Prometheus是一个开源系统监控和告警工具包,于 2016 年加入云原生计算基金会,成为继Kubernetes之后的第二个托管项目。
本篇文章将结合告警信息来一起了解下如何实现在告警时附带指标趋势图,以便能更好的定位告警原因和发生时间。
在告警时附带指标趋势图的难点
在Prometheus中提供了三种查看指标出图的方式,分别是
- EXPRESSION BROWSER
- Grafana
- Console templates
我们通常会更推荐使用Grafana,拥有EXPRESSION BROWSER的所有能力,同时还支持令人映像深刻的出图效果和友好的使用体验。
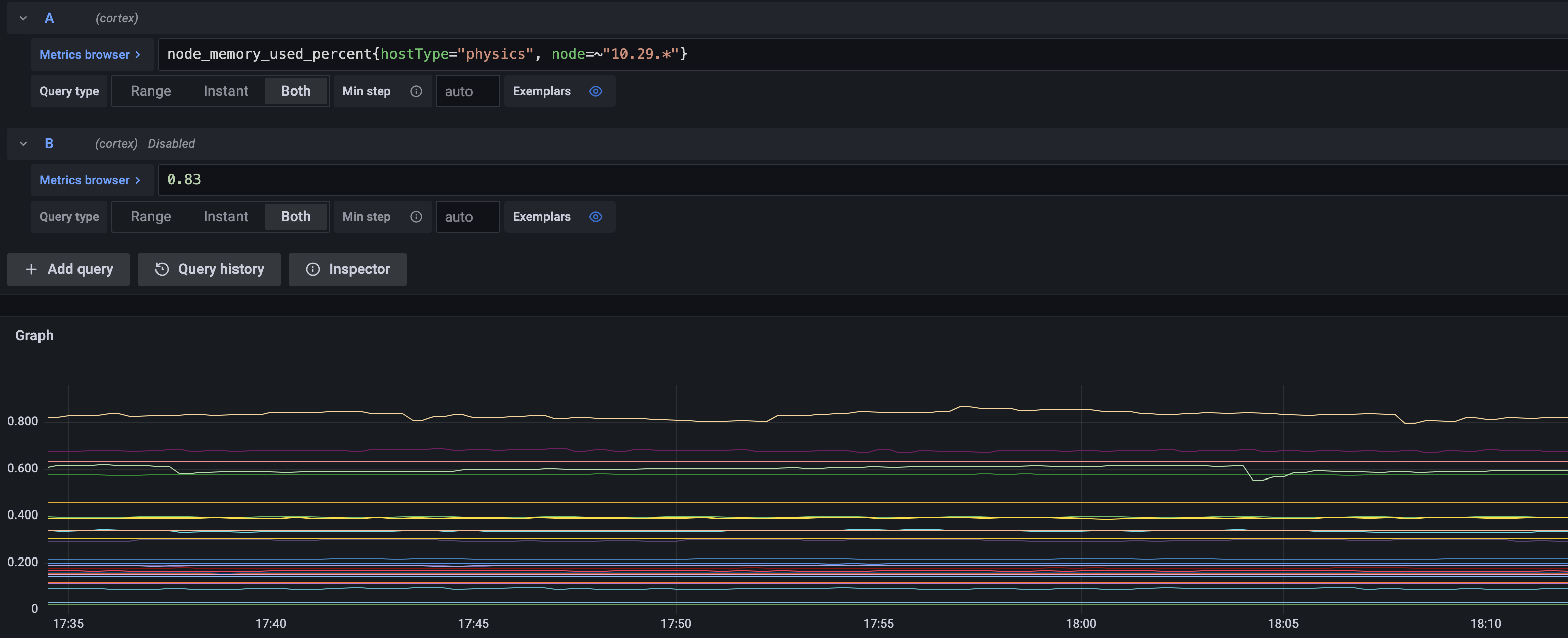
node内存使用指标趋势图
Prometheus支持基于PromQL的告警规则,通常如下所示
groups:
- name: example
rules:
- alert: NodeHighMemoryUsed
expr: node_memory_used_percent{job="myjob"} > 0.8
for: 10m
labels:
severity: warn
annotations:
summary: node high memory used
其中最重要的就是expr字段,它的值是一个表达式PromQL表达式,如果表达式的结果为true,也即能过滤到数据,那么就会对每个时序metric生成一条告警,默认的告警信息中通常会包含labels和annotations内地信息,这些信息通常是预置的文本和文本模版(annotations内支持将labels作为变量的模版,最后告警时会渲染为实际的值,最后也是文本)
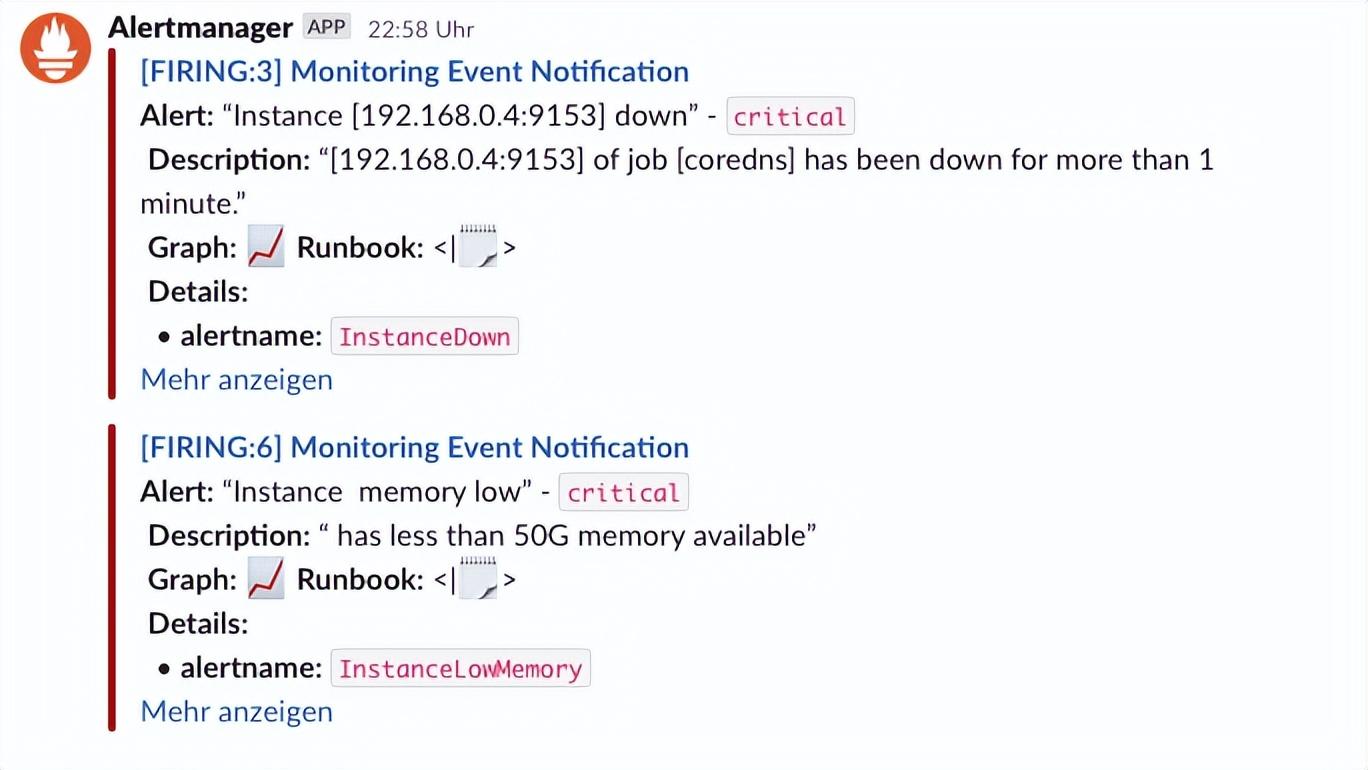
基于告警文本的消息只能获得告警当时的状态信息,告警只是第一步,如果要定位告警原因,通常需要告警发生前的历史累积状态信息,那就需要针对每个具体告警,生成对应的专有指标趋势图。
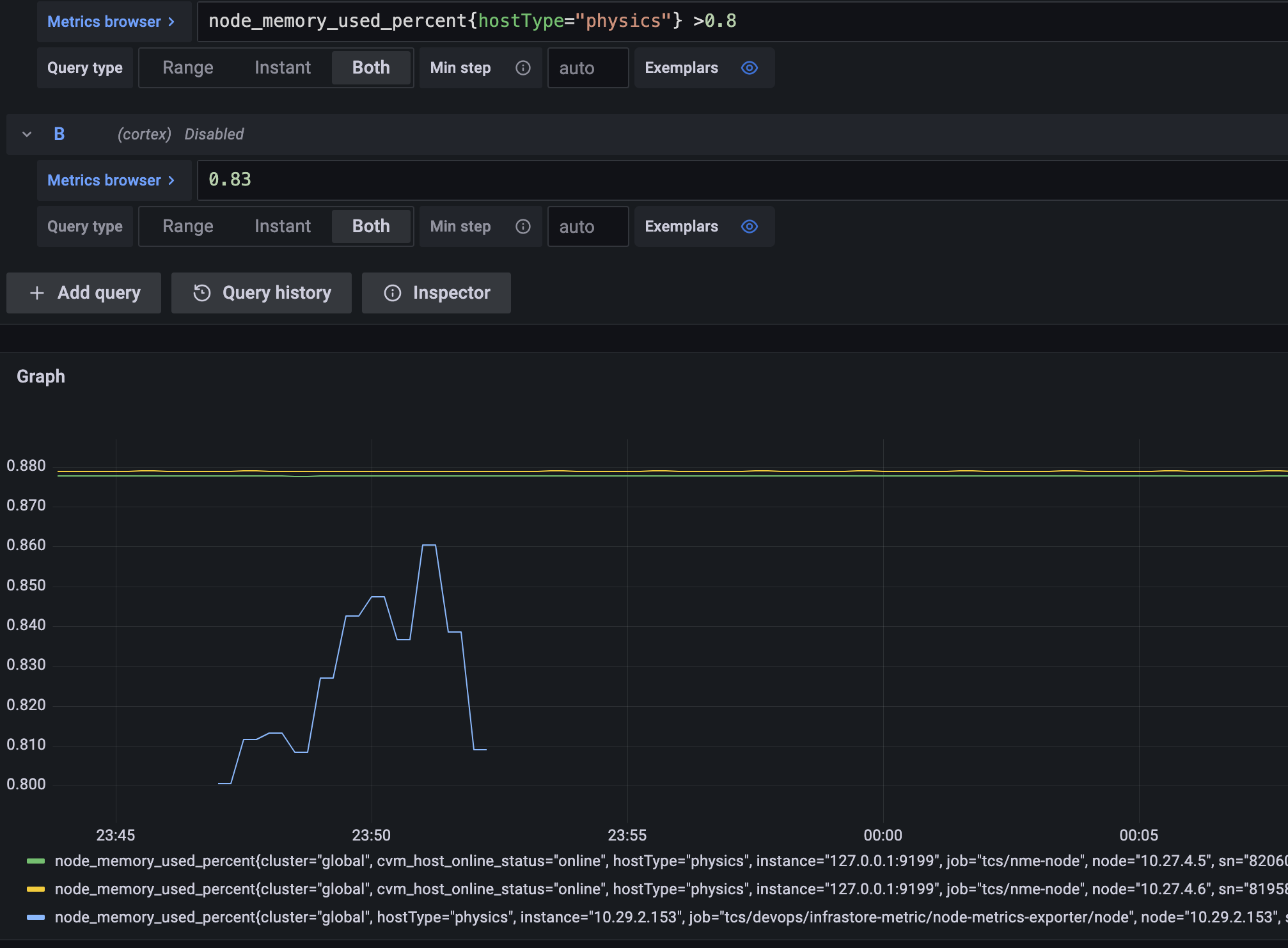
默认的告警表达式,如上图所示,会展示所有符合条件的数据,但有两个问题:
- 每个告警其实只需要自己的趋势图,不需要展示别的对象的趋势图。
- 希望展示完整的趋势图,更便于发现趋势问题。
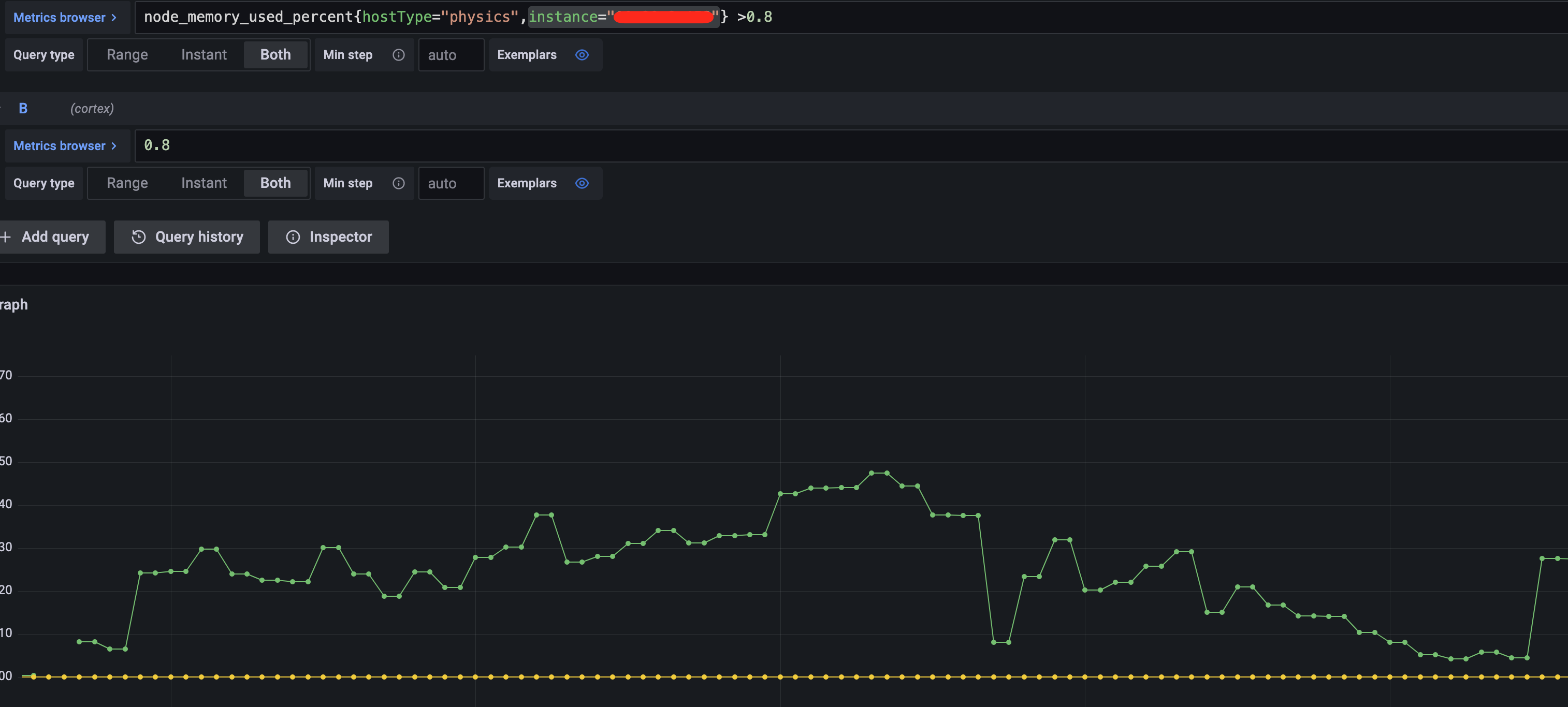
如下图所示,只针对某个告警对象,且既有告警趋势,也有基线,这样的图更加方便定位。
通常我们的规则都是形式如下:
"node_cpu_usage > 0"
"rate(node_cpu_total{node=\"n1\"}[1m]) > rate(node_cpu_total{node=\"n2\"}[1m])"
"container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01"
"container_cpu_limit_usage > 0 and container_memory_limit_usage > 0"
"container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8"
`sum(rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)`
这些规则的基本规律就是基于metric name和labels筛选数据,并做一些函数处理,最后与某个阈值行比较,在PromQL中,比较操作其实会被转换为过滤操作,如果能过滤出符合的数据,就触发告警。
如果要查明白为啥告警,首先需要对每个表达式进行拆分,然后分别查询每个拆分后的表达式,看看到底是哪个数据有问题,同时也需要看看每个表达式在数据异常前后的一些情况,也就需要比告警的时间范围大一些。
另外一点是,通常告警规则是适用于一类对象的,比如都是node的cpu告警,或者内存告警,但实际告警时是会给出每个具体的node信息,其他告警也类似,如果要查询告警数据,也只需要查发生告警的对象的指标数据,其他对象不需要查。
为了实现上述的能力,通常需要解决两个问题:
- 将Prometheus alert rules拆分成多个查询表达式。
- 在Prometheus alert rules中增加本次告警专属的用于区分告警对象的labels。
解决思路
上述两个功能,在prometheus中并没有提供直接可用的能力,但可以根据代码分析出可以使用和借鉴的能力。
func InjectSelectors(expr Expr, selectors []*labels.Matcher) error {
Inspect(expr, func(node Node, _ []Node) error {
vs, ok := node.(*VectorSelector)
if ok {
vs.LabelMatchers = append(vs.LabelMatchers, selectors...)
}
return nil
})
return nil
}
对于问题1,在上述文章的分析过程中,也发现了对应的解决办法,但当时没有意识到,直到后续debug一步一步测试中才发现规律,同时也加深了对PromQL设计的理解。
PromQL是一门函数嵌套语言,同时也支持基本的算数和逻辑运算,既然是这样,那么我们就可以像解数学计算题一样,一步一步的解,而且组成PromQL表达式的元素的固定的,有11种类型(详情见上面引用的文章,这里不再赘述),每个表达式都可以拆解为这些Type的实例的组合。
对于我们的告警表达式来说,绝大多数都是左右两个数据进行算数或者逻辑运算,这种都是BinaryExpr类型,也即由更下层的类型组合成的新的表达式类型。我们可以直接识别BinaryExpr类型,如果是BinaryExpr,那就进行拆分,就得到两个表达式用于绘图,如果不是,跳过即可。
实战验证
拆分测试代码:
func TestSplitQuery(t *testing.T) {
testExprs := []string{
"node_cpu_usage > 0",
"rate(node_cpu_total{node=\"n1\"}[1m]) > rate(node_cpu_total{node=\"n2\"}[1m])",
"container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01",
"container_cpu_limit_usage > 0 and container_memory_limit_usage > 0",
"container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8",
`sum(rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)
/
sum(rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) without(instance, pod)`,
}
for _, qs := range testExprs {
expr, err := parser.ParseExpr(string(qs))
if err != nil {
t.Fatal(err)
}
parser.Inspect(expr, func(node parser.Node, _ []parser.Node) error {
switch T := node.(type) {
case *parser.VectorSelector:
t.Log("VectorSelector", T.String())
case *parser.BinaryExpr:
t.Log("BinaryExpr", T.String(), T.Op.String(), T.LHS.String(), T.RHS.String())
return nil
}
return nil
})
}
}
结果:
Running tool: /usr/local/go/bin/go test -timeout 30s -run ^TestSplitQuery$ xxx/pkg/xxx -v
=== RUN TestSplitQuery
xxx/pkg/xxx_test.go:77: BinaryExpr node_cpu_usage > 0 > node_cpu_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_usage
xxx/pkg/xxx_test.go:77: BinaryExpr rate(node_cpu_total{node="n1"}[1m]) > rate(node_cpu_total{node="n2"}[1m]) > rate(node_cpu_total{node="n1"}[1m]) rate(node_cpu_total{node="n2"}[1m])
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_total{node="n1"}
xxx/pkg/xxx_test.go:75: VectorSelector node_cpu_total{node="n2"}
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) > 1.01 > container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) 1.01
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage / avg_over_time(container_cpu_limit_usage[1d] offset 1d) / container_cpu_limit_usage avg_over_time(container_cpu_limit_usage[1d] offset 1d)
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage offset 1d
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0 and container_memory_limit_usage > 0 and container_cpu_limit_usage > 0 container_memory_limit_usage > 0
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0 > container_cpu_limit_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_memory_limit_usage > 0 > container_memory_limit_usage 0
xxx/pkg/xxx_test.go:75: VectorSelector container_memory_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 or container_cpu_limit_usage > 0.8 or container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 container_cpu_limit_usage > 0.8
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 and container_memory_limit_usage > 0.5 and container_cpu_limit_usage > 0.5 container_memory_limit_usage > 0.5
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.5 > container_cpu_limit_usage 0.5
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_memory_limit_usage > 0.5 > container_memory_limit_usage 0.5
xxx/pkg/xxx_test.go:75: VectorSelector container_memory_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr container_cpu_limit_usage > 0.8 > container_cpu_limit_usage 0.8
xxx/pkg/xxx_test.go:75: VectorSelector container_cpu_limit_usage
xxx/pkg/xxx_test.go:77: BinaryExpr sum without(instance, pod) (rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) / sum without(instance, pod) (rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) / sum without(instance, pod) (rate(apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m])) sum without(instance, pod) (rate(apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}[5m]))
xxx/pkg/xxx_test.go:75: VectorSelector apiserver_request_duration_seconds_sum{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}
xxx/pkg/xxx_test.go:75: VectorSelector apiserver_request_duration_seconds_count{subresource!="log",verb!~"LIST|WATCH|WATCHLIST|DELETECOLLECTION|PROXY|CONNECT"}
--- PASS: TestSplitQuery (0.00s)
PASS
ok xxx/pkg/xxx 0.025s
总结
本文主要探讨如何在告警信息中,加入拆分后的、专属告警本身的指标趋势图,来更加方便的定位告警原因。主要解决两个问题:如何拆分告警表达式和对表达式加入新的label matchers。本篇继续深入分析,并给出了如何拆分告警表达式的详细分析和代码示例;这样结合两者我们就能完整的实现我们的需求了。