前言
什么是 AI?在你的脑海中可能浮现由一个个神经元堆叠起来的神经网络。那什么是绘画艺术?是达芬奇的《蒙娜丽莎的微笑》,是梵高的《星空夜》、《向日葵》,还是约翰内斯·维米尔的《戴珍珠耳环的少女》?当 AI 遇上绘画艺术,它们之间能擦出什么样的火花呢?
2021年初,OpenAI 团队发布了能够根据文本描述生成图像的 DALL-E 模型。由于其强大的跨模态图像生成能力,引起自然语言和视觉圈技术爱好者的强烈追捧。仅仅一年多的时间,多模态图像生成技术如雨后春笋般开始涌现,期间也诞生了许多利用这些技术进行 AI 艺术创作的应用,比如最近火得一塌糊涂的 Disco Diffusion。如今,这些应用正逐渐走进艺术创作者和普通大众的视野,成为了很多人口中的“神笔马良”。
本文从技术兴趣出发,对多模态图像生成技术与经典工作进行介绍,最后探索如何使用多模态图像生成进行神奇的 AI 绘画艺术创作。 笔者使用 Disco Diffusion 创作的 AI 绘画艺术作品
笔者使用 Disco Diffusion 创作的 AI 绘画艺术作品
多模态图像生成概念
多模态图像生成(Multi-Modal Image Generation)旨在利用文本、音频等模态信息作为指导条件,生成具有自然纹理的逼真图像。不像传统的根据噪声生成图像的单模态生成技术,多模态图像生成一直以来就是一件很有挑战的任务,要解决的问题主要包括:
(1)如何跨越“语义鸿沟”,打破各模态之间固有的隔阂?
(2)如何生成合乎逻辑的,多样性的,且高分辨率的图像?近两年,随着 Transformer 在自然语言处理(如 GPT)、计算机视觉(如 ViT)、多模态预训练(如 CLIP)等领域的成功应用,以及以 VAE、GAN 为代表的图像生成技术有逐渐被后起之秀——扩散模型(Diffusion Model)赶超之势,多模态图像生成的发展一发不可收拾。
多模态图像生成技术与经典工作
分类
按照训练方式采用的是 Transformer 自回归还是扩散模型的方式,近两年多模态图像生成重点工作分类如下:

Transformer 自回归
采取 Transformer 自回归方式的做法往往将文本和图像分别转化成 tokens 序列,然后利用生成式的 Transformer 架构从文本序列(和可选图像序列)中预测图像序列,最后使用图像生成技术(VAE、GAN等)对图像序列进行解码,得到最终生成图像。以 DALL-E (OpenAI)[1] 为例:

图像和文本通过各自编码器转化成序列,拼接到一起送入到 Transformer(这里用的是 GPT3)进行自回归序列生成。在推理阶段,使用预训练好的 CLIP 计算文本与生成图像的相似度,进行排序后得到最终生成图像的输出。与 DALL-E 类似,清华的 CogView 系列 [2, 3] 与百度的 ERNIE-ViLG [4] 同样使用 VQ-VAE + Transformer 的架构设计,谷歌的 Parti [5] 则将图像编解码器换成了 ViT-VQGAN。而微软的 NUWA-Infinity [6] 使用自回归方式可以做到无限视觉生成。
扩散模型
扩散模型(Diffusion Model)是一种图像生成技术,最近一年发展迅速,被喻为 GAN 的终结者。如图所示,扩散模型分为两阶段:(1)加噪:沿着扩散的马尔可夫链过程,逐渐向图像中添加随机噪声;(2)去噪:学习逆扩散过程恢复图像。常见变体有去噪扩散概率模型(DDPM)等。

采取扩散模型方式的多模态图像生成做法,主要是通过带条件引导的扩散模型学习文本特征到图像特征的映射,并对图像特征进行解码得到最终生成图像。以 DALL-E-2(OpenAI)[7] 举例,其虽然是 DALL-E 的续作,但是采取的技术路线与 DALL-E 截然不同,其原理更像是 GLIDE [8](有人称 GLIDE 为 DALL-E-1.5)。DALL-E-2 的整体架构如图所示:

DALL-E-2 使用 CLIP 对文本进行编码,并使用扩散模型学习一个先验(prior)过程,得到文本特征到图像特征的一个映射;最后学习一个反转 CLIP 的过程,将图像特征解码成最终的图像。相比于 DALL-E-2,谷歌的 Imagen [9] 则使用预训练好的 T5-XXL 来取代 CLIP 进行文本编码,然后使用超分扩散模型(U-Net 架构)增大图像尺寸,得到 1024✖️1024 高清的生成图像。
小结
自回归 Transformer 的引入与 CLIP 对比学习的方式,建立了文本和图像之间的桥梁;同时基于带条件引导的扩散模型,为生成多样性且高分辨率的图像奠定了基础。然而,评估图像生成质量往往带有主观因素,因此在这里比较 Transformer 自回归还是扩散模型的技术谁更胜一筹是一件困难的事情。并且像 DALL-E 系列、Imagen 以及 Parti 等模型在大规模数据集上训练,使用会存在伦理问题以及社会偏见,因此这些模型尚未开源。但是还是有很多爱好者在尝试使用其中的技术,期间也产生了很多可玩的应用。
AI 艺术创作
多模态图像生成技术的发展,为 AI 艺术创作提供了更多的可能。目前,被广泛使用的 AI 创作应用及工具包括 CLIPDraw,VQGAN-CLIP,Disco Diffusion,DALL-E Mini,Midjourney(需被邀请资格),DALL-E-2(需内测资格),Dream By Wombo(App),Meta ”Make-A-Scene”,Tiktok “AI 绿幕” 功能,Stable Diffusion [10],百度“一格”等。本文主要利用在艺术创作圈火爆的 Disco Diffusion 进行 AI 艺术创作。
Disco Diffusion 简介
Disco Diffusion [11] 是一个在 Github 上由众多技术爱好者共同维护的 AI 艺术创作应用,目前已经迭代了多个版本。从 Disco Diffusion 的名字不难看出,其采用的技术主要是用 CLIP 引导的扩散模型。Disco Diffusion 可以根据指定的文本描述(和可选底图)来生成艺术图像或视频。比如输入“花海”,模型就会随机产生一张噪声图像,通过 Diffusion 的去噪扩散过程一步步迭代,达到一定步数后就能渲染出一张美丽的图像。得益于扩散模型多样化的生成方式,每次运行程序都会得到不同的图像,这种“开盲盒”的体验着实让人着迷。
Disco Diffsion 存在问题
基于多模态图像生成模型 Disco Diffusion(DD)进行 AI 创作目前存在以下几个问题:
(1)生成图像质量参差不齐:根据生成任务的难易程度,粗略估算描述内容较难的生成任务良品率 20%~30%,描述内容较容易的生成任务良品率 60%~70%,大多数任务良品率在 30~40% 之间。
(2)生成速度较慢+内存消耗较大:以迭代 250 steps 生成一张 1280*768 图像为例,需要大约花费 6分钟,以及使用 V100 16G 显存。
(3)严重依赖专家经验:选取一组合适的描述词需要经过大量文本内容试错及权重设置、画家画风及艺术社区的了解以及文本修饰词的选取等;调整参数需要对 DD 包含的 CLIP 引导次数/饱和度/对比度/噪点/切割次数/内外切/梯度大小/对称/... 等概念深刻了解,同时要有一定的美术功底。众多的参数也意味着需要较强的专家经验才能获得一张还不错的生成图像。
技能储备
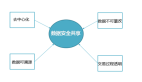
针对上述问题,我们做了一些数据与技术储备,同时 YY 了一些未来可能的应用。如下图所示:

- 针对第一个问题,我们从艺术创作社区爬取了近 2w 张 AI 生成的艺术作品,从生成图像的基础属性以及内容合理性进行三分类打标:质量好/质量一般/质量差,训练一个艺术作品质量评估模型。该模型能自动评估 AI 生成图像的质量并挑选出良品率高的图像,解决手动挑选高质量图像效率低的问题。
- 针对第二个问题,我们通过减少迭代次数+生成小尺寸图像,然后利用超分辨率算法 ESRGAN 进行高分辨率图像重建的方式,来提高 DD 的生成效率。该方法能达到与 DD 正常迭代生成的图像效果,生成效率与显存优化至少提升了一倍。
- 针对第三个问题,我们沉淀了一套底图预处理逻辑,包括色温色调调整/前背景调色/添加噪点等,能快速应用不同底图生成任务;同时,我们也积累了海量的文本提示词,进行了大量的 DD 调参试错,依赖专家经验生成个性化、多样化的高质量图像。
利用这些数据与技术储备,我们已经积累了手机/电脑壁纸、艺术姓/名、地标城市风格化、数字藏品等多模态图像生成应用方式。下面我们将展示具体的 AI 生成艺术作品。
AI 艺术作品
城市地标建筑风格化
通过输入文本描述与地标城市底图,生成不同风格的画作(动漫风格 / 赛博朋克风格 / 像素画风格):
(1) A building with anime style, by makoto shinkai and beeple, Trending on artstation.
(2) A building with cyberpunk style, by Gregory Grewdson, Trending on artstation.
(3) A building with pixel style, by Stefan Bogdanovi, Trending on artstation.


数字藏品
通过输入文本描述与底图,在底图上进行创作。
- 蚂蚁 Logo 系列(蚂蚁森林 / 蚂蚁小屋 / 蚂蚁飞船):
(1) A landscape with vegetation and lake, by RAHDS and beeple, Trending on artstation.(2) Enchanted cottage on the edge of a cliff foreboding ominous fantasy landscape, by RAHDS and beeple, Trending on artstation.
(3) A spacecraft by RAHDS and beeple, Trending on artstation.

- 蚂蚁小鸡系列(小鸡之变形金刚 / 小鸡之海绵宝宝):
(1) Transformers with machine armor, by Alex Milne, Trending on artstation.
(2) Spongebob by RAHDS and beeple, Trending on artstation.

手机/电脑壁纸
- 通过输入文本描述,生成手机壁纸:
(1) The esoteric dreamscape by Dan Luvisi, trending on Artstation, matte painting vast landscape.
(2) Scattered terraces, winter, snow, by Makoto Shinka, trending on Artstation, 4k wallpaper.
(3) A beautiful cloudpunk painting of Atlantis arising from the abyss heralded by steampunk whales by Pixar rococo style, Artstation, volumetric lighting.

(4~8) A scenic view of the planets rotating through chantilly cream by Ernst Haeckel and Pixar trending on Artstation, 4k wallpaper.

- 通过输入文本描述,生成电脑壁纸:
(1) Fine, beautiful country fields, super wide angle, overlooking, morning by Makoto Shinkai.
(2) A beautiful painting of a starry night, shining its light across a sunflower sea by James Gurney, Trending on artstation.
(3) Fairy tale steam country by greg rutkowski and thomas kinkade Trending on artstation.
(4) A beautiful render of a magical building in a dreamy landscape by daniel merriam, soft lighting, 4k hd wallpaper, Trending on artstation and behance.

AI 艺术姓
- 通过输入文本描述与姓氏底图,生成不同风格的艺术姓:
(1) Large-scale military factories, mech testing machines, Semi-finished mechs, engineering vehicles, automation management, indicators, future, sci-fi, light effect, high-definition picture.
(2) A beautiful painting of mashroom, tree, artstation, Artstation, 4k hd wallpaper.
(3) A beautiful painting of sunflowers, fog, unreal engine, shining its light across a tumultuous sea of blood by greg rutkowski and thomas kinkade, Artstation, Andreas Rocha, Greg Rutkowski.
(4) A beautiful painting of the pavilion on the water presents a reflection, by John Howe, Albert Bierstadt, Alena Aenami, and dan mumford concept art wallpaper 4k, trending on artstation, concept art, cinematic, unreal engine, trending on behance.
(5) A beautiful landscape of a lush jungle with exotic plants and trees, by John Howe, Albert Bierstadt, Alena Aenami, and dan mumford concept art wallpaper 4k, trending on artstation, concept art, cinematic, unreal engine, trending on behance.
(6) Contra Force, Red fortress, spacecraft, by Ernst Haeckel and Pixar, wallpaper hd 4k, trending on artstation.

其他 AI 艺术创作应用
Stable Diffusion [10, 12] 展现了比 Disco Diffusion [11] 更加高效且稳定的创作能力,尤其是在“物”的刻画上更加突出。下图是笔者利用 Stable Diffusion,根据文本创作的 AI 绘画作品:

总结展望
本文主要介绍了近两年来多模态图像生成技术及相关的进展工作,并尝试使用多模态图像生成进行多种 AI 艺术创作。接下来,我们还将探索多模态图像生成技术在消费级 CPU 上运行的可能性,以及结合业务为 AI 智能创作赋能,并尝试更多如电影、动漫主题封面,游戏,元宇宙内容创作等更多相关应用。
使用多模态图像生成技术进行艺术创作只是 AI 自主生产内容(AIGC,AI generated content)的一种应用方式。得益于当前海量数据与预训练大模型的发展,AIGC 能够加速落地,为人类提供更多优质内容。或许,通用人工智能又迈进了一小步?如果你对本文涉及到的技术或者应用感兴趣,欢迎共创交流。
参考文献
[1] Ramesh A, Pavlov M, Goh G, et al. Zero-shot text-to-image generation[C]//International Conference on Machine Learning. PMLR, 2021: 8821-8831.
[2] Ding M, Yang Z, Hong W, et al. Cogview: Mastering text-to-image generation via transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 19822-19835.
[3] Ding M, Zheng W, Hong W, et al. CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers[J]. arXiv preprint arXiv:2204.14217, 2022.
[4] Zhang H, Yin W, Fang Y, et al. ERNIE-ViLG: Unified generative pre-training for bidirectional vision-language generation[J]. arXiv preprint arXiv:2112.15283, 2021.
[5] Yu J, Xu Y, Koh J Y, et al. Scaling Autoregressive Models for Content-Rich Text-to-Image Generation[J]. arXiv preprint arXiv:2206.10789, 2022.
[6] Wu C, Liang J, Hu X, et al. NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis[J]. arXiv preprint arXiv:2207.09814, 2022.
[7] Ramesh A, Dhariwal P, Nichol A, et al. Hierarchical text-conditional image generation with clip latents[J]. arXiv preprint arXiv:2204.06125, 2022.
[8] Nichol A, Dhariwal P, Ramesh A, et al. Glide: Towards photorealistic image generation and editing with text-guided diffusion models[J]. arXiv preprint arXiv:2112.10741, 2021.
[9] Saharia C, Chan W, Saxena S, et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding[J]. arXiv preprint arXiv:2205.11487, 2022.
[10] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 10684-10695.
[11] Github: https://github.com/alembics/disco-diffusion
[12] Github: https://github.com/CompVis/stable-diffusion