IO Pipeline 不算什么新鲜事儿,通过 io.Reader io.Writer 等接口,把多个流处理连接一起,只需返回 Reader, 直到调用 Read 函数时才读数据,高效节约内存。类比 Spark 流处理,transformation 时只是传递 RDD, 只有 Action 时才会触发数据计算。

JSON Decoder 例子
举一个从 http 读取 json 数据的例子:
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
request := new(Person)
decoder := json.NewDecoder(r.Body)
err := decoder.Decode(&request)
if err != nil {
http.Error(w, err)
}
......
})
我们不需要 ioutil.ReadAll 全部 body 再调用 Unmarshal, decoder 内置 buffer 流式解析即可。但是这个例子不完美,有很多问题
- 如果 client 传入的 json 有未识别的字段,服务端如何处理?
- json.NewDecoder 会一直读 r.Body, 未做长度限制
- 没有检查Content-Type header, 只有 json 才允许 Decode
- 错误处理不够好,error 需要转换,不能直接返回 client
func decodeJSONBody(w http.ResponseWriter, r *http.Request, dst interface{}) error {
if r.Header.Get("Content-Type") != "" {
value, _ := header.ParseValueAndParams(r.Header, "Content-Type")
if value != "application/json" {
msg := "Content-Type header is not application/json"
return &malformedRequest{status: http.StatusUnsupportedMediaType, msg: msg}
}
}
r.Body = http.MaxBytesReader(w, r.Body, 1048576)
dec := json.NewDecoder(r.Body)
dec.DisallowUnknownFields()
err := dec.Decode(&dst)
if err != nil {
var syntaxError *json.SyntaxError
var unmarshalTypeError *json.UnmarshalTypeError
switch {
case errors.As(err, &syntaxError):
msg := fmt.Sprintf("Request body contains badly-formed JSON (at position %d)", syntaxError.Offset)
return &malformedRequest{status: http.StatusBadRequest, msg: msg}
......
}
}
err = dec.Decode(&struct{}{})
if err != io.EOF {
msg := "Request body must only contain a single JSON object"
return &malformedRequest{status: http.StatusBadRequest, msg: msg}
}
}
上面是改进后的版本,看着舒服多了,这还只是一个 reader 的实现。在 minio 中,经常有 N 多个 io.Reader 或者 io.Writer 组合在一起,实现 io pipeline, 稍复杂一些
Minio 下载数据
略去错误处理,只看 getObjectHandler 主干代码
func (api objectAPIHandlers) getObjectHandler(ctx context.Context, objectAPI ObjectLayer, bucket, object string, w http.ResponseWriter, r *http.Request) {
......
gr, err := getObjectNInfo(ctx, bucket, object, rs, r.Header, readLock, opts)
......
httpWriter := xioutil.WriteOnClose(w)
if rs != nil || opts.PartNumber > 0 {
statusCodeWritten = true
w.WriteHeader(http.StatusPartialContent)
}
// Write object content to response body
if _, err = xioutil.Copy(httpWriter, gr); err != nil {
......
}
......
}
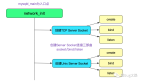
getObjectNInfo 调用后端具体实现,返回 GetObjectReader gr, 从 gr 中读取数据写回 http Writer ...
gr 实现有很多种,minio 支持 NAS,FS, EC 多种模式,可以从文件系统中读数据,可以从 remote http 中读取
1. FS 本地文件系统下载数据
GetObjectNInfo 定义在 fs-v1.go, 原理比较简单, 根据 header 获取要读取文件的 offset, length 组装后返回 objReaderFn
func (fs *FSObjects) GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, lockType LockType, opts ObjectOptions) (gr *GetObjectReader, err error) {
......
objReaderFn, off, length, err := NewGetObjectReader(rs, objInfo, opts)
if err != nil {
......
return nil, err
}
// Read the object, doesn't exist returns an s3 compatible error.
fsObjPath := pathJoin(fs.fsPath, bucket, object)
readCloser, size, err := fsOpenFile(ctx, fsObjPath, off)
if err != nil {
......
return nil, err
}
closeFn := func() {
readCloser.Close()
}
reader := io.LimitReader(readCloser, length)
// Check if range is valid
if off > size || off+length > size {
......
return nil, err
}
return objReaderFn(reader, h, closeFn, rwPoolUnlocker, nsUnlocker)
}
NewGetObjectReader 代码会处理压缩或者加密的场景,内部还会构建 reader. fsOpenFile 打开文件后,还要封装一层 io.LimitReader 获取指定长度的数据
func NewGetObjectReader(rs *HTTPRangeSpec, oi ObjectInfo, opts ObjectOptions) (
fn ObjReaderFn, off, length int64, err error,
) {
......
// Calculate range to read (different for encrypted/compressed objects)
switch {
case isCompressed:
......
case isEncrypted:
......
// We define a closure that performs decryption given
// a reader that returns the desired range of
// encrypted bytes. The header parameter is used to
// provide encryption parameters.
fn = func(inputReader io.Reader, h http.Header, cFns ...func()) (r *GetObjectReader, err error) {
copySource := h.Get(xhttp.AmzServerSideEncryptionCopyCustomerAlgorithm) != ""
// Attach decrypter on inputReader
var decReader io.Reader
decReader, err = DecryptBlocksRequestR(inputReader, h, seqNumber, partStart, oi, copySource)
if err != nil {
// Call the cleanup funcs
for i := len(cFns) - 1; i >= 0; i-- {
cFns[i]()
}
return nil, err
}
oi.ETag = getDecryptedETag(h, oi, false)
// Apply the skipLen and limit on the
// decrypted stream
decReader = io.LimitReader(ioutil.NewSkipReader(decReader, skipLen), decRangeLength)
// Assemble the GetObjectReader
r = &GetObjectReader{
ObjInfo: oi,
Reader: decReader,
cleanUpFns: cFns,
opts: opts,
}
return r, nil
}
default:
off, length, err = rs.GetOffsetLength(oi.Size)
if err != nil {
return nil, 0, 0, err
}
fn = func(inputReader io.Reader, _ http.Header, cFns ...func()) (r *GetObjectReader, err error) {
r = &GetObjectReader{
ObjInfo: oi,
Reader: inputReader,
cleanUpFns: cFns,
opts: opts,
}
return r, nil
}
}
return fn, off, length, nil
}
switch 分支会处理 isCompressed, isEncrypted, default 三种场景,区别是需要重新计算文件的 offset, length 然后再封装对应的 io.Reader ...
2. EC 多机纠删码下载数据
func (er erasureObjects) GetObjectNInfo(ctx context.Context, bucket, object string, rs *HTTPRangeSpec, h http.Header, lockType LockType, opts ObjectOptions) (gr *GetObjectReader, err error) {
......
fi, metaArr, onlineDisks, err := er.getObjectFileInfo(ctx, bucket, object, opts, true)
if err != nil {
return nil, toObjectErr(err, bucket, object)
}
if !fi.DataShardFixed() {
diskMTime := pickValidDiskTimeWithQuorum(metaArr, fi.Erasure.DataBlocks)
if !diskMTime.Equal(timeSentinel) && !diskMTime.IsZero() {
for index := range onlineDisks {
if onlineDisks[index] == OfflineDisk {
continue
}
if !metaArr[index].IsValid() {
continue
}
if !metaArr[index].AcceptableDelta(diskMTime, shardDiskTimeDelta) {
// If disk mTime mismatches it is considered outdated
// https://github.com/minio/minio/pull/13803
//
// This check only is active if we could find maximally
// occurring disk mtimes that are somewhat same across
// the quorum. Allowing to skip those shards which we
// might think are wrong.
onlineDisks[index] = OfflineDisk
}
}
}
}
......
fn, off, length, err := NewGetObjectReader(rs, objInfo, opts)
if err != nil {
return nil, err
}
unlockOnDefer = false
pr, pw := xioutil.WaitPipe()
go func() {
pw.CloseWithError(er.getObjectWithFileInfo(ctx, bucket, object, off, length, pw, fi, metaArr, onlineDisks))
}()
// Cleanup function to cause the go routine above to exit, in
// case of incomplete read.
pipeCloser := func() {
pr.CloseWithError(nil)
}
return fn(pr, h, pipeCloser, nsUnlocker)
}
与 fs 本地文件系统的区别在于,需要从多个 onlineDisks 中读取数据,并且可能是 remote 网络请求
这里用到了 xioutil.WaitPipe 底层是对 io.Pipe 的封装,getObjectWithFileInfo 把数据写入 pw 管道,上层调用 Read 从 pr 管道中读取数据
func (er erasureObjects) getObjectWithFileInfo(ctx context.Context, bucket, object string, startOffset int64, length int64, writer io.Writer, fi FileInfo, metaArr []FileInfo, onlineDisks []StorageAPI) error {
// Reorder online disks based on erasure distribution order.
// Reorder parts metadata based on erasure distribution order.
onlineDisks, metaArr = shuffleDisksAndPartsMetadataByIndex(onlineDisks, metaArr, fi)
......
var totalBytesRead int64
erasure, err := NewErasure(ctx, fi.Erasure.DataBlocks, fi.Erasure.ParityBlocks, fi.Erasure.BlockSize)
if err != nil {
return toObjectErr(err, bucket, object)
}
var healOnce sync.Once
// once we have obtained a common FileInfo i.e latest, we should stick
// to single dataDir to read the content to avoid reading from some other
// dataDir that has stale FileInfo{} to ensure that we fail appropriately
// during reads and expect the same dataDir everywhere.
dataDir := fi.DataDir
for ; partIndex <= lastPartIndex; partIndex++ {
if length == totalBytesRead {
break
}
partNumber := fi.Parts[partIndex].Number
// Save the current part name and size.
partSize := fi.Parts[partIndex].Size
partLength := partSize - partOffset
// partLength should be adjusted so that we don't write more data than what was requested.
if partLength > (length - totalBytesRead) {
partLength = length - totalBytesRead
}
tillOffset := erasure.ShardFileOffset(partOffset, partLength, partSize)
// Get the checksums of the current part.
readers := make([]io.ReaderAt, len(onlineDisks))
prefer := make([]bool, len(onlineDisks))
for index, disk := range onlineDisks {
if disk == OfflineDisk {
continue
}
if !metaArr[index].IsValid() {
continue
}
checksumInfo := metaArr[index].Erasure.GetChecksumInfo(partNumber)
partPath := pathJoin(object, dataDir, fmt.Sprintf("part.%d", partNumber))
readers[index] = newBitrotReader(disk, metaArr[index].Data, bucket, partPath, tillOffset,
checksumInfo.Algorithm, checksumInfo.Hash, erasure.ShardSize())
// Prefer local disks
prefer[index] = disk.Hostname() == ""
}
written, err := erasure.Decode(ctx, writer, readers, partOffset, partLength, partSize, prefer)
// Note: we should not be defer'ing the following closeBitrotReaders() call as
// we are inside a for loop i.e if we use defer, we would accumulate a lot of open files by the time
// we return from this function.
closeBitrotReaders(readers)
if err != nil {
// If we have successfully written all the content that was asked
// by the client, but we still see an error - this would mean
// that we have some parts or data blocks missing or corrupted
// - attempt a heal to successfully heal them for future calls.
if written == partLength {
var scan madmin.HealScanMode
switch {
case errors.Is(err, errFileNotFound):
scan = madmin.HealNormalScan
case errors.Is(err, errFileCorrupt):
scan = madmin.HealDeepScan
}
switch scan {
case madmin.HealNormalScan, madmin.HealDeepScan:
healOnce.Do(func() {
if _, healing := er.getOnlineDisksWithHealing(); !healing {
go healObject(bucket, object, fi.VersionID, scan)
}
})
// Healing is triggered and we have written
// successfully the content to client for
// the specific part, we should `nil` this error
// and proceed forward, instead of throwing errors.
err = nil
}
}
if err != nil {
return toObjectErr(err, bucket, object)
}
}
for i, r := range readers {
if r == nil {
onlineDisks[i] = OfflineDisk
}
}
// Track total bytes read from disk and written to the client.
totalBytesRead += partLength
// partOffset will be valid only for the first part, hence reset it to 0 for
// the remaining parts.
partOffset = 0
} // End of read all parts loop.
// Return success.
return nil
}
newBitrotReader 封装多个 reader, NewErasure 从 reader 中读数据,调用 Decode 解码读取的数据,如果出现错误,那么需要调用 healObject 尝试修复,理论上 K+M 中至多可以损坏 M 份数据

如上图所示,8 台机器,每台 16 块硬盘,每块硬盘 8T, 总大小 1PB. 如果 strip 条带 K+M=16, 其中 M=4 的情况下,可用空间为 768T,利用率 75%
至多可以损坏 32 块硬盘,或者 2 台机器宕机
小结
上面分析读取,对于上传对象逻辑也同理。Minio 代码整体 20w 行, 涉及到了大部分对象存储的知识,适合入门,值得一读