译者 | 陈峻
审校 | 孙淑娟
在本文中,我将构建一个Java微服务,与Neo4j AuraDB的免费数据库中的图形数据进行连接和交互。这些数据是Goodreads数据集的精简版,其中包含了各种书籍、作者和评论等信息。虽然书籍和作者类别的数据适合于MongoDB等文档数据库,但是一旦我们将评论添加到该组合之中,则需要通过AuraDB来体现各个实体之间的关系,并最大限度地简化针对实体连接方式的查询。
预备知识
如果您对图形数据库不太熟悉的话,请通过如下资源自行恶补:
- 博客文章:《图形数据库能够解决哪些问题?》
- Neo4j指南:《什么是图形数据库?》
总的说来,Neo4j提供了多种部署选项。我们既可以启动一个Docker容器(就像我们早期使用MongoDB项目那样)或利用带有免费层的数据库即服务(database-as-a-service),如:AuraDB。
在本例中,我们将先创建自己的Neo4j数据库,再加载数据,然后构建一个与数据库交互、且能够为客户端各自服务提供API的微服务。
AuraDB
通常,您需要花费几分钟的时间,才能完成Neo4j AuraDB免费实例的注册和创建,其中包括:验证您的电子邮件地址,以及等待实例的启动。您可以通过《Discover AuraDB Free》一文了解该过程的详细信息、以及屏幕截图。
图形数据加载
一旦实例开始运行,我们就可以加载数据了。您可以通过代码存储库,查看到包含了各种书籍的启动文件、文件夹自述文件、以及加载脚本中的说明。其中,自述文件中包含了各种查询,以方便我们去验证数据。
值得注意的是,虽然具有较大数据集的版本也适合AuraDB的免费层实例,但为了便于实现快速加载,我们暂时选择并保持较小的数据集。
应用服务
下面,我们需要通过构建应用,来提取评论数据。就微服务而言,我们将构建一个带有一组REST端点的Spring Boot应用程序,以访问连入Neo4j数据库中的数据。
在此,我们可以使用start.spring.i中的Spring Initializr来整理出项目的大纲。而在表单上,我们可以将Project、Language和Spring Boot字段保留为默认值。同时,在项目的Metadata部分下,我添加了该项目的组名。当然,您也可以保留默认值。虽然工件(artifact)名不太重要,但是我仍将其命名为neo4j-java-microservice,而所有其他字段则保持原样。
在Dependencies部分下,我们将需要Spring Reactive Web、Lombok和Spring Data Neo4j。其中,Spring Data Neo4j是用于连接各种数据存储的一个Spring Data项目。它可以帮助我们映射和访问加载到数据库中的数据。至此,该工程的模板已完成,我们可以点击底部的Generate按钮,来下载该工程(请参见下图)。
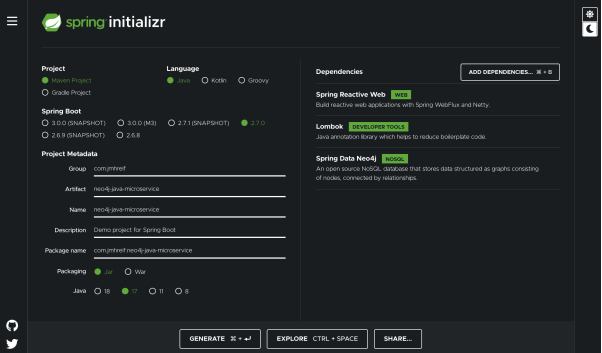
注意:Spring Initializr会通过页面右栏中的月亮和太阳图标,来切换夜间和日间模式
由于项目被下载成为ZIP文件,因此我们可以将其解压缩,并在自己喜好的IDE中打开它。
由于pom.xml文件包含了我们在Spring Initializr上设置的依赖项和软件版本,因此我们可以轻松地定位到src/main/resources夹中的application.properties文件。在此,我们需要使用URI和数据库凭据,来连接到Neo4j的实例上。毕竟,对于基于云端的实例而言,哪怕是对这些值采用了硬编码,也可能会让其他人意外地登录进去,进而篡改我们的数据库。因此,我们通常应当避免将数据库的凭据直接嵌入到应用程序之中。为此,诸如数据库凭据之类的配置值,需要在运行时(runtime),使用Spring Cloud Config之类的项目进行外部化与读取。在本例中,我们可以在属性文件中嵌入数据库的URI、用户名、密码、以及数据库的名称。请参见如下代码:
#database connection
spring.neo4j.uri=<insert Neo4j URI here>
spring.neo4j.authentication.username=<insert Neo4j username here>
spring.neo4j.authentication.password=<insert Neo4j password here>
spring.data.neo4j.database=<insert Neo4j database here>- 1.
- 2.
- 3.
- 4.
- 5.
注意:除非您专门使用命令去更改其默认值,否则此处数据库默认为neo4j。
项目代码
让我们从整个域的类开始浏览各个Java文件:
@Data
@Node
class Review {
@Id
@GeneratedValue
private Long neoId;
@NonNull
private String review_id;
private String book_id, review_text, date_added, date_updated, started_at, read_at;
private Integer rating, n_comments, n_votes;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
此处的@Data是一个Lombok注释。它不但能够为整个域的类生成我们所需要的getter、setter、equals、hashCode、以及toString方法,而且有效地减少了样板(boilerplate)代码的数量。而作为Spring Data Neo4j注释的@Node,会将自己标记为Neo4j实体类(Neo4j的各个实体都称为节点)。
在类的声明中,我们为类定义了一些属性字段。其中,@Id注释是将字段标记为唯一的标识符。而@GeneratedValue可以表示该值是由Neo4j内部生成的。对于review_id字段,我们有一个Lombok@NonNull注释,指定了该字段不能为空。同时,我们还需要检索一些其他字段,以获取评论文本、日期和评分信息。
接下来,我们需要一个存储库的接口,以便在其中定义与数据库里的数据进行交互的方法。
interface ReviewRepository extends ReactiveCrudRepository<Review, Long> {
Flux<Review> findFirst1000By();
@Query("MATCH (r:Review)-[rel:WRITTEN_FOR]->(b:Book {book_id: $book_id}) RETURN r;")
Flux<Review> findReviewsByBook(String book_id);
}- 1.
- 2.
- 3.
- 4.
- 5.
我们希望该存储库能够扩展ReactiveCrudRepository,以便使用各种响应式方法和类型,去处理数据。下面,我们来定义一组方法。虽然我们可以使用Spring Data的一些默认方法,以开箱即用的方式实现(请参见代码示例文档-- https://docs.spring.io/spring-data/commons/docs/current/reference/html/#repositories.core-concepts),不过,我们在此进行了自定义。毕竟,考虑到提取所有35,342条评论,可能会使得客户端在呈现结果的过程中出现过载,因此我们并没有使用默认的.findAll()方法,而是只提取其中的前1,000个结果。而且,我们并没有去实现findFirst1000By()方法(例如,实现其查询逻辑),而是使用了Spring Data的另一个特性:派生方法,即:利用Spring,根据方法的名称去构造(即称“派生”)查询。
在本例中,由于我们的存储库可以使用ReactiveCrudRepository<Review, Long>来处理评论,因此findFirst1000会去寻找前1,000条评论。通常,该语法会通过by的特定标准(如:评分、评论者、以及日期等)来持续查找结果。不过,由于我们只想提取随机的评论集合,因此我们仅通过简单地从方法名称中省去具体标准,来“欺骗”Spring,并获得findFirst1000By的结果。
我们的下一个方法--findReviewsByBook()要简单得多。如您所知,为了查找某本指定书目的评论,我们需要通过book_id去进行查找。在此,我们将@Query注释与数据库相关的查询语句一起使用,即Neo4j的Cypher。
而在存储库完成之后,我们便可以编写控制器的类,以便为其他服务设置一些用于访问数据的REST端点。
@RestController
@RequestMapping("/neo")
@AllArgsConstructor
class ReviewController {
private final ReviewRepository reviewRepo;
@GetMapping
String liveCheck() { return "Neo4j Java Microservice is up"; }
@GetMapping("/reviews")
Flux<Review> getReviews() { return reviewRepo.findFirst1000By(); }
@GetMapping("/reviews/{book_id}")
Flux<Review> getBookReviews(@PathVariable String book_id) { return reviewRepo.findReviewsByBook(book_id); }
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
Spring注释--@RestController会将此代码块指定为一个REST控制器类,而@RequestMapping则为所有类的方法都定义一个高级端点。如您所见,在类的声明中,我们注入了ReviewRepository,以便使用已写好的方法。
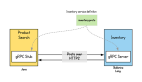
接下来,我们为每个方法映射相应的端点。其中,liveCheck()方法使用高级的/neo端点来返回一个字符串,以确保我们的服务是实时且可访问的。同时,我们可以通过添加嵌套端点(/reviews),来执行getReviews()方法。该方法用到了我们在存储库中编写的findFirst1000By()方法,并返回一个反应式Flux<>类型,并带有零到多条评论结果。
我们的最终方法嵌套了端点/reviews/{book_id}。其中,书籍id是一个路径变量,它会根据待搜索的书目而变化。而getBookReviews()方法会传入指定的书的id作为路径变量,然后从存储库中调用findReviewsByBook()方法,并返回一个带有评论的Flux<>。
进行测试
下面,我们可以测试这个新服务了。首先,我需要确保Neo4j AuraDB实例仍在运行。注意:AuraDB的免费套餐通常会在三天后自动暂停。对此,您需要使用实例上的“播放”图标予以恢复。
接下来,我们需要通过IDE或命令行,来启动我们的neo4j-java-microservice应用。在其开始运行后,我们可以使用以下命令开展应用测试:
1. 测试应用的上线状态:打开浏览器,输入localhost:8080/neo;或是在命令行中输入curl localhost:8080/neo。
2. 通过查找评论来测试后端的评论api:打开浏览器,输入localhost:8080/neo/reviews;或是在命令行中输入curl localhost:8080/neo/reviews。
3. 通过查找具体某本书的评论,来测试API:打开浏览器,输入localhost:8080/neo/reviews/178186;或是在命令行中输入curl localhost:8080/neo/178186。
下图展示了该服务的评论api的输出结果:
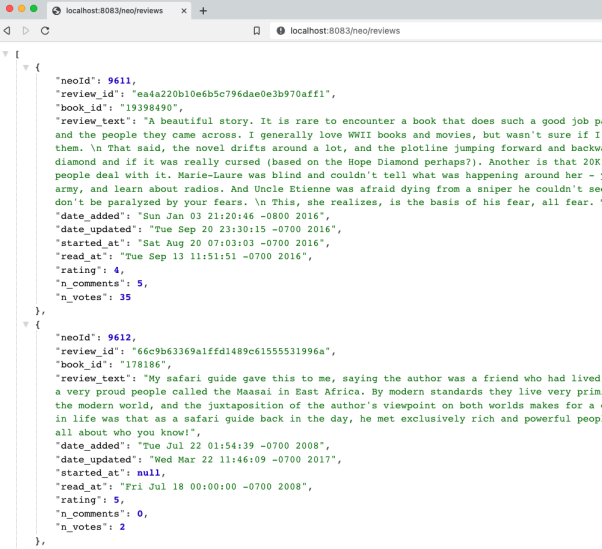
找到前1000条评论
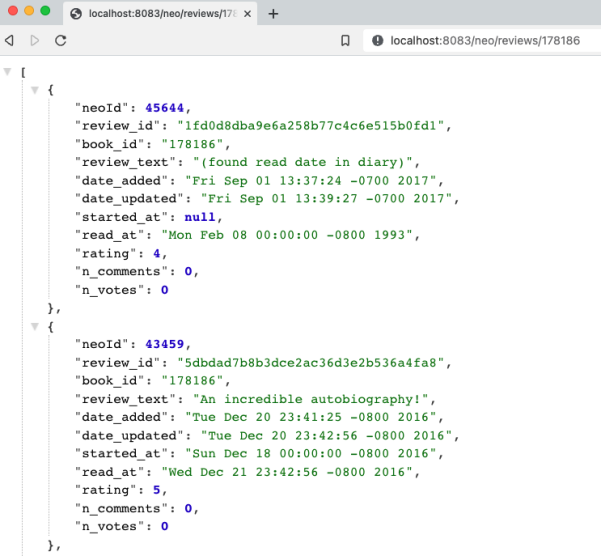
按书目查找评论
小结
通过上述步骤,我们使用Neo4j AuraDB的免费层,创建了一个图形数据库实例,并为书籍、作者和评论加载了相关数据。接着,我们构建了一个微服务应用,以连接到云端数据库中,并检索相关评论。最后,我们通过启动应用和访问每个端点的方式,来测试我们的所有代码,以确保数据能够被正常地查询到。
同时,我们在此基础上进行了扩展。其中包括:为了保持敏感数据的机密性,并可供多个服务访问,我们使用Spring Cloud Config将数据库的凭证予以了外部化。当然,我们也可以将该服务添加到Docker Compose等编排工具中,以协同管理多个服务。将来,我们还可以通过从数据库中提取更多相关实体,更加充分地利用图形数据的优势。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Build a Java Microservice With AuraDB Free,作者:Jennifer Reif