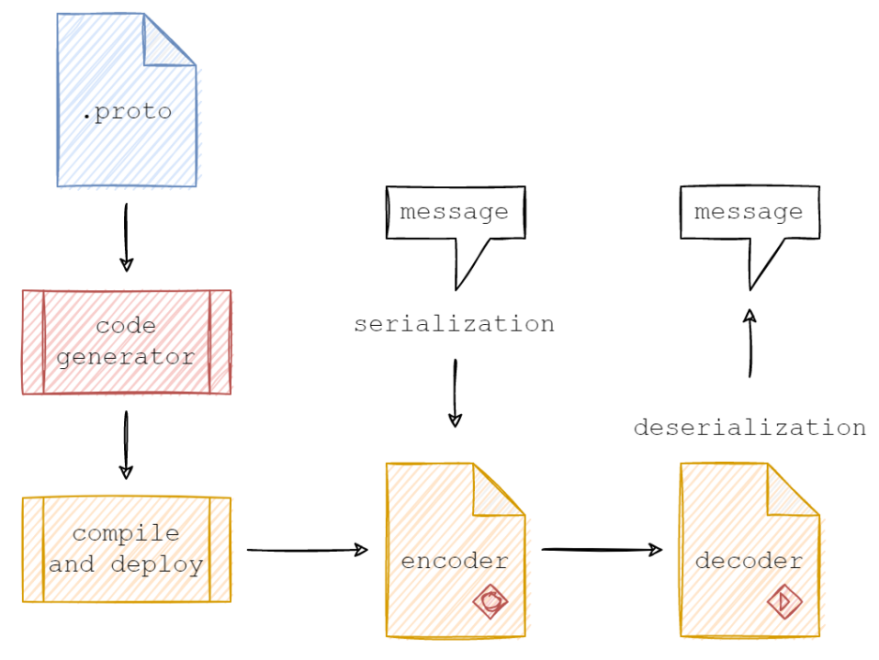
根据协议缓存区语言指南,我们首先来讨论一个非常简单的例子。假设您准备定义一个Person消息格式,由于每个人都有一个名字、年龄和电子邮件等属性,因此被用于定义消息类型的.proto文件的内容可设定为如下形式:
ProtoBuf
// person.proto
syntax = "proto3";
message Person {
string name = 1;
int32 age = 2;
string email = 3;
}
其中第一行便指定了使用文件的proto3语法。接着,Person的消息定义指定了三个字段(即,名称/值对)。每一个都可以被用于您需要包含在此类消息的数据块中。而且每个字段包含了名称、类型和字段数的信息。
拥有了.proto文件,您便可以为特定的语言生成源代码语言。例如,C++会使用一种特殊的被称为协议编译器(protocol compiler,又名 protoc)的编译器。请参见下图:
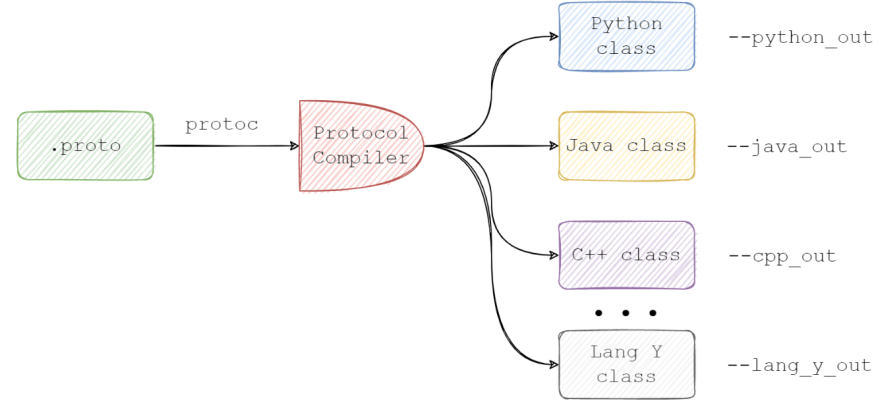
在此,我们把能够生成包含原生语言(language-native)结构,以操控消息的接口称为API。API可以为您提供所有需要set和retrieve数据的类和方法,以及对字节流的serialization to和parsing from方法。
在C++中,各种生成的文件都包含了Person类和所有必要的方法,以处理底层的数据。例如:
C++
void clear_name();
const ::std::string &name() const;
void set_name(const ::std::string &value);
void set_name(const char *value);
此外,Person类通过继承来自google::protobuf::Message的方法,对数据流进行序列化或反序列化(解析)。例如:
C++
// Serialization:
bool SerializeToOstream(std::ostream* output) const;
bool SerializePartialToOstream(std::ostream* output) const;
// Deserialization:
bool ParseFromIstream(std::istream* input);
bool ParsePartialFromIstream(std::istream* input);
在Protobuf-C中使用自定义的静态分配
如果您正在编写一个完整的静态分配系统,那么可能需要用到的是C而不是C++。下面,我们来讨论如何使用静态分配的缓冲区,而不是动态分配的内存,去编写一个定制的分配器。
默认情况下,Protobuf-C会通过malloc(),来调用动态的分配内存。Protobuf-C会向您提供一种定制分配器(custom allocator)的能力,以替代malloc()和free()函数。下图展示了malloc()和serial_alloc()在处理上的不同,我将对serial_alloc()进行后续讨论。
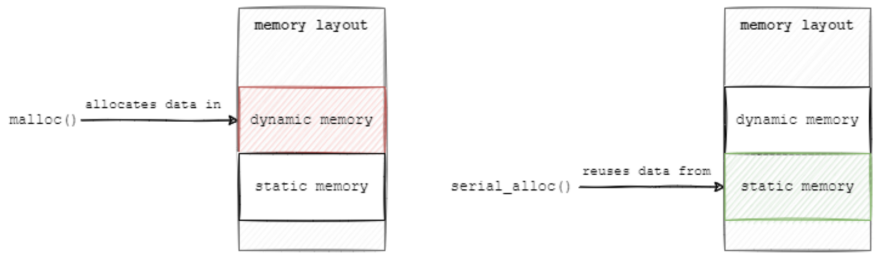
在本例中,我将实现自定义的malloc()和free()函数,并将其使用到自定义分配--serial_allocator中。它会通过Protobuf-C库将数据转换成一个连续的、静态分配的内存块。下面两张图分别展示了malloc()和serial_alloc()的具体差异:
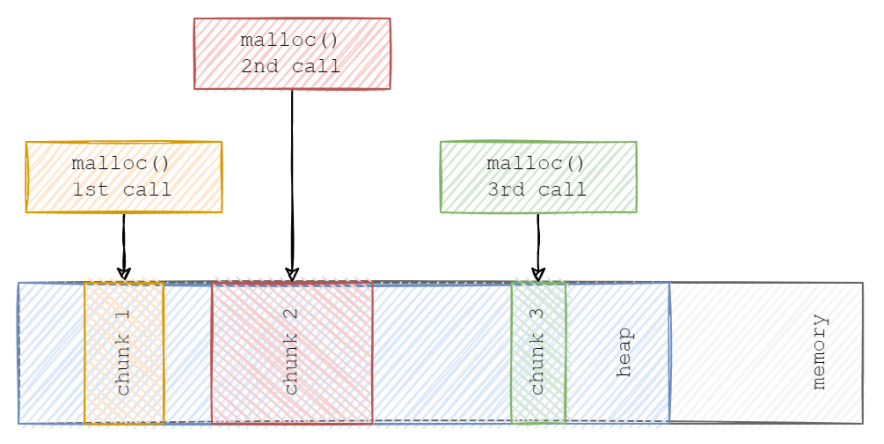
在heap上的malloc()分配
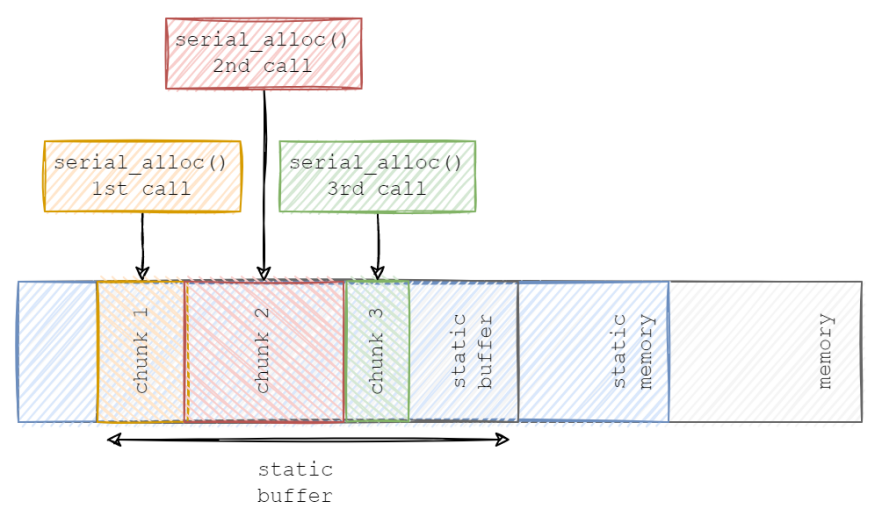
静态缓冲区上的serial_alloc()分配
由于malloc()在堆(heap)上分配内存的“随机性”,会导致内存碎片有待整理。而我们定制的serial_alloc()会在序列中静态分配内存,因此无需内存碎片整理。
环境设置
下面,我将在Ubuntu 22.04 LTS上,通过如下命令,安装protoc-c编译器、以及协议缓存区的C Runtime:
Shell
sudo apt install libprotobuf-c-dev protobuf-c-compiler
并通过如下命令检查其是否运行:
Shell
protoc-c --version
如果一切正常,屏幕上会返回已安装的版本号:
Plain Text
protobuf-c 1.3.3
libprotoc 3.12.4
您可以通过链接-- https://github.com/protobuf-c/protobuf-c,查看它在GitHub库中的完整代码。
消息
下面,我们来查看在message.proto文件中创建的简单Protobuf消息。
ProtoBuf
syntax = "proto3";
message Message
{
bool flag = 1;
float value = 2;
}
然后通过运行如下命令,以生成message.pb-c.h和message.pb-c.c两个文件:
Shell
protoc-c -I=. --c_out=. message.proto
程序编译
请通过如下命令,使用protobuf-c库与生成的代码,去编译C语言程序:
Shell
gcc -Wall -Wextra -Wpedantic main.c message.pb-c.c -lprotobuf-c -o protobuf-c-custom_allocator
程序代码会使用Protobuf-C依次进行序列化、编码、包装成为静态缓冲区--pack_buffer,然后经过反序列化、解码、拆包到另一个静态缓冲区—out。下面展示了其完整的代码:
C
static uint8_t pack_buffer[100];
int main()
{
Message in;
message__init(&in);
in.flag = true;
in.value = 1.234f;
// Serialization:
message__pack(&in, pack_buffer);
// Deserialization:
unpacked_message_wrapper out;
Message* outPtr = unpack_to_message_wrapper_from_buffer(message__get_packed_size(&in), pack_buffer, &out);
if (NULL != outPtr)
{
assert(in.flag == out.message.flag);
assert(in.value == out.message.value);
assert(in.flag == outPtr->flag);
assert(in.value == outPtr->value);
}
else
{
printf("ERROR: Unpack to serial buffer failed! Maybe MAX_UNPACKED_MESSAGE_LENGTH is to small or requested size is incorrect.\n");
}
return 0;
}
在unpack_to_message_wrapper_from_buffer()中,我们创建了ProtobufCAllocator对象,并将serial_alloc()和serial_free()函数(作为malloc()和free()的替代品)放入其中。然后,我们通过调用message__unpack和传递serial_allocator去解包消息(请参见如下代码):
C
Message* unpack_to_message_wrapper_from_buffer(const size_t packed_message_length, const uint8_t* buffer, unpacked_message_wrapper* wrapper)
{
wrapper->next_free_index = 0;
// Here is the trick: We pass `wrapper` (not wrapper.buffer) as `allocator_data`, to track number of allocations in `serial_alloc()`.
ProtobufCAllocator serial_allocator = {.alloc = serial_alloc, .free = serial_free, .allocator_data = wrapper};
return message__unpack(&serial_allocator, packed_message_length, buffer);
}
比较基于malloc()与serial_alloc的方法
下面,我们来比较默认的Protobuf-C行为(基于malloc())和自定义分配器的行为。其中使用动态内存分配的Protobuf-C行为是:
C
static uint8_t buffer[SOME_BIG_ENOUGH_SIZE];
...
// NULL in this context means -> use malloc():
Message* parsed = message__unpack(NULL, packed_size, bufer);
// dynamic memory allocation occurred above
...
// somewhere below memory must be freed:
free(me)
使用定制分配器(无动态内存配置)的是:
C
// statically allocated buffer inside some wrapper around the unpacked proto message:
typedef struct
{
uint8_t buffer[SOME_BIG_ENOUGH_SIZE];
...
} unpacked_message_wrapper;
...
// malloc and free functions replacements:
static void* serial_alloc(void* allocator_data, size_t size) { ... }
static void serial_free(void* allocator_data, void* ignored) { ... }
...
ProtobufCAllocator serial_allocator = { .alloc = serial_alloc,
.free = serial_free,
.allocator_data = wrapper};
// now, instead of NULL we pass serial_allocator:
if (NULL == message__unpack(&serial_allocator, packed_message_length, input_buffer))
{
printf("Unpack to serial buffer failed!\n");
}
Proto Message的结构
unpacked_message_wrapper的结构只是一个简单的Proto消息包装器。它的容量足以缓冲解包后的数据存储,以便next_free_index跟踪缓冲区里的已使用空间。请参见如下代码:
C
typedef struct
{
size_t next_free_index;
union
{
uint8_t buffer[MAX_UNPACKED_MESSAGE_LENGTH];
Message message; // Replace `Message` with your own type - generated from your own .proto message
};
} unpacked_message_wrapper;
其中,虽然Message对象不会改变它的大小,但是Message往往是一个广泛的.proto。例如,重复性的字段通常会涉及到多个malloc()的调用。因此,您可能需要比Message本身更多的空间。为此,我们可以将buffer和Message联合起来,并让MAX_UNPACKED_MESSAGE_LENGTH足够大。而且,unpacked_message_wrapper的结构,就是要将预定义的内存缓冲区与跟踪缓冲区的分配放在一处。
serial_alloc()和serial_free()的实现
serial_alloc()的签名遵循着ProtobufCAllocator的各项要求,例如:
C
static void* serial_alloc(void* allocator_data, size_t size)
其中,serial_alloc()可以分配被请求的size到allocator_data处,然后增加next_free_index到下个词的开始边界处(这是一个优化过的连续数据块,紧贴着下一个词的边界)。而size则来自Protobuf-C内部解析或解码的数据。请参考如下代码:
C
static void* serial_alloc(void* allocator_data, size_t size)
{
void* ptr_to_memory_block = NULL;
unpacked_message_wrapper* const wrapper = (unpacked_message_wrapper*)allocator_data;
// Optimization: Align to next word boundary.
const size_t temp_index = wrapper->next_free_index + ((size + sizeof(int)) & ~(sizeof(int)));
if ((size > 0) && (temp_index <= MAX_UNPACKED_MESSAGE_LENGTH))
{
ptr_to_memory_block = (void*)&wrapper->buffer[wrapper->next_free_index];
wrapper->next_free_index = temp_index;
}
return ptr_to_memory_block;
}
当serial_alloc()被第一次调用时,程序会将next_free_index设置为已分配的大小,并将指针返回至缓冲区的开始处。下图展示了其内部逻辑:
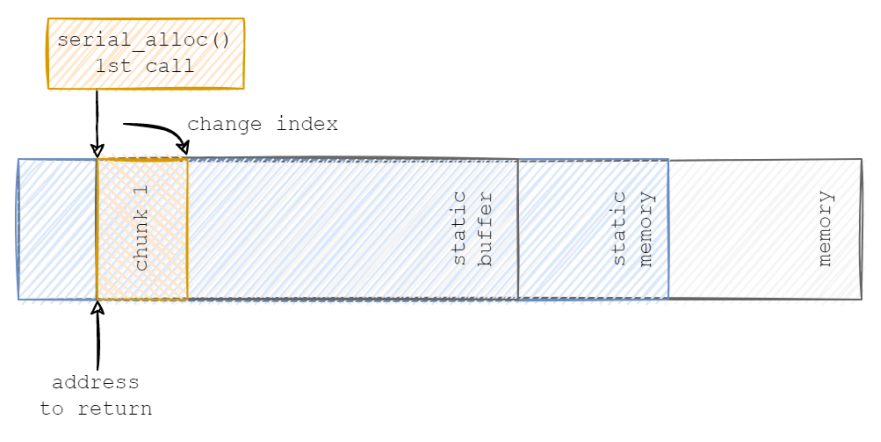
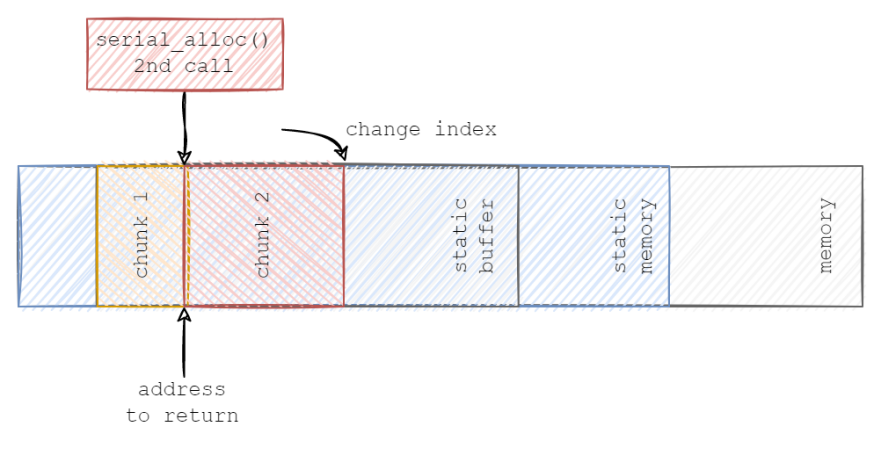
在第二次调用时,它会重新计算next_free_index的值,并返回地址给下一块数据。下图展示了其对应的逻辑:
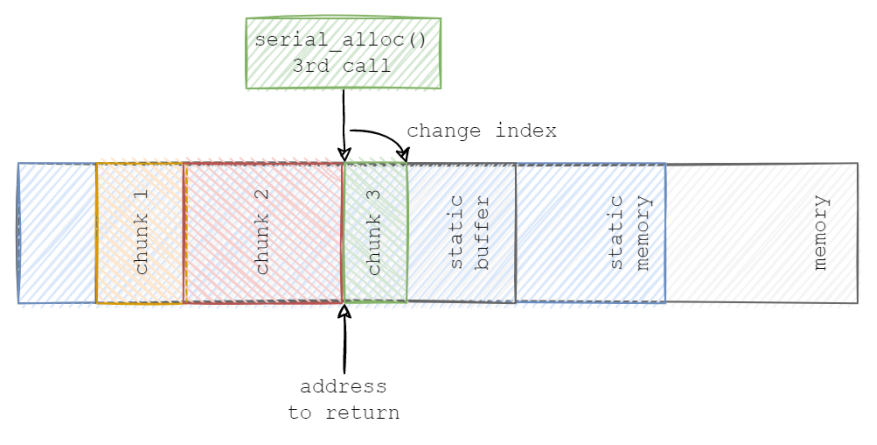
下图展示了第三次调用的逻辑:
而serial_free()函数会将使用缓冲区空间设置为零。请参见如下代码:
C
static void serial_free(void* allocator_data, void* ignored)
{
(void)ignored;
unpacked_message_wrapper* wrapper = (unpacked_message_wrapper*)allocator_data;
wrapper->next_free_index = 0;
}
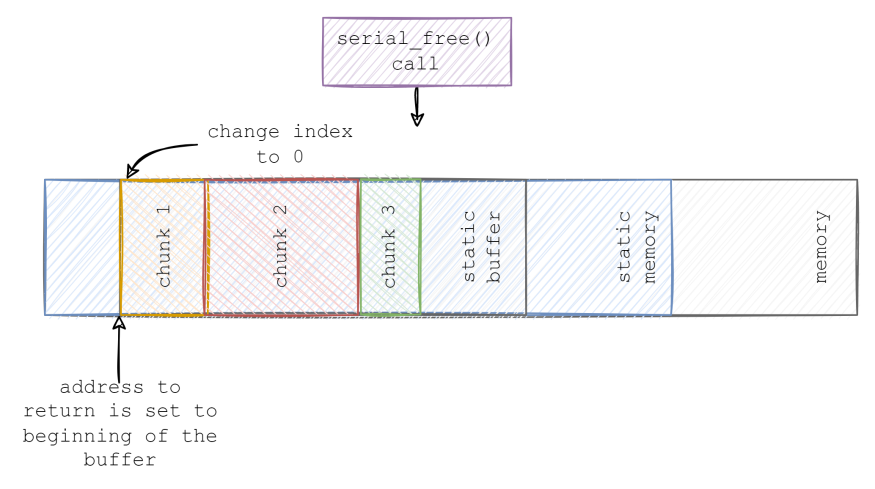
当serial_free()被调用时,它会通过设置next_free_index为零,以“释放”所有内存,好让缓冲区可以被重用。请参见下图:
对实现予以测试
我们可以使用知名的运行时诊断工具—Valgrind,通过如下命令来运行上述程序:
Shell
valgrind ./protobuf-c-custom_allocator
在下面生成的报告中,您会发现并无任何分配的出现:
Plain Text
==3977== Memcheck, a memory error detector
==3977== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==3977== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info
==3977== Command: ./protobuf-c-custom_allocator
==3977==
==3977==
==3977== HEAP SUMMARY:
==3977== in use at exit: 0 bytes in 0 blocks
==3977== total heap usage: 0 allocs, 0 frees, 0 bytes allocated
==3977==
==3977== All heap blocks were freed -- no leaks are possible
==3977==
==3977== For lists of detected and suppressed errors, rerun with: -s
==3977== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
提示和技巧
如果您手头的项目是一个内存受限的系统,那么您需要事先在serial_alloc中确定MAX_UNPACKED_MESSAGE_LENGTH的大小。请参见如下代码:
C
static void* serial_alloc(void* allocator_data, size_t size)
{
static int call_counter = 0;
static size_t needed_space_counter = 0;
needed_space_counter += ((size + sizeof(int)) & ~(sizeof(int)));
printf("serial_alloc() called for: %d time. Needed space for worst case scenario is = %ld\n", ++call_counter, needed_space_counter);
...
在上例中,我们得到了:
Plain Text
serial_alloc called for: 1 time. The needed space for the worst-case scenario is = 32
而当.proto message变得更加复杂时,我们可以为其添加一个新字段。请参见如下代码:
ProtoBuf
syntax = "proto3";
message Message
{
bool flag = 1;
float value = 2;
repeated string names = 3; // added field, type repeated means "dynamic array"
}
然后,我们再为message添加各种新的属性:
C
int main()
{
Message in;
message__init(&in);
in.flag = true;
in.value = 1.234f;
const char name1[] = "Let's";
const char name2[] = "Solve";
const char name3[] = "It";
const char* names[] = {name1, name2, name3};
in.names = (char**)names;
in.n_names = 3;
// Serialization:
message__pack(&in, pack_buffer);
...
下面便是我们能够看到的输出:
Plain Text
serial_alloc() called for: 1 time. Needed space for worst case scenario is = 48
serial_alloc() called for: 2 time. Needed space for worst case scenario is = 72
serial_alloc() called for: 3 time. Needed space for worst case scenario is = 82
serial_alloc() called for: 4 time. Needed space for worst case scenario is = 92
serial_alloc() called for: 5 time. Needed space for worst case scenario is = 95
由结果可知,我们至少需要一个95字节的缓冲区。而且在真实项目中,您往往需要比95字节更多的空间。
小结
综上所述,若要编写和使用一个定制的分配器,您需要:
- 确定用来存储数据的方式。
- 编写一些针对原型消息类型的包装器,并提供适当的alloc()和free()函数的替换。
- 为包装器创建一个对象。
- 使用alloc()和free()的替换来创建ProtobufCAllocator,然后在x_unpack()函数使用分配器。
对应地,在上面的例子中,我们实现了:
- 连续地存储数据,并静态地分配内存块。
- 编写了unpacked_message_wrapper作为原型Message和buffer的包装器,提供serial_alloc()和serial_free()作为alloc()和free()的替换。
- 在内存栈中,创建了一个unpacked_message_wrapper对象,并命名为out。
- 在unpack_to_message_wrapper_from_buffer中,我们创建了一个ProtobufCAllocator,并将serial_alloc()和serial_free()放入其中,进而传递给message__unpack函数。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:What Are Protocol Buffers?,作者:Mateusz Patyk