目录
- 1、页缓存技术 + 磁盘顺序写
- 2、零拷贝技术
- 3、最后的总结
这篇文章来聊一下Kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。
1、页缓存技术 + 磁盘顺序写
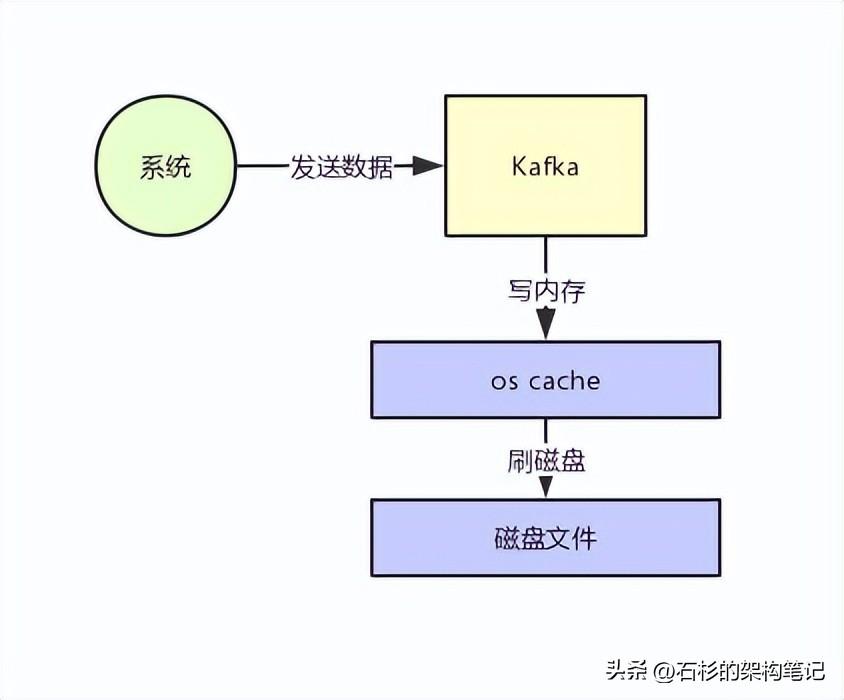
首先Kafka每次接收到数据都会往磁盘上去写,如下图所示。
那么在这里我们不禁有一个疑问了,如果把数据基于磁盘来存储,频繁的往磁盘文件里写数据,这个性能会不会很差?大家肯定都觉得磁盘写性能是极差的。
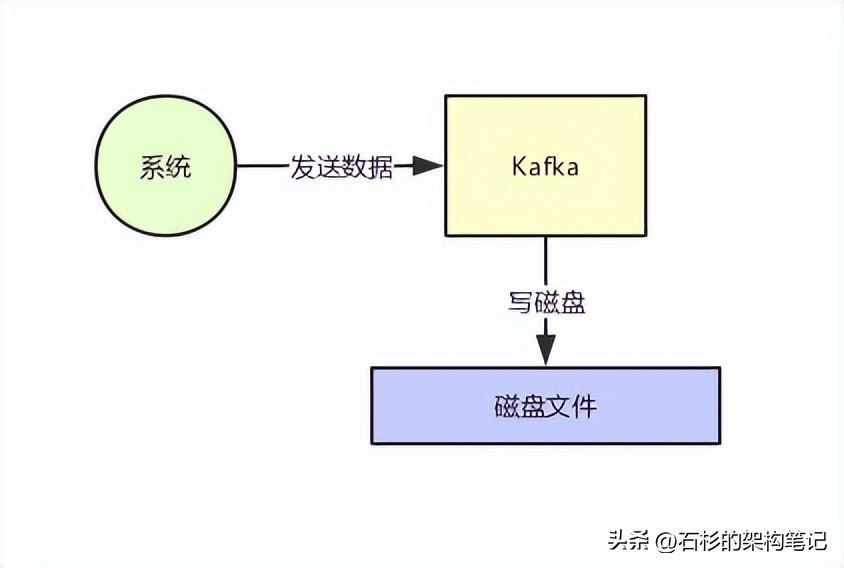
没错,要是真的跟上面那个图那么简单的话,那确实这个性能是比较差的。
但是实际上Kafka在这里有极为优秀和出色的设计,就是为了保证数据写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。
你在写入磁盘文件的时候,可以直接写入这个os cache里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把os cache里的数据真的刷入磁盘文件中。
仅仅这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,大家看下图。
接着另外一个就是kafka写数据的时候,非常关键的一点,他是以磁盘顺序写的方式来写的。也就是说,仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
普通的机械磁盘如果你要是随机写的话,确实性能极差,也就是随便找到文件的某个位置来写数据。
但是如果你是追加文件末尾按照顺序的方式来写数据的话,那么这种磁盘顺序写的性能基本上可以跟写内存的性能本身也是差不多的。
所以大家就知道了,上面那个图里,Kafka在写数据的时候,一方面基于了os层面的page cache来写数据,所以性能很高,本质就是在写内存罢了。
另外一个,他是采用磁盘顺序写的方式,所以即使数据刷入磁盘的时候,性能也是极高的,也跟写内存是差不多的。
基于上面两点,kafka就实现了写入数据的超高性能。
那么大家想想,假如说kafka写入一条数据要耗费1毫秒的时间,那么是不是每秒就是可以写入1000条数据?
但是假如kafka的性能极高,写入一条数据仅仅耗费0.01毫秒呢?那么每秒是不是就可以写入10万条数?
所以要保证每秒写入几万甚至几十万条数据的核心点,就是尽最大可能提升每条数据写入的性能,这样就可以在单位时间内写入更多的数据量,提升吞吐量。
2、零拷贝技术
说完了写入这块,再来谈谈消费这块。
大家应该都知道,从Kafka里我们经常要消费数据,那么消费的时候实际上就是要从kafka的磁盘文件里读取某条数据然后发送给下游的消费者,如下图所示。
那么这里如果频繁的从磁盘读数据然后发给消费者,性能瓶颈在哪里呢?
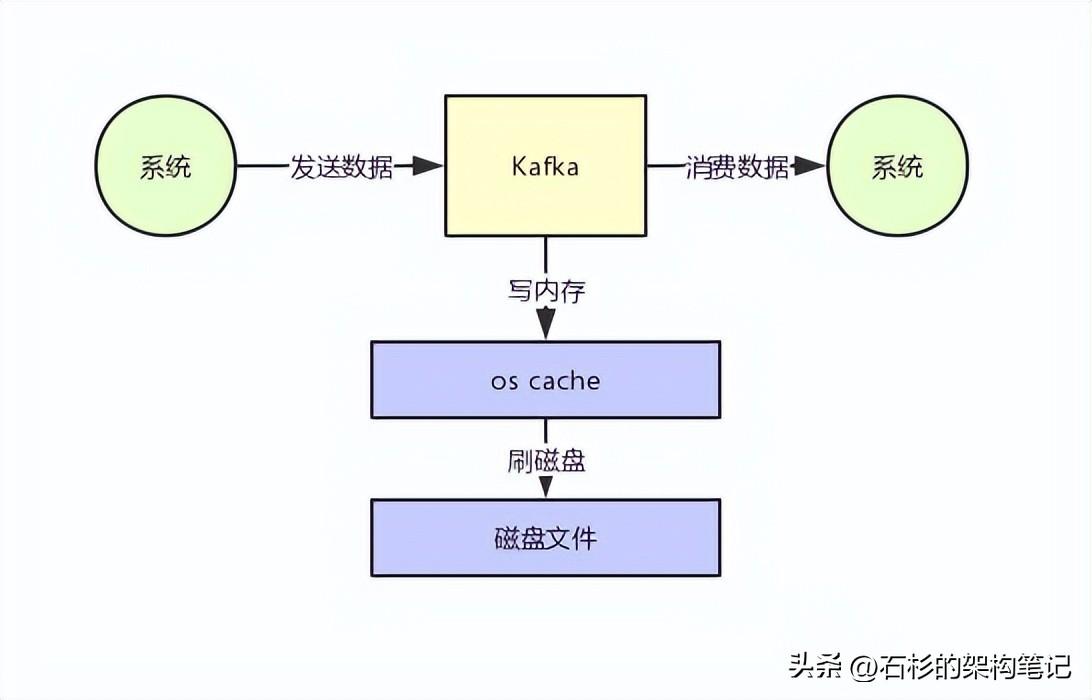
假设要是kafka什么优化都不做,就是很简单的从磁盘读数据发送给下游的消费者,那么大概过程如下所示:
先看看要读的数据在不在os cache里,如果不在的话就从磁盘文件里读取数据后放入os cache。
接着从操作系统的os cache里拷贝数据到应用程序进程的缓存里,再从应用程序进程的缓存里拷贝数据到操作系统层面的Socket缓存里,最后从Socket缓存里提取数据后发送到网卡,最后发送出去给下游消费。
整个过程,如下图所示:
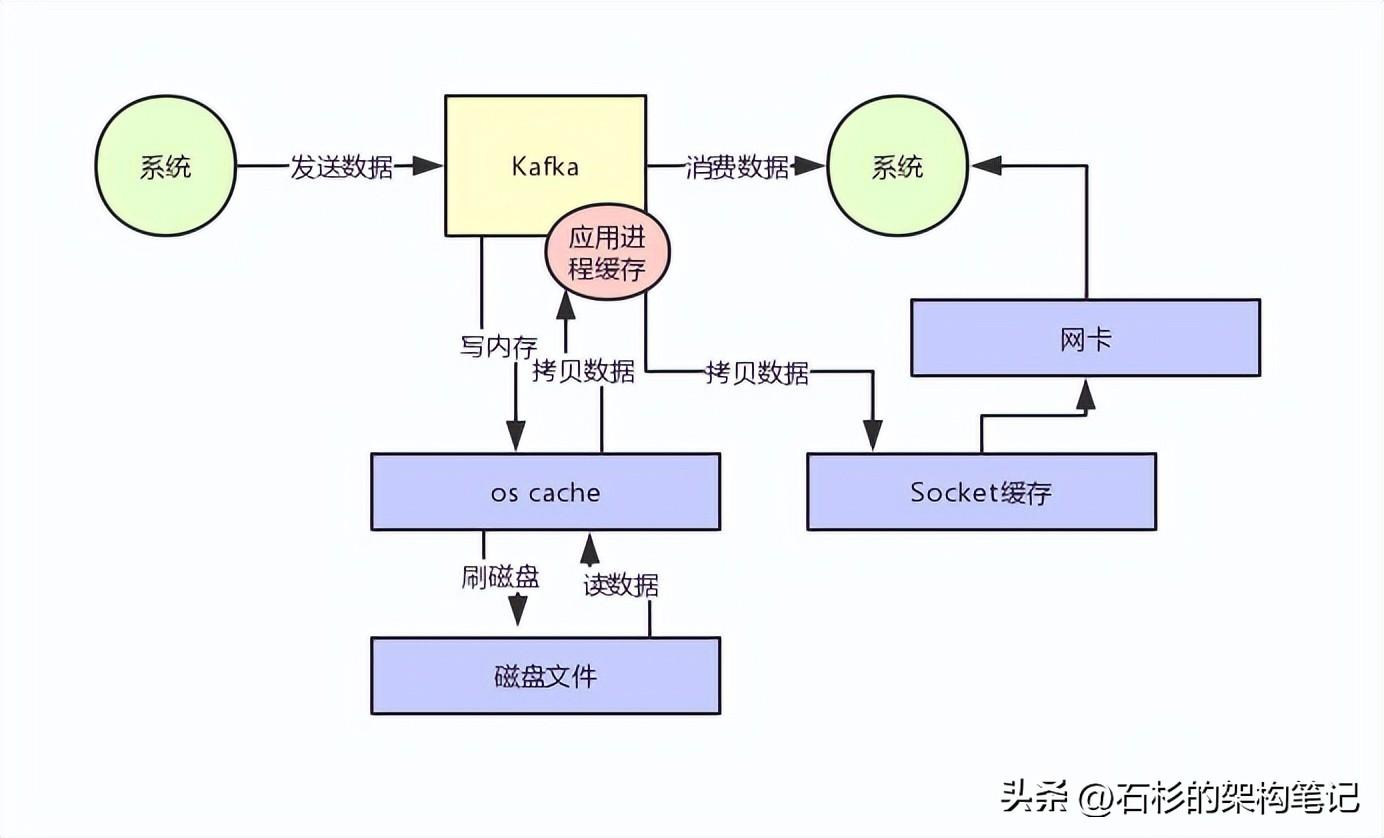
大家看上图,很明显可以看到有两次没必要的拷贝吧!
一次是从操作系统的cache里拷贝到应用进程的缓存里,接着又从应用程序缓存里拷贝回操作系统的Socket缓存里。
而且为了进行这两次拷贝,中间还发生了好几次上下文切换,一会儿是应用程序在执行,一会儿上下文切换到操作系统来执行。
所以这种方式来读取数据是比较消耗性能的。
Kafka为了解决这个问题,在读数据的时候是引入零拷贝技术。
也就是说,直接让操作系统的cache中的数据发送到网卡后传输给下游的消费者,中间跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存。
大家看下图,体会一下这个精妙的过程:
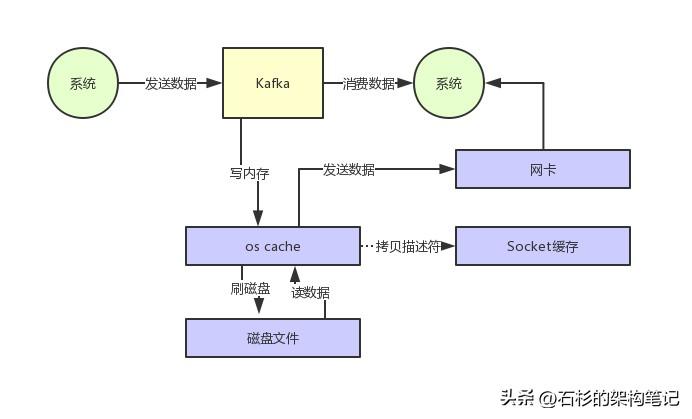
通过零拷贝技术,就不需要把os cache里的数据拷贝到应用缓存,再从应用缓存拷贝到Socket缓存了,两次拷贝都省略了,所以叫做零拷贝。
对Socket缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从os cache中发送到网卡上去了,这个过程大大的提升了数据消费时读取文件数据的性能。
而且大家会注意到,在从磁盘读数据的时候,会先看看os cache内存中是否有,如果有的话,其实读数据都是直接读内存的。
如果kafka集群经过良好的调优,大家会发现大量的数据都是直接写入os cache中,然后读数据的时候也是从os cache中读。
相当于是Kafka完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
3、最后的总结
通过这篇文章对kafka底层的页缓存技术的使用,磁盘顺序写的思路,以及零拷贝技术的运用,大家应该就明白Kafka每台机器在底层对数据进行写和读的时候采取的是什么样的思路,为什么他的性能可以那么高,做到每秒几十万的吞吐量。
这种设计思想对我们平时自己设计中间件的架构,或者是出去面试的时候,都有很大的帮助。