前言
在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。
下面对该业务诉求的实现,设计思路和方案优化进行介绍,对「千万量级数据中查询 10W 量级的数据」设计了如下方案:
- 多线程 + CK 翻页方案
- ES scroll scan 深翻页方案
- ES + Hbase 组合方案
- RediSearch + RedisJSON 组合方案
一、初版设计方案
整体方案设计为:
- 先根据配置的「筛选规则」,从底池表中筛选出「目标数据」。
- 在根据配置的「排序规则」,对「目标数据」进行排序,得到「结果数据」。
技术方案如下:
- 每天运行导数任务,把现有的千万量级的底池数据(Hive 表)导入到 Clickhouse 中,后续使用 CK 表进行数据筛选。
- 将业务配置的筛选规则和排序规则,构建为一个「筛选 + 排序」对象 SelectionQueryCondition。
- 从 CK 底池表取「目标数据」时,开启多线程,进行分页筛选,将获取到的「目标数据」存放到 result 列表中。
//分页大小 默认 5000
int pageSize = this.getPageSize();
//页码数
int pageCnt = totalNum / this.getPageSize() + 1;
List<Map<String, Object>> result = Lists.newArrayList();
List<Future<List<Map<String, Object>>>> futureList = new ArrayList<>(pageCnt);
//开启多线程调用
for (int i = 1; i <= pageCnt; i++) {
//将业务配置的筛选规则和排序规则 构建为 SelectionQueryCondition 对象
SelectionQueryCondition selectionQueryCondition = buildSelectionQueryCondition(selectionQueryRuleData);
selectionQueryCondition.setPageSize(pageSize);
selectionQueryCondition.setPage(i);
futureList.add(selectionQueryEventPool.submit(new QuerySelectionDataThread(selectionQueryCondition)));
}
for (Future<List<Map<String, Object>>> future : futureList) {
//RPC 调用
List<Map<String, Object>> queryRes = future.get(20, TimeUnit.SECONDS);
if (CollectionUtils.isNotEmpty(queryRes)) {
// 将目标数据存放在 result 中
result.addAll(queryRes);
}
}
- 对目标数据 result 进行排序,得到最终的「结果数据」。
二、CK分页查询
在「初版设计方案」章节的第 3 步提到了「从 CK 底池表取目标数据时,开启多线程,进行分页筛选」。此处对 CK 分页查询进行介绍。
- 封装了 queryPoolSkuList 方法,负责从 CK 表中获得目标数据。该方法内部调用了 sqlSession.selectList 方法。
public List<Map<String, Object>> queryPoolSkuList( Map<String, Object> params ) {
List<Map<String, Object>> resultMaps = new ArrayList<>();
QueryCondition queryCondition = parseQueryCondition(params);
List<Map<String, Object>> mapList = lianNuDao.queryPoolSkuList(getCkDt(),queryCondition);
if (CollectionUtils.isNotEmpty(mapList)) {
for (Map<String,Object> data : mapList) {
resultMaps.add(camelKey(data));
}
}
return resultMaps;
}
// lianNuDao.queryPoolSkuList
@Autowired
@Qualifier("ckSqlNewSession")
private SqlSession sqlSession;
public List<Map<String, Object>> queryPoolSkuList( String dt, QueryCondition queryCondition ) {
queryCondition.setDt(dt);
queryCondition.checkMultiQueryItems();
return sqlSession.selectList("LianNu.queryPoolSkuList",queryCondition);
}
- sqlSession.selectList 方法中调用了和 CK 交互的 queryPoolSkuList 查询方法,部分代码如下。
<select id="queryPoolSkuList" parameterType="com.jd.bigai.domain.liannu.QueryCondition" resultType="java.util.Map">
select sku_pool_id,i
tem_sku_id,
skuPoolName,
price,
businessType
from liannu_sku_pool_indicator_all
where
dt=#{dt}
and
<foreach collection="queryItems" separator=" and " item="queryItem" open=" " close=" " >
<choose>
<when test="queryItem.type == 'equal'">
${queryItem.field} = #{queryItem.value}
</when>
</choose>
</foreach>
<if test="orderBy == null">
group by sku_pool_id,item_sku_id
</if>
<if test="orderBy != null">
group by sku_pool_id,item_sku_id,${orderBy} order by ${orderBy} ${orderAd}
</if>
<if test="limitEnd != 0">
limit #{limitStart},#{limitEnd}
</if>
</select>
- 可以看到,在 CK 分页查询时,是通过 limit #{limitStart},#{limitEnd} 实现的分页。
limit 分页方案,在「深翻页」时会存在性能问题。初版方案上线后,在 1000W 量级的底池数据中筛选 10W 的数据,最坏耗时会达到 10s~18s 左右。
三、使用ES Scroll Scan优化深翻页
对于 CK 深翻页时候的性能问题,进行了优化,使用 Elasticsearch 的 scroll scan 翻页方案进行优化。
1、ES的翻页方案
ES 翻页,有下面几种方案:
- from + size 翻页
- scroll 翻页
- scroll scan 翻页
- search after 翻页

对上述几种翻页方案,查询不同数目的数据,耗时数据如下表。

2、耗时数据
此处,分别使用 Elasticsearch 的 scroll scan 翻页方案、初版中的 CK 翻页方案进行数据查询,对比其耗时数据。
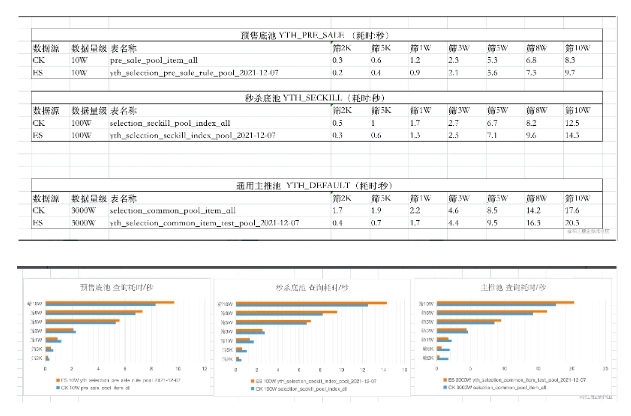
如上测试数据,可以发现,以十万,百万,千万量级的底池为例。
- 底池量级越大,查询相同的数据量,耗时越大。
- 查询结果 3W 以下时,ES 性能优;查询结果 5W 以上时,CK 多线程性能优。
四、ES+Hbase组合查询方案
在「使用 ES Scroll Scan 优化深翻页」中,使用 Elasticsearch 的 scroll scan 翻页方案对深翻页问题进行了优化,但在实现时为单线程调用,所以最终测试耗时数据并不是特别理想,和 CK 翻页方案性能差不多。
在调研阶段发现,从底池中取出 10W 的目标数据时,一个商品包含多个字段的信息(CK 表中一行记录有 150 个字段信息),如价格、会员价、学生价、库存、好评率等。对于一行记录,当减少获取字段的个数时,查询耗时会有明显下降。如对 sku1的商品,从之前获取价格、会员价、学生价、亲友价、库存等 100 个字段信息,缩减到只获取价格、库存这两个字段信息。
如下图所示,使用 ES 查询方案,对查询同样条数的场景(从千万级底池中筛选出 7W+ 条数据),获取的每条记录的字段个数从 32 缩减到 17,再缩减到 1个(其实是两个字段,一个是商品唯一标识 sku_id,另一个是 ES 对每条文档记录的 doc_id)时,查询的耗时会从 9.3s 下降到 4.2s,再下降到 2.4s。

从中可以得出如下结论:
- 一次 ES 查询中,若查询字段和信息较多,fetch 阶段的耗时,远大于 query 阶段的耗时。
- 一次 ES 查询中,若查询字段和信息较多,通过减少不必要的查询字段,可以显著缩短查询耗时。
下面对结论中涉及的 query 和 fetch 查询阶段进行补充说明。
1、ES查询的两个阶段:query和fetch
在 ES 中,搜索一般包括两个阶段,query 和 fetch 阶段。
- query 阶段
根据查询条件,确定要取哪些文档(doc),筛选出文档 ID(doc_id)。
- fetch 阶段
根据 query 阶段返回的文档 ID(doc_id),取出具体的文档(doc)。
2、ES的filesystem cache
1)ES 会将磁盘中的数据自动缓存到 filesystem cache,在内存中查找,提升了速度。
2)若 filesystem cache 无法容纳索引数据文件,则会基于磁盘查找,此时查询速度会明显变慢。
3)若数量两过大,基于「ES 查询的的 query 和 fetch 两个阶段」,可使用 ES + HBase 架构,保证 ES 的数据量小于 filesystem cache,保证查询速度。
3、组合使用Hbase
在上文调研的基础上,发现「减少不必要的查询展示字段」可以明显缩短查询耗时。沿着这个优化思路,参考相关资料设计了一种新的查询方案。
- ES 仅用于条件筛选,ES 的查询结果仅包含记录的唯一标识 sku_id(其实还包含 ES 为每条文档记录的 doc_id)。
- Hbase 是列存储数据库,每列数据有一个 rowKey。利用 rowKey 筛选一条记录时,复杂度为 O(1)。(类似于从 HashMap 中根据 key 取 value)。
- 根据 ES 查询返回的唯一标识 sku_id,作为 Hbase 查询中的 rowKey,在 O(1) 复杂度下获取其他信息字段,如价格,库存等。

使用 ES + Hbase 组合查询方案,在线上进行了小规模的灰度测试。在 1000W 量级的底池数据中筛选 10W 的数据,对比 CK 翻页方案,最坏耗时从 10~18s 优化到了 3~6s 左右。
也应该看到,使用 ES + Hbase 组合查询方案,会增加系统复杂度,同时数据也需要同时存储到 ES 和 Hbase。
五、RediSearch+RedisJSON优化方案
RediSearch 是基于 Redis 构建的分布式全文搜索和聚合引擎,能以极快的速度在 Redis 数据集上执行复杂的搜索查询。RedisJSON 是一个 Redis 模块,在 Redis 中提供 JSON 支持。RedisJSON 可以和 RediSearch 无缝配合,实现索引和查询 JSON 文档。
根据一些参考资料,RediSearch + RedisJSON 可以实现极高的性能,可谓碾压其他 NoSQL 方案。在后续版本迭代中,可考虑使用该方案来进一步优化。
下面给出 RediSearch + RedisJSON 的部分性能数据。
1、RediSearch 性能数据
在同等服务器配置下索引了 560 万个文档 (5.3GB),RediSearch 构建索引的时间为 221 秒,而 Elasticsearch 为 349 秒。RediSearch 比 ES 快了 58%。
数据建立索引后,使用 32 个客户端对两个单词进行检索,RediSearch 的吞吐量达到 12.5K ops/sec,ES 的吞吐量为 3.1K ops/sec,RediSearch 比ES 要快 4 倍。同时,RediSearch 的延迟为 8ms,而 ES 为 10ms,RediSearch 延迟稍微低些。

2、RedisJSON 性能数据
根据官网的性能测试报告,RedisJson + RedisSearch 可谓碾压其他 NoSQL。
- 对于隔离写入(isolated writes),RedisJSON 比 MongoDB 快 5.4 倍,比 ES 快 200 倍以上。
- 对于隔离读取(isolated reads),RedisJSON 比 MongoDB 快 12.7 倍,比 ES 快 500 倍以上。
在混合工作负载场景中,实时更新不会影响 RedisJSON 的搜索和读取性能,而 ES 会受到影响。
- RedisJSON 支持的操作数/秒比 MongoDB 高约 50 倍,比 ES 高 7 倍/秒。
- RedisJSON 的延迟比 MongoDB 低约 90 倍,比 ES 低 23.7 倍。
此外,RedisJSON 的读取、写入和负载搜索延迟,在更高的百分位数中远比 ES 和 MongoDB 稳定。当增加写入比率时,RedisJSON 还能处理越来越高的整体吞吐量。而当写入比率增加时,ES 会降低它可以处理的整体吞吐量。
总结
本文从一个业务诉求触发,对「千万量级数据中查询 10W 量级的数据」介绍了不同的设计方案。对于「在 1000W 量级的底池数据中筛选 10W 的数据」的场景,不同方案的耗时如下:
- 多线程 + CK 翻页方案,最坏耗时为 10s~18s。
- 单线程 + ES scroll scan 深翻页方案,相比 CK 方案,并未见到明显优化。
- ES + Hbase 组合方案,最坏耗时优化到了 3s~6s。
- RediSearch + RedisJSON 组合方案,后续会实测该方案的耗时。