本文讲介绍以下几个内容:
- 引入用GoLang语言写的几个case;
- 介绍什么是闭包;
- 介绍什么是闭包的延迟绑定;
- 从闭包的延迟绑定讲到GoLang的Go Routine的延迟绑定问题;
1. 几个有趣的Case
开门见山,首先请各位看官们先看下面foo1()到foo7()一共7个函数,然后回答后面的问题。(一下子丢出7个函数,请见谅。不过,每个函数都非常简短,而本文接下来将围绕这7个函数展开,因此,请各位看官老爷们耐心且看看题,活动活动脑细胞~)
- case 1:
func foo1(x *int) func() {
return func() {
*x = *x + 1
fmt.Printf("foo1 val = %d\n", *x)
}
}
- case 2:
func foo2(x int) func() {
return func() {
x = x + 1
fmt.Printf("foo2 val = %d\n", x)
}
}
- case 3:
func foo3() {
values := []int{1, 2, 3, 5}
for _, val := range values {
fmt.Printf("foo3 val = %d\n", val)
}
}
- case 4:
func show(v interface{}) {
fmt.Printf("foo4 val = %v\n", v)
}
func foo4() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go show(val)
}
}
- case 5:
func foo5() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go func() {
fmt.Printf("foo5 val = %v\n", val)
}()
}
}
- case 6:
var foo6Chan = make(chan int, 10)
func foo6() {
for val := range foo6Chan {
go func() {
fmt.Printf("foo6 val = %d\n", val)
}()
}
}
- case 7:
func foo7(x int) []func() {
var fs []func()
values := []int{1, 2, 3, 5}
for _, val := range values {
fs = append(fs, func() {
fmt.Printf("foo7 val = %d\n", x+val)
})
}
return fs
}
- Q1:
- 第一组实验:假设现在有变量x=133,并创建变量f1和f2分别为foo1(&x)和foo2(x)的返回值,请问多次调用f1()和f2()会打印什么?
- 第二组实验:重新赋值变量x=233,请问此时多次调用f1()和f2()会打印什么?
- 第三组实验:如果直接调用foo1(&x)()和foo2(x)()多次,请问每次都会打印什么?
- Q2:
- 请问分别调用函数foo3(),foo4()和foo5(),分别会打印什么?
- Q3:
- 第一组实验:如果“几乎同时”往channelfoo6Chan里面塞入一组数据"1,2,3,5",foo6会打印什么?
- 第二组实验:如果以间隔纳秒(10^-9秒)的时间往channel里面塞入一组数据,此时foo6又会打印什么?
- 第三组实验:如果是微秒(10^-6秒)呢?如果是毫秒(10^-3秒)呢?如果是秒呢?
- Q4:
- 请问如果创建变量f7s=foo7(11),f7s是一个函数集合,遍历f7s会打印什么?
接下来,我们逐一来看这些问题和对应的foo函数。
2. case1~2:值传递(by value) vs. 引用传递(by reference)
子标题好难起 >0<...
看到case1和case2的两组函数foo1()和foo2(),相信各位看官就知道,其中一个知识点就是值传递和引用传递。
其实呢,Go是没有引用传递的,即使是foo1()在参数上加了*,内部实现机制仍旧是值传递,只不过传递的是指针的数值。但是为了称呼方便,下文会成为“引用传递”(为了区分正确的引用传递,这里特意加了引号)。
如下图所示,我们的目的是传递X变量,于是我们创建了一个传参地址(临时地址变量),它存放了X变量的地址值,调用函数的时候给它这个传参地址,函数呢,则会再创建一个入参地址,是传参地址的一份拷贝。函数拿到了这个地址值,可以通过寻址拿到这个X变量,此时函数如果直接修改X变量可以认为是“本地修改”或者“永久修改”了这个变量的数值。
「举个生活中的例子,比如一个叫做“函数”的人想寻找一个叫做“X”的人,函数跑过来问知道X的我,我拿出地址簿,给他出示了X这个人的家庭地址,函数记性不太好,所以拿了一本本子把X的地址抄在了他自己的本子上。」
这个例子中,我的那个记着X的家庭地址的地址簿,就是传参地址;函数抄录了X地址的本子,就是入参地址;X的家庭地址,就对应了X变量的地址值。(哎,为什么讲的这么细节了?)
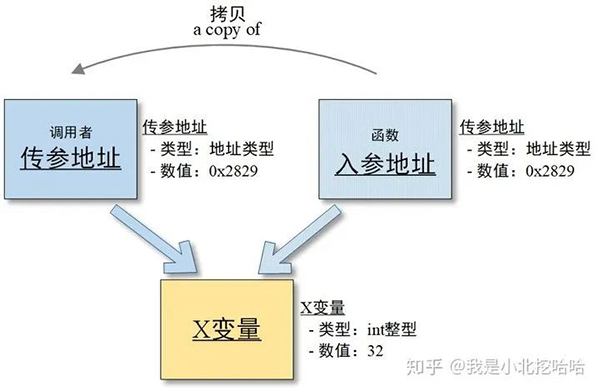
Golang的“引用传递”
话题似乎有点扯远了,拉回来,我们再来看看foo1()和foo2()。
foo1()和foo2()的区别确实在于值传递和引用传递,但是这个并不是本文介绍的中心。本文要介绍的已经在标题上写明了:闭包(closure)。
闭包(closure)
什么是闭包呢?摘用Wikipedia上的一句定义:
- a closure is a record storing a function together with an environment.
- 闭包是由函数和与其相关的引用环境组合而成的实体 。
因此闭包的核心就是:函数和环境。其实这里就已经可以回答本文题目的问题:闭包究竟包了什么?答案是:函数和环境。但是相信部分看官们到这里依然不清楚:什么函数?什么环境?
函数,指的是在闭包实际实现的时候,往往通过调用一个外部函数返回其内部函数来实现的。内部函数可能是内部实名函数、匿名函数或者一段lambda表达式。用户得到一个闭包,也等同于得到了这个内部函数,每次执行这个闭包就等同于执行内部函数。
环境,Wikipedia上说是与其(函数)相关的引用环境,可以说解释地很精准了。
具体地说,在实际中引用环境是指外部函数的环境,闭包保存/记录了它产生时的外部函数的所有环境。但是这段话对于尚未理解闭包的同学来说依旧是不友好的,听完还是懵懂的。这里尝试做个更实用性的解释:
- 如果外部函数的所有变量可见性都是local的,即生命周期在外部函数结束时也结束的,那么闭包的环境也是封闭的。
- 反之,那么闭包其实不再封闭,全局可见的变量的修改,也会对闭包内的这个变量造成影响。
跳回foo1()和foo2()的例子,正好来解释闭包的函数和环境。
func foo1(x *int) func() {
return func() {
*x = *x + 1
fmt.Printf("foo1 val = %d\n", *x)
}
}
func foo2(x int) func() {
return func() {
x = x + 1
fmt.Printf("foo1 val = %d\n", x)
}
}
// Q1第一组实验
x := 133
f1 := foo1(&x)
f2 := foo2(x)
f1()
f2()
f1()
f2()
// Q1第二组
x = 233
f1()
f2()
f1()
f2()
// Q1第三组
foo1(&x)()
foo2(x)()
foo1(&x)()
foo2(x)()
定义了x=133之后,我们获取得到了f1=foo1(&x)和f2=foo2(x)。这里f1\f2就是闭包的函数,也就是foo1()\foo2()的内部匿名函数;而闭包的环境即外部函数foo1()\foo2()的变量x(因为内部匿名函数引用到的相关变量只有x,因此这里简化为变量x)。
闭包的函数做的事情归纳为:1). 将环境的变量x自增1;2). 打印环境变量x。
闭包的环境则是其外部函数获取到的变量x。
因此Q1第一组实验的答案为:
f1() // foo1 val = 134
f2() // foo2 val = 134
f1() // foo1 val = 135
f2() // foo2 val = 135
这是因为闭包f1\f2都保存了x=133时的整个环境,每次调用闭包f1\f2都会执行一次自增+打印的内部匿名函数。因此第一次输出都是(133+1=)134,第二次输出都是(134+1=)135。
那么Q1第二组实验的答案呢?
f1() // foo1 val = 234
f2() // foo2 val = 136
f1() // foo1 val = 235
f2() // foo2 val = 137
有趣的事情发生了!f1的值居然发生了显著性的变化!通过这组实验,能够更好地解释其(函数)相关的引用环境其实就是产生这个闭包的时候的外部函数的环境,因此变量x的可见性和作用域也与外部函数相同,又因为foo1是“引用传递”,变量x的作用域不局限在foo1()中,因此当x发生变化的时候,闭包f1内部也变化了。这个也正好是"反之,那么闭包其实不再封闭,全局可见的变量的修改,也会对闭包内的这个变量造成影响"的证明。
Q1的第三组实验的答案:
foo1(&x)() // foo1 val = 236
foo2(x)() // foo2 val = 237
foo1(&x)() // foo1 val = 237
foo2(x)() // foo2 val = 238
foo2(x)() // foo2 val = 238
因为foo1()返回的闭包都会修改变量x的数值,因此调用foo1()()之后,变量x必然增加1。而foo2()返回的闭包仅仅修改其内部环境的变量x而对调用外部的变量x不影响,且每次调用foo2()返回的闭包是独立的,和其他调用foo2()的闭包不相关,因此最后两次的调用,打印的数值都是相同的;第一次调用和第二次调用foo2()发现打印出来的数值增加了1,是因为两次调用之间传入的x的数值分别是236和237,而不是说第二次在第一次基础上增加了1,这点需要补充说明。
3. case7:闭包的延迟绑定
hhh,是不是以为我会接着讲case3,居然先提到了case7,意不意外惊不惊喜!
废话不多说,看官们来瞅瞅下面调用f7()的时候分别会打印什么?
func foo7(x int) []func() {
var fs []func()
values := []int{1, 2, 3, 5}
for _, val := range values {
fs = append(fs, func() {
fmt.Printf("foo7 val = %d\n", x+val)
})
}
return fs
}
// Q4实验:
f7s := foo7(11)
for _, f7 := range f7s {
f7()
}
答案是:
foo7 val = 16
foo7 val = 16
foo7 val = 16
foo7 val = 16
是的,你没有看错,会打印4行,且都是16!是不是很惊喜!
相信已经有很多同学在网上看到过类似的case,并且也早已知道结果了,不清楚的同学们现在也看到答案了。嗯,这就是大名鼎鼎的闭包延迟绑定问题。网上的解释其实有很多了,这里尝试用之前对于闭包的环境的定义来解释这个现象:
“
闭包是一段函数和相关的引用环境的实体。case7的问题中,函数是打印变量val的值,引用环境是变量val。仅仅是这样的话,遍历到val=1的时候,记录的不应该是val=1的环境吗?
上文在闭包解释最后,还有一句话:闭包保存/记录了它产生时的外部函数的所有环境。如同普通变量/函数的定义和实际赋值/调用或者说执行,是两个阶段。闭包也是一样,for-loop内部仅仅是声明了一个闭包,foo7()返回的也仅仅是一段闭包的函数定义,只有在外部执行了f7()时才真正执行了闭包,此时才闭包内部的变量才会进行赋值的操作。哎,如果这么说的话,岂不是应该抛出异常吗?因为val是一个比foo7()生命周期更短的变量啊?
这就是闭包的神奇之处,它会保存相关引用的环境,也就是说,val这个变量在闭包内的生命周期得到了保证。因此在执行这个闭包的时候,会去外部环境寻找最新的数值!你是不是不相信?来来来,我们马上写个临时的case执行下分分钟就明白了:
- 临时的case:
func foo0() func() {
x := 1
f := func() {
fmt.Printf("foo0 val = %d\n", x)
}
x = 11
return f
}
foo0()() // 猜猜我会输出什么?
既然我说会在执行的时候去外部环境寻找最新的数值,那x的最新数值就是11呀,果然,最后输出的就是11。
以上就是我对于闭包的延迟绑定的通俗版本解释。:)
IV. case3~6:Go Routine的延迟绑定
case3、case4和case5不是闭包,case3只是遍历了内部的slice并且打印,case4是在遍历时通过协程调用了打印函数打印,case5也是在遍历slice时调用了内部匿名函数打印。
Q2的case3问题的答案先丢出来:
func foo3() {
values := []int{1, 2, 3, 5}
for _, val := range values {
fmt.Printf("foo3 val = %d\n", val)
}
}
foo3()
//foo3 val = 1a
//foo3 val = 2
//foo3 val = 3
//foo3 val = 5
中规中矩,遍历输出slice的内容:1,2,3,5。
Q2的case4问题的答案再丢出来:
func show(v interface{}) {
fmt.Printf("foo4 val = %v\n", v)
}
func foo4() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go show(val)
}
}
foo4()
//foo3 val = 2
//foo3 val = 3
//foo3 val = 1
//foo3 val = 5
嗯,因为Go Routine的执行顺序是随机并行的,因此执行多次foo4()输出的顺序不一行相同,但是一定打印了“1,2,3,5”各个元素。
最后是Q2的case5问题的答案:
func foo5() {
values := []int{1, 2, 3, 5}
for _, val := range values {
go func() {
fmt.Printf("foo5 val = %v\n", val)
}()
}
}
foo5()
//foo3 val = 5
//foo3 val = 5
//foo3 val = 5
//foo3 val = 5
居然都打印了5,惊不惊喜,意不意外?!相信看过子标题的你,一定不意外了(捂脸)。是的,接下来就要讲讲Go Routine的延迟绑定:
其实这个问题的本质同闭包的延迟绑定,或者说,这段匿名函数的对象就是闭包。在我们调用go func() { xxx }()的时候,只要没有真正开始执行这段代码,那它还只是一段函数声明。而在这段匿名函数被执行的时候,才是内部变量寻找真正赋值的时候。
在case5中,for-loop的遍历几乎是“瞬时”完成的,4个Go Routine真正被执行在其后。矛盾是不是产生了?这个时候for-loop结束了呀,val生命周期早已结束了,程序应该报错才对呀?
回忆上一章,是不是一个相同的情境?是的,这个匿名函数可不就是一个闭包吗?一切就解释通了:闭包真正被执行的时候,for-loop结束了,但是val的生命周期在闭包内部被延长了且被赋值到最新的数值5。
不知道各位看官是否好奇,既然说Go Routine执行的时候比for-loop慢,那如果我在遍历的时候增加sleep机制呢?于是设计了Q3实验:
var foo6Chan = make(chan int, 10)
func foo6() {
for val := range foo6Chan {
go func() {
fmt.Printf("foo6 val = %d\n", val)
}()
}
}
// Q3第一组实验
go foo6()
foo6Chan <- 1
foo6Chan <- 2
foo6Chan <- 3
foo6Chan <- 5
// Q3第二组实验
foo6Chan <- 11
time.Sleep(time.Duration(1) * time.Nanosecond)
foo6Chan <- 12
time.Sleep(time.Duration(1) * time.Nanosecond)
foo6Chan <- 13
time.Sleep(time.Duration(1) * time.Nanosecond)
foo6Chan <- 15
// Q3第三组实验
// 微秒
foo6Chan <- 21
time.Sleep(time.Duration(1) * time.Microsecond)
foo6Chan <- 22
time.Sleep(time.Duration(1) * time.Microsecond)
foo6Chan <- 23
time.Sleep(time.Duration(1) * time.Microsecond)
foo6Chan <- 25
time.Sleep(time.Duration(10) * time.Second)
// 毫秒
foo6Chan <- 31
time.Sleep(time.Duration(1) * time.Millisecond)
foo6Chan <- 32
time.Sleep(time.Duration(1) * time.Millisecond)
foo6Chan <- 33
time.Sleep(time.Duration(1) * time.Millisecond)
foo6Chan <- 35
time.Sleep(time.Duration(10) * time.Second)
// 秒
foo6Chan <- 41
time.Sleep(time.Duration(1) * time.Second)
foo6Chan <- 42
time.Sleep(time.Duration(1) * time.Second)
foo6Chan <- 43
time.Sleep(time.Duration(1) * time.Second)
foo6Chan <- 45
time.Sleep(time.Duration(10) * time.Second)
// 实验完毕,最后记得关闭channel
close(foo6Chan)
尝试执行了多次,第一组答案如下:
foo6 val = 5/3
foo6 val = 5
foo6 val = 5
foo6 val = 5
绝大部分时候执行出来都是5。
第二组答案如下:
foo6 val = 15/13/11/12
foo6 val = 15/13
foo6 val = 15
foo6 val = 15
绝大部分时候执行得到的都是15。
第三组答案如下:
// 微秒
foo6 val = 23/21
foo6 val = 23/22
foo6 val = 25/23
foo6 val = 25
// 毫秒
foo6 val = 31
foo6 val = 32
foo6 val = 33
foo6 val = 35
// 秒
foo6 val = 41
foo6 val = 42
foo6 val = 43
foo6 val = 45
毫秒和秒的两组非常确定,顺序输出。但是微妙就不一定了,有时候是顺序输出,大部分时候是随机输出如“22,22,23,25”或者“21,22,25,25”之类的。
可见,Go Routine的匿名函数从定义到执行,耗时时间在微妙上下。于是又增加了一个临时的case测试了其真正的耗时大约是多少。
- 又一个临时的case:
func foo8() {
for i := 1; i < 10; i++ {
curTime := time.Now().UnixNano()
go func(t1 int64) {
t2 := time.Now().UnixNano()
fmt.Printf("foo8 ts = %d us \n", t2-t1)
}(curTime)
}
}
foo8()
执行下来发现耗时在5微秒~60微秒之间不等。
但是,以上的实验数据都是从我的iMac本子上得到的,该本子的CPU是i7-7700K 4.2GHz;我又放在笔记本上(CPU为i5-8250U 1.6GHz 1.8GHz)运行了下,发现居然耗时是0微秒!起初我怀疑是时间精度的问题,于是把t1和t2时间都打印出来,精度是可以达到纳秒的。抱着仍旧不信的想法,重新运行了第三组实验,每一个都是顺序输出的!
好吧,回头再说我的iMac的问题。现在只需要记住一点:Go Routine的匿名函数的延迟绑定本质就是闭包,实际生成中注意下这种写法~
写在后面
最后,闭包是个常见的玩意儿,但是实际代码中不太建议使用,一不小心写了个内存泄漏查都查不到。特别是不要为了炫技故意写个闭包,实在没有必要。