













绝大多数刚刚接触k8s的同学都会被其中的网络相关知识点搞得晕头转向!各种IP,包括:Node IP,ClusterIP,Node IP纠结是啥东东?internet是怎样访问k8s的?k8s内部各个pod之间又是如何通信的?本文就为大家来解决上述问题。
K8s中网络核心概念介绍
Node IP
Node节点的IP地址,即物理网卡的IP地址。
NodePort可以是物理机的IP(也可能是虚拟机IP)。每个Service都会在Node节点上开通一个端口,外部可以通过NodeIP:NodePort即可访问Service里的Pod,和我们访问服务器部署的项目一样,IP:端口/项目名。
Cluster IP
Service的IP地址,此为虚拟IP地址。外部网络无法ping通,只有k8s集群内部访问使用。Cluster IP是一个虚拟的IP,但更像是一个伪造的IP网络,原因有以下几点:
1.Cluster IP仅仅作用于k8s Service这个对象,并由k8s管理和分配P地址。
2.Cluster IP无法被ping,他没有一个“实体网络对象”来响应。
3.Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于k8s集群这样一个封闭的空间。
4.在不同Service下的pod节点在集群间相互访问可以通过Cluster IP。
Pod IP
Pod IP是每个Pod的IP地址,他是Docker Engine根据docker网桥的IP地址段进行分配的,通常是一个虚拟的二层网络
- 同Service下的pod可以直接根据Pod IP相互通信。
- 不同Service下的pod在集群间pod通信要借助于 cluster IP。
- pod和集群外通信,要借助于node IP。
简单地总结:外部访问时,先到Node节点网络,再转到service网络,最后代理给pod网络。
K8s如何实现网络通信
三条核心原则
- 默认情况下,Linux 将所有的进程都分配到 root network namespace,以使得进程可以访问外部网络。
- K8s为每一个 Pod 都创建了一个 network namespace。
- 在 K8s中,Pod 是一组 docker 容器的集合,这一组 docker 容器将共享一个 network namespace。Pod 中所有的容器都使用该 network namespace 提供的同一个 IP 地址以及同一个端口空间。所有的容器都可以通过 localhost 直接与同一个 Pod 中的另一个容器通信。
容器与容器之间网络通信
pod中每个docker容器和pod在一个网络命名空间内,所以ip和端口等等网络配置,都和pod一样,主要通过一种机制就是,docker的一种网络模式,container,新创建的Docker容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等
pod与pod之间网络通信
从 Pod 的视角来看,Pod 是在其自身所在的 network namespace 与同节点上另外一个 network namespace 进程通信。在Linux上,不同的 network namespace 可以通过 Virtual Ethernet Device (opens new window) 或 veth pair (两块跨多个名称空间的虚拟网卡)进行通信。为连接 pod 的 network namespace,可以将 veth pair 的一段指定到 root network namespace,另一端指定到 Pod 的 network namespace。每一组 veth pair 类似于一条网线,连接两端,并可以使流量通过。节点上有多少个 Pod,就会设置多少组 veth pair。下图展示了 veth pair 连接 Pod 到 root namespace 的情况:
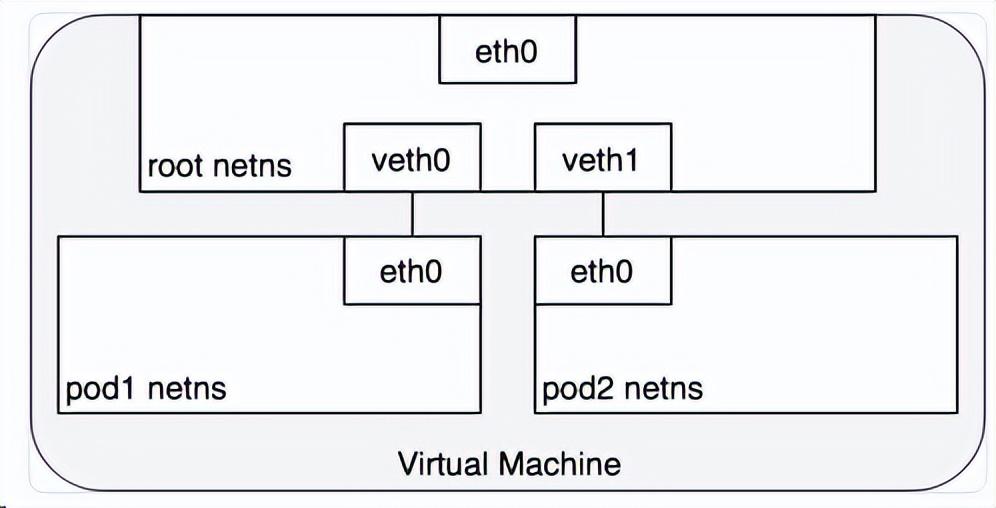
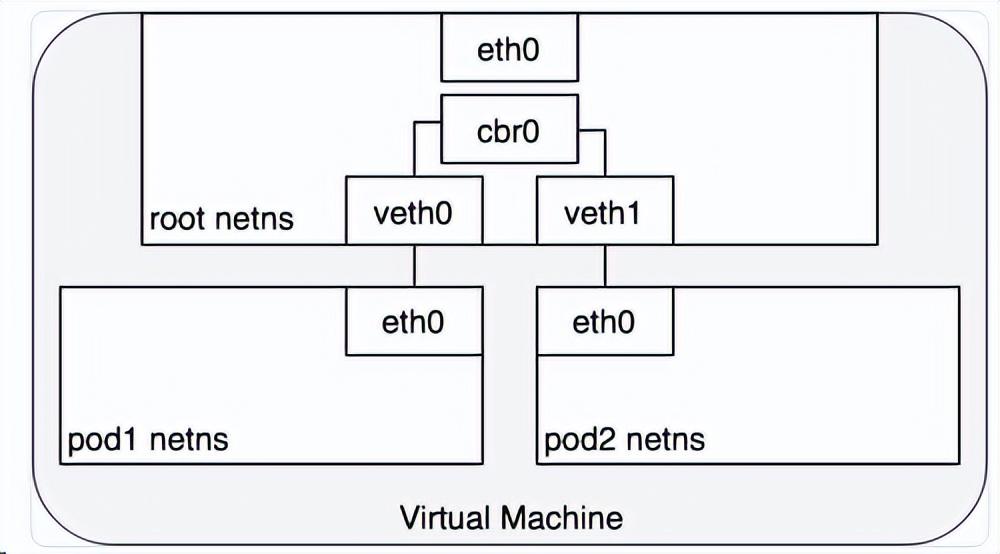
为了让 Pod 可以互相通过 root network namespace 通信,我们将使用 network bridge(网桥)。Linux Ethernet bridge 是一个虚拟的 Layer 2 网络设备,可用来连接两个或多个网段。网桥的工作原理是,在源于目标之间维护一个转发表,通过检查通过网桥的数据包的目标地址和该转发表来决定是否将数据包转发到与网桥相连的另一个网段。桥接代码通过网络中具备唯一性的网卡MAC地址来判断是否桥接或丢弃数据。网桥实现了ARP协议来发现链路层与 IP 地址绑定的 MAC 地址。当网桥收到数据帧时,网桥将该数据帧广播到所有连接的设备上(除了发送者以外),对该数据帧做出相应的设备被记录到一个查找表中。后续网桥再收到发向同一个 IP 地址的流量时,将使用查找表来找到对应的 MAC 地址,并转发数据包。下图中cbr0就是网桥。
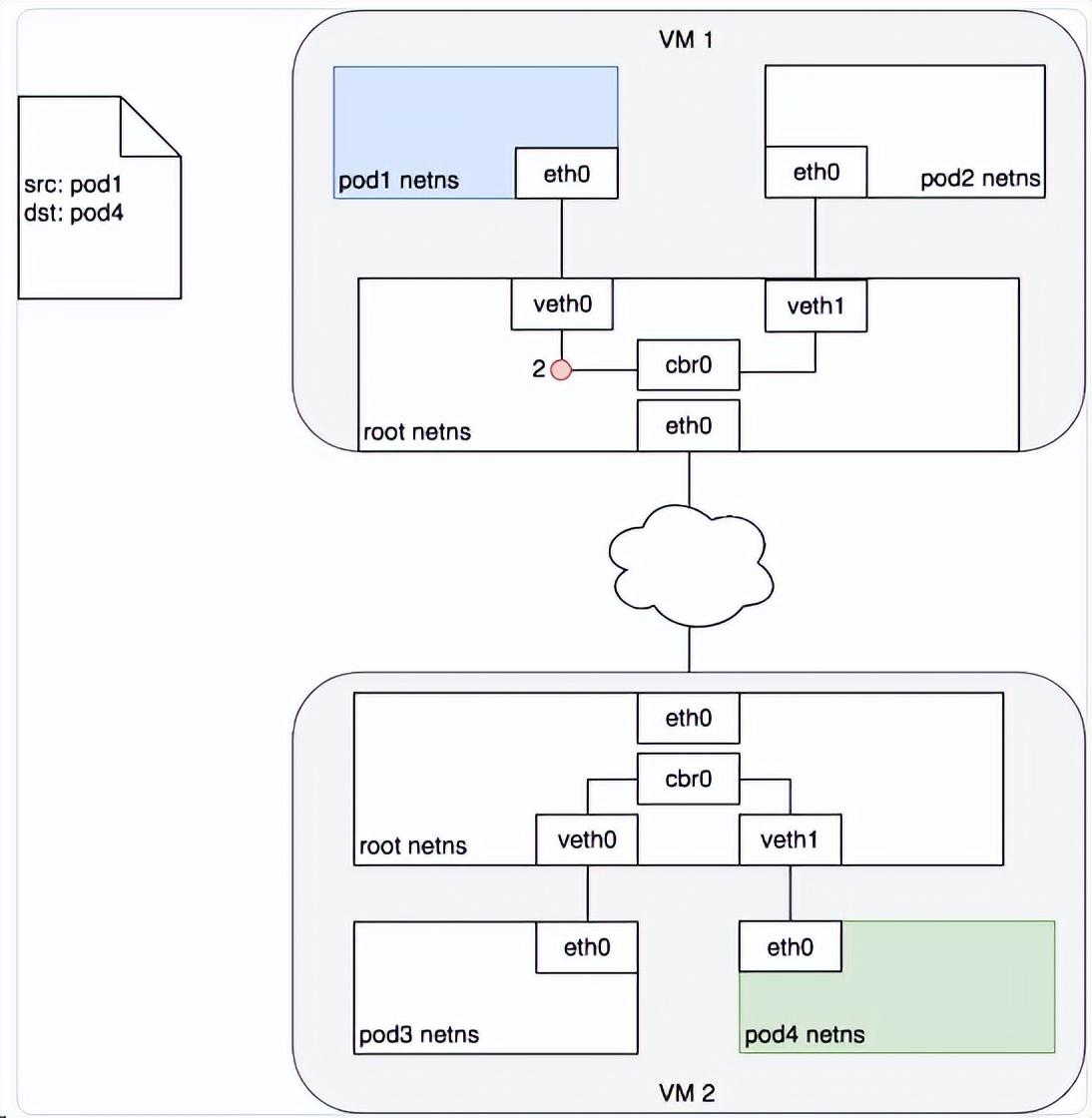
不同Node间通信原理
通常,集群中每个节点都被分配了一个 CIDR 网段(简单的理解CIDR可以把几个标准网络合成一个大的网络),指定了该节点上的 Pod 可用的 IP 地址段。一旦发送到该 CIDR 网段的流量到达节点,就由节点负责将流量继续转发给对应的 Pod。下图展示了两个节点之间的数据报文传递过程。
pod与service之间网络通信
Pod 的 IP 地址并非是固定不变的,随着 Pod 的重新调度(例如水平伸缩、应用程序崩溃、节点重启等),Pod 的 IP 地址将会出现又消失。此时,Pod 的客户端无法得知该访问哪个 IP 地址。k8s中,Service 的概念用于解决此问题。Service管理了多个Pods,每个Service有一个虚拟的ip,要访问service管理的Pod上的服务只需要访问你这个虚拟ip就可以了,这个虚拟ip是固定的,当service下的pod规模改变、故障重启、node重启时候,对使用service的用户来说是无感知的,因为他们使用的service的ip没有变。当数据包到达Service虚拟ip后,数据包会被通过k8s给该servcie自动创建的负载均衡器路由到背后的pod容器。
我们知道Service 是 k8s中的一种服务发现机制,总结核心功能如下:
- 通常通过service来关联pod并提供对外访问接口。
- Service 实现负载均衡,可将请求均衡分发到选定这一组 Pod 中。
- Service 通过 label selector 选定一组 Pod。
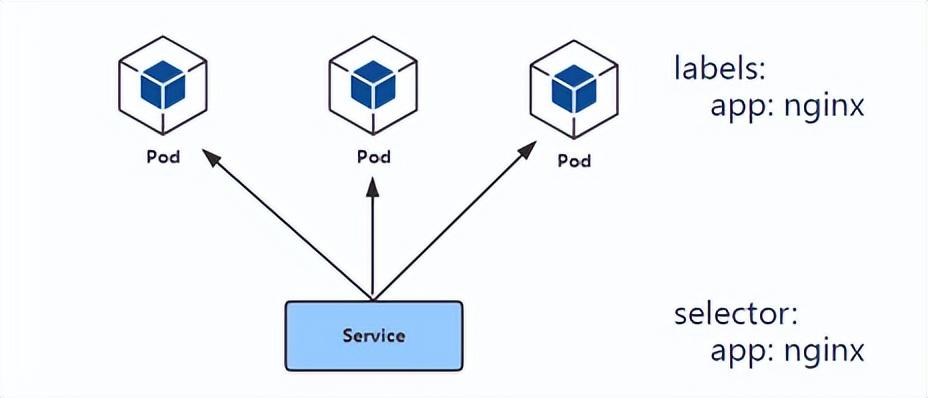
Service的ip分配策略
k8s的一个设计哲学是:尽量避免非人为错误产生的可能性。就设计 Service 而言,k8s应该将您选择的端口号与其他人选择的端口号隔离开。为此,k8s为每一个 Service 分配一个该 Service 专属的 IP 地址。为了确保每个 Service 都有一个唯一的 IP 地址,k8s在创建 Service 之前,先更新 etcd 中的一个全局分配表,如果更新失败(例如 IP 地址已被其他 Service 占用),则 Service 不能成功创建。k8s使用一个后台控制器检查该全局分配表中的 IP 地址的分配是否仍然有效,并且自动清理不再被 Service 使用的 IP 地址。
Service的dns解析
k8s集群中运行了一组 DNS Pod,配置了对应的 Service,并由 k8s将 DNS Service 的 IP 地址配置到节点上的容器中以便解析 DNS names。集群中的每一个 Service(包括 DNS 服务本身)都将被分配一个 DNS name。默认情况下,客户端 Pod 的 DNS 搜索列表包括 Pod 所在的名称空间以及集群的默认域。例如:
假设名称空间 A中有一个 Service 名为 foo:
- 名称空间 A中的 Pod 可以通过 nslookup foo 查找到该 Service。
- 名称空间 B中的 Pod 可以通过 nslookup foo.A 查找到该 Service。
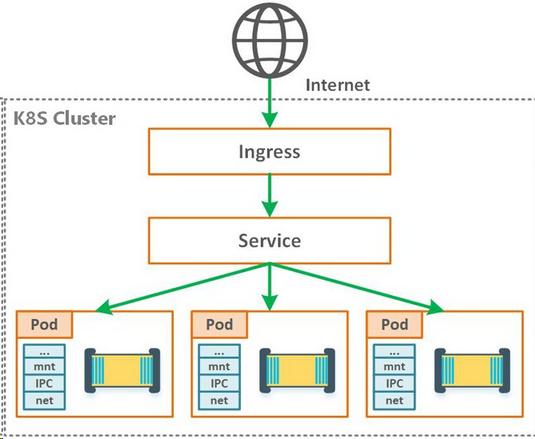
Internet与k8s的网络通信
让Internet流量进入k8s集群,这特定于配置的网络,可以在网络堆栈的不同层来实现:
- NodePort
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
- Service LoadBalancer
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它设有过滤条件,路由等功能。值得一提的是,如果是在本地开发测试环境里头搭建的K8s,一般不支持Load Balancer也没必要,因为通过NodePort做测试访问就够了。但是在生产环境或者公有云上的K8s,基本都支持自动创建Load Balancer。
- Ingress控制器
它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。它的本质上就是K8s集群中的一个比较特殊的Service(发布Kind: Ingress)。这个Service提供的功能主要就是7层反向代理(也可以提供安全认证,监控,限流和SSL证书等高级功能),功能类似Nginx。Ingress对外暴露出去是通过HostPort(80/443),可以和上面LoadBalancer对接起来。有了这个Ingress Service,我们可以做到只需购买一个LB+IP,就可以通过Ingress将内部多个(甚至全部)服务暴露出去,Ingress会帮忙做代理转发。


























