嘉宾 | 杨洋
撰稿 | 黄显东
8月6日-7日,AISummit 全球人工智能技术大会成功举办。本届大会以“驱动•创新•数智”为主题,覆盖“计算机视觉、自然语言处理、算法与模型、推荐系统、机器学习、智慧金融”等技术领域。
在《机器学习性能优化之路》专场中,滴滴首席工程师杨洋通过《个性化推荐在数据运营中的创新应用》的主题分享,为开发者分享了机器学习在数据运营中的探索应用。
数据运营的价值与挑战
数据运营离不开数据体系。在理想的数据体系全景中,预期的主要看数方式包括数据产品、数据服务、数据仓库,以及基础性的临时需求。数据产品主要用来支持运营等非技术人员的看数需求;数据服务是通过API的方式对接各种各样的业务系统;数据仓库是通过资产化方式,对有一定技术能力的人员提供SQL的取数方式。
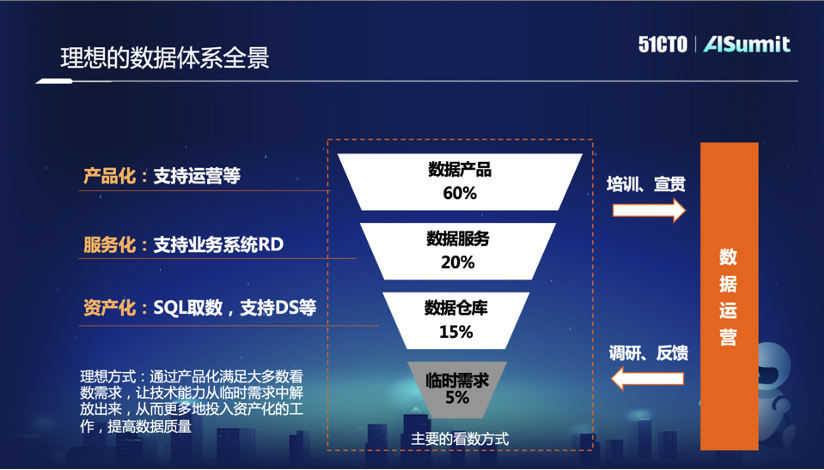
完整的看数过程中,数据运营是贯穿始终的,一方面可以充当沟通渠道,对内指导数据建设;另一方面可以告知用户我们拥有的数据内容,持续向用户进行培训和宣贯。
在理想的情况下,通过产品化的方式来满足大多数的看数需求,这样便可以将整体的研发人力从临时需求中解救出来,投入到资产化的工作当中,从而持续提升数据指标。
不过,理想和现实总是有差距的。在日常工作中,总会遇到各种各样的数据易用性问题或者数据一致性问题。这些问题的背后也是整个数据体系的熵增定律,任何体系的架构,它在孤立无外力的情况下,都会随着时间的推移逐步腐坏。
同时,在产业互联网的发展阶段也为数据运营带来一些新的挑战。从生产视角上看,多数业务场景正处于线上化探索期的产业互联网会导致数据迭代频繁。从消费视角来看,产业互联网的整个组织架构也更复杂多元。这两个视角都会造成多样化和个性化的看数视角。
此外,传统的数据运营推广和培训的方式,也面临时效性差、延续性差和针对性不足的痛点,这些都会对运营效果产生影响。
个性化推荐的探索落地
那如何基于个性化推荐技术来解决数据运营的挑战和痛点呢?
要解决这些问题,首先要对数据运营的目标场景做一个特点分析。典型的数据运营场景可以分成三大类:第一类是用户冷启动场景,占比大概为20%,例如新人入职、业务变化、组织调整等;第二类是内容冷启动场景,占比60%,例如数据线上化或者分析功能迭代;然后通过数据运营的手段触达用户;第三类场景是常态化的运营场景,通过常态化的运营手段,持续提升业务的数据化运营程度,以及实现一些运营经验的复用。
通过目标场景的特点分析,可以得出一些典型的特点。从内容方面上来看,数据内容推荐可以使用OneDate的指标体系,实现更高程度的规范性和结构化。从推荐用户的角度来看,数据内容推荐可以针对性的获取企业内部用户比较规范完整的组织架构信息。从推荐目标上来看,数据内容推荐更加关注准确性,同时消费成本也更高。
基于以上分析,可以构建出数据内容推荐算法的设计思路。对于用户冷启动场景可以使用组织架构的热度信息,构建一个的推荐的策略;对与内容冷启动场景可以基于OneDate+指标血缘的content-based推荐,对内容和用户实现精准的双向匹配。对于常态化的推荐可以基于用户行为策略+业务阶段方向,实现高可控和高可解释性的推荐策略
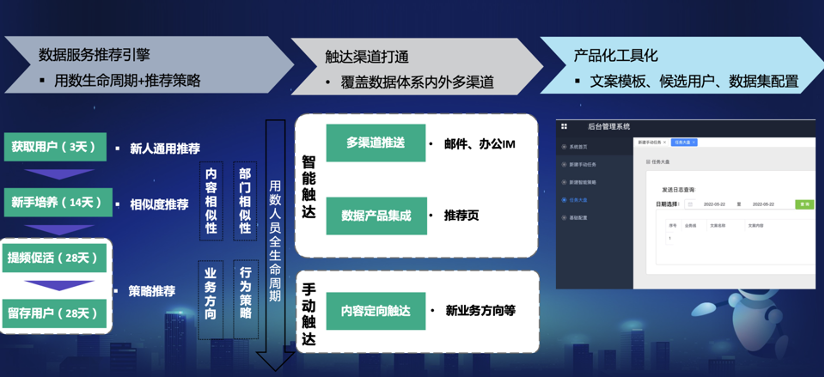
有了初步的算法设计思路,可以基于此将一个全周期的数据运营系统落地。具体包括三方面:首先根据算法实现一个具备用户生命周期策略和推荐策略的数据服务推荐引擎;其次是打通触达渠道,对邮件、办公软件等实现智能触达,并提供手动触达作为补充;最后是对前面的两个能力做工具话和产品化的封装,以服务更多的场景。
机器学习在数据运营领域的未来规划和展望
未来,机器学习在数据运营领域也会有广阔的发展空间。短期内产生价值的可以基于业务线、主题等个性化搜索排序,进行数据检索工具的集成,可以更高效地帮助用户找到数据。
基于数据推荐反向指导数据建设这个发展方向还需要进一步探索。在数据建设的整体决策阶段,可以预先使用推荐来预估潜在的用户量和潜在的访问量,为数据建设提供相对数据化的量化参考。此外在内容设计和可视化方面,也可以根据数据化的分析来提供更加科学和数据化决策指导。